Week 1: PyTorch의 기술적인 배경
PyTorch + NPU 온라인 모임 #1 | 2024-12-04
소개
이 강의는 PyTorch + NPU 랩의 첫 번째 온라인 모임으로, PyTorch의 기술적 배경을 다룹니다.
랩장은 리벨리온에서 SW를 개발하고 있으며, 컴파일러 연구/개발을 오랫동안 해왔습니다. 리벨리온 NPU를 PyTorch에 붙이는 일과 PyTorch Foundation에서 리벨리온을 대표하는 일을 하고 있고, PyTorch KR의 PyTorch Core SIG를 만들어 관심 있는 분들과 함께 커뮤니티 활동도 해볼 계획입니다.
랩 1기 목표
랩 차원의 목표로는 PyTorch internal에 관심 있는 사람들을 모으고, 함께 공부하고 성장하며, 공부한 결과를 강의자료로 정리하여 더 많은 사람들이 PyTorch internal을 쉽게 공부할 수 있도록 공유하는 것입니다. 개인적인 목표로는 공부한 내용을 바탕으로 리벨리온 NPU를 PyTorch에 더 잘 붙여보고, 많은 분들이 PyTorch upstream에 기여하여 한국이 PyTorch upstream에서 큰 지분을 가져갈 수 있기를 바랍니다.
ML Framework이란
ML Framework은 AI Ecosystem에서 다음과 같은 역할을 합니다:
- OS이자 - AI 가속기를 추상화된 computing resource로 제공
- Programming Language이자 - Model을 쉽게 작성할 수 있도록 API 제공
- Compiler - 작성된 모델을 computing resource로 mapping
이처럼 ML Framework에는 다양한 기술적인 background가 혼재되어 있습니다.
PyTorch, TensorFlow, JAX 등의 ML Framework은 모델을 기술하는 것에서 나아가 GPU와 같은 AI 가속기를 효과적으로 활용하는 것이 핵심입니다. 프로그래밍 언어적 성격으로 모델을 직접 작성하고 제공하며, 컴파일러 역할로 AI 가속기에 그대로 매핑하는 대신 트랜스포메이션 과정을 통해 하드웨어 타겟에 최적화합니다.
ML Framework의 발전은 이전의 훌륭한 연구들과 산업적 성과가 축적되어 만들어진 결과물입니다. 그 역사와 과정을 살펴보면 여러 기술적 흐름들이 있었고, 결국 이런 흐름들이 합쳐져서 우리가 지금 쓰고 있는 ML Framework이 되었습니다.
Q: PyTorch의 경우, ML 컴파일러의 이름이 있을까요?
컴파일러의 정의를 먼저 살펴봐야 합니다. PyTorch 1.x에도
torch.jit.trace등 컴파일러 유사 기능이 포함되어 있었으나, 당시에는 컴파일러 기능이 프레임워크의 중심이 아니었습니다. PyTorch 2.0에서는 Dynamo(torch.jit.trace를 대체), Inductor(본격적인 컴파일러), Triton(도메인 특화 언어)이 주요 ML 컴파일러 컴포넌트로 작동합니다.
오늘 다룰 주제들
이 강의에서는 ML Framework의 기술적 배경과 설계 공간을 다룹니다.
ML Framework의 배경 기술:
- Heterogeneous computing with GPU - Graphics에서 GPGPU로의 발전
- Graphics: OpenGL (1992), DirectX (1995)
- GPGPU: HLSL (2002), CUDA (2007), OpenCL (2008), HSA (2012)
- Supercomputing - BLAS, MPI 등 고성능 컴퓨팅 기술
- Fast multiplication - BLAS (1979), cuBLAS (2007), CUTLASS (2018)
- Distributed programming - MPI (1992)
- ML compiler
- XLA (Google), TensorRT (Nvidia), TVM (OctoAI), Glow (Meta), etc
- Numerical Computing for Data Science - NumPy로 대표되는 도구 생태계
- Matlab (1970s), R (1993), NumPy (2005)
설계 공간(Design Space):
- Two (or three) language problems
- Eager vs. graph mode: “define-and-run” vs. “define-by-run”
- Interpretation vs. JIT(Just in Time)/AOT(Ahead of Time) compilation
Convergence on PyTorch: 이 모든 기술이 PyTorch로 수렴하고 있는 흐름을 살펴봅니다.
Heterogeneous Computing with GPU
Heterogeneous Computing은 CPU와 GPU를 함께 활용하여 더 빠르게 계산할 수 있도록 해주는 시스템입니다. 일반적으로 CPU가 수행하던 계산 중 일부를 GPU에게 offloading하여 성능을 향상시키는 방식입니다.
ML Framework은 GPU와 같은 AI 가속기를 효과적으로 활용해야 하므로, CPU와 AI 가속기를 결합하여 사용하는 Heterogeneous Computing이 그 바탕이 되는 배경 기술입니다.
Graphics에서의 시작
이 기술의 시작점은 GUI, 컴퓨터 게임 등을 위한 Graphics입니다.
- OpenGL (1992) - 실리콘 그래픽스가 개발한 Graphics API로, 프로그래머가 그래픽스 연산을 소프트웨어적으로 프로그래밍할 수 있는 시작점이었습니다. 다만 OpenGL 자체는 상업적으로 큰 성공을 거두지는 못했습니다.
- DirectX (1995) - Microsoft가 개발한 Graphics API로, Windows PC의 보급과 함께 실질적인 업계 표준으로 자리잡았습니다. GPU의 성능 향상과 함께 주요 표준이 되었으며, Nvidia와 ATI(현재 AMD)의 성장을 촉진시킨 중요한 계기가 되었습니다.
Shader Programming의 등장 (2000년대 초)
2000년대 초에는 GPU 프로그래밍에 큰 변화를 가져온 Shader Programming이 등장했습니다. 이전에는 GPU가 fixed function만 수행할 수 있었지만, 이제 개발자가 GPU를 프로그래밍 가능한 디바이스로 활용할 수 있게 되었습니다.
- Nvidia GeForce 3 (2001) - 최초로 Shader Programming을 지원한 GPU로, 하드웨어적으로 셰이더 기능을 도입했습니다.
- DirectX 9와 HLSL - Microsoft는 DirectX 9(2002)에서 High-Level Shading Language(HLSL)를 정의하여 개발자들이 고급 언어로 GPU를 프로그래밍할 수 있도록 지원했습니다.
이 시기를 기점으로 GPU는 단순한 그래픽스 연산 디바이스에서 범용 연산에 적합한 프로그래머블한 디바이스로 진화했습니다.
GPGPU의 등장 (2007년)
2007년 Nvidia는 CUDA(Compute Unified Device Architecture)를 발표하며, GPGPU(General Purpose GPU)의 시대를 열었습니다.
- CUDA는 GPU를 위한 일반적인 parallel programming model로, 초기에는 High-Performance Computing(HPC) 시장을 타겟으로 했습니다. GPU의 성능이 슈퍼컴퓨터 수준에 가까워지면서, 이를 일반 개발자들이 활용할 수 있도록 CUDA를 도입한 것입니다.
- Deep learning의 등장과 함께 AI 가속기를 위한 programming model로 진화했습니다.
이후 다른 플랫폼들도 등장했습니다:
- OpenCL (2008) - Apple이 주도
- HSA (2012) - AMD/ARM이 주도
그러나 OpenCL과 HSA는 상용화에서 한계를 보였고, CUDA가 사실상 표준으로 자리잡았습니다. 오늘날 PyTorch와 같은 ML Framework 내부에서도 CUDA 기반의 API가 광범위하게 사용되고 있으며, 많은 후발 주자들이 이를 기반으로 비슷한 구조를 구축하고 있습니다.
Supercomputing
슈퍼컴퓨팅은 엄청나게 복잡한 계산을 처리하기 위한 고성능 컴퓨팅 기술입니다. 최근에는 머신러닝이 대표적인 예시로 떠오르고 있지만, 20년 전만 해도 주로 물리학 시뮬레이션, 천문학, 기후 모델링, 로켓 개발, 핵폭탄 연구 등 과학 연구와 시뮬레이션 분야에서 사용되었습니다. 미국의 내셔널 랩(National Lab)에서는 이러한 슈퍼컴퓨터를 활용해 복잡한 과학적, 기술적 문제를 해결하는 데 주력하고 있습니다.
슈퍼컴퓨팅과 인터넷 서비스의 차이
슈퍼컴퓨팅은 많은 수의 컴퓨터를 네트워크로 연결해 하나의 큰 계산을 분산 처리하는 방식으로 작동합니다. 구글의 데이터센터나 클라우드 기술도 유사한 구조를 가지고 있지만, 본질적인 차이가 존재합니다:
- 인터넷 서비스는 독립적이고 간단한 계산을 대량으로 처리하는 데 중점을 둡니다.
- 슈퍼컴퓨팅은 하나의 거대한 계산을 여러 컴퓨터에서 나누어 처리하며, 모든 작업이 연결되어 있습니다. 따라서 작업 중 하나라도 오류가 발생하면 전체 계산이 망가질 수 있어 “Fault”를 어떻게 처리하느냐가 관건입니다.
머신러닝의 경우에도 인퍼런스는 독립적인 작업이 많지만, 대규모 분산 학습에서는 하나의 작업이 매우 크기 때문에 fault 처리가 더욱 중요해집니다.
병렬/분산 프로그래밍 모델
슈퍼컴퓨팅의 발전과 함께 다양한 병렬 및 분산 프로그래밍 모델이 등장했습니다:
- 개념적인 모델 - SIMD, SPMD, MIMD
- 구현 표준 - MPI, OpenMP
특히 MPI(Message Passing Interface)는 PyTorch에서 구현된 분산 프로그래밍 모델의 기반이 되기도 합니다.
Matrix Multiplication
슈퍼컴퓨팅에서 가장 중요한 요소 중 하나는 Matrix Multiplication입니다. 과학에서 다루는 많은 자연 현상들이 선형대수로 표현되며, 선형대수의 가장 중요한 개념들은 결국 matrix multiplication으로 귀결됩니다.
매트릭스 곱셈의 연산량은 매트릭스 크기에 따라 N³에 비례하기 때문에, 이를 얼마나 빠르게 처리할 수 있는지가 전체 시스템의 성능에 큰 영향을 미칩니다.
최적화 기술:
- Algorithmic efficiency 측면: Strassen algorithm, DeepMind의 AlphaTensor 등
표준 라이브러리 BLAS
- BLAS (Basic Linear Algebra Subprograms, 1979) - 다양한 linear algebra 문제에 적용할 수 있는 low-level API로, Matrix multiplication을 위한 GEMM(General Matrix Multiply)을 포함합니다.
- 각 HW vendor들은 자사 하드웨어에 최적화된 BLAS 구현을 출시합니다:
- Nvidia: cuBLAS (2007, closed-source), CUTLASS (2018, 오픈소스) - cuBLAS는 클로즈드 소스로 제공되지만, CUTLASS는 오픈소스 라이브러리로 누구나 접근 가능합니다.
ML Compiler
ML Compiler는 정적인 graph로 전환된 ML model을 특정 hardware에 맞게 최적화해주는 컴파일러입니다.
ML Framework으로 개발자들이 표현한 model은 대부분 “동적”입니다. ML compiler를 적용하기 위해서는:
- 동적으로 표현된 model을 특정한 “정적” model로 고정하고
- 이를 ML compiler가 이해할 수 있는 format으로 전환하여
- 최종적으로 HW가 실행할 수 있는 binary를 생성합니다.
On-Device AI에서의 활용
서버에서 GPU로 훈련된 모델을 On-Device AI 가속기에서 수행하기 위해 많이 쓰이며, Qualcomm Snapdragon, Samsung Exynos, Google Tensor 등이 대표적입니다.
서버에서의 활용 확대
서버에서도 점점 활성화되고 있는 추세입니다:
| 하드웨어 | 프레임워크 | 컴파일러 |
|---|---|---|
| Google TPU | TensorFlow, JAX | XLA |
| Nvidia GPU | TensorFlow, PyTorch | TensorRT |
| Rebellions NPU | TensorFlow, PyTorch | RBLN Compiler |
PyTorch 2.0의 등장도 이러한 흐름 위에 있습니다.
PyTorch에서의 ML Compiler
PyTorch 1.x에서도 JIT Trace가 모델을 정적 형태로 변환해주는 역할을 했지만, 본격적인 ML 컴파일러로서의 역할은 제한적이었습니다.
PyTorch 2.0에서는 ML 컴파일러 기능이 대폭 강화되었습니다:
- Dynamo - JIT Trace를 대체하는 컴포넌트로, 컴파일러와 유사한 역할 수행
- Inductor - 본격적인 ML 컴파일러로, 모델 최적화 및 하드웨어 실행 효율화 담당
- Triton - 도메인 특화 언어(DSL)로, GPU를 위한 커널 최적화 작업에 활용
Numerical Computing for Data Science
Data science는 통계, 컴퓨터 과학, 수학 등의 도구를 활용하여 데이터를 분석하고 대상을 이해하는 융합 학문입니다. 많은 과학자/엔지니어들이 업무의 일부로 자연스럽게 data scientist 역할을 수행합니다.
Data Scientist가 선호하는 도구의 특성
Data scientist들은 특정 프로그래밍 언어 자체보다는, 이미 존재하는 데이터를 손쉽게 가공하고 필요한 정보를 얻어내는 데 더 관심을 둡니다. 그래서 다음과 같은 특성을 갖춘 도구를 선호합니다:
- Predefined math functions - 복잡한 수학 함수를 직접 구현하는 대신 활용할 수 있는, 미리 정의된 수학 함수들
- Interactive mode - 긴 코드를 작성하고 실행하는 대신, 데이터를 즉시 처리하고 결과를 확인하는 대화형 작업 방식
- Visualization - 시각화 도구
NumPy의 등장과 Python의 부상
SAS (1966), SPSS (1968), Matlab (1970s), R (1993) 등이 선구적인 역할을 했으나, NumPy (2005)의 등장과 함께 Python이 대세로 자리잡았습니다. SciPy, Matplotlib, pandas, scikit-learn 등의 생태계가 형성되었고, Jupyter의 등장으로 더욱 많은 사람들이 쉽게 접근할 수 있게 되었습니다.
ML도 사용성 측면에서 같은 추세를 보이고 있습니다. NumPy는 TensorFlow와 PyTorch의 API 설계와도 밀접한 관련이 있으며, 특히 텐서 연산 처리 방식에서 공통점이 많습니다.
흥미로운 점은, NumPy가 PyTorch의 개발에 영향을 준 뒤, 최근에는 NumPy 창시자의 회사가 PyTorch 2.0에 많은 기여를 하고 있다는 것입니다. 이제 PyTorch는 NumPy 코드를 네이티브로 지원하며, NumPy 코드를 수정 없이 작성하면 Dynamo와 Inductor를 통해 바이트코드로 동적 변환 후 CUDA 코드로 컴파일하여 GPU에서 실행할 수 있습니다. 이 기술은 현재 PyTorch의 upstream에 포함되어 있습니다.
Two (or More) Language Problems
Python은 사용하기 쉽지만 성능 문제가 있습니다. 이를 해결하기 위한 세 가지 접근법이 있습니다:
해결책 #1: 고성능 Python compiler를 개발
- Cython의 성능이 점점 좋아지고 있으며, PyPy같은 대안 프로젝트도 존재합니다.
해결책 #2: Python 언어를 증강
- Modular의 Mojo 프로젝트가 대표적인 시도입니다.
해결책 #3: 다른 언어로 작성된 모듈과 binding
- pybind11을 통한 Python + C++11 결합이 대표적이며, NumPy와 PyTorch가 이 방식을 채택하고 있습니다.
- 추가로 AI 가속기로 offloading하여 성능을 극대화합니다.
Eager vs. Graph Mode
Eager mode
API 호출 시 operator가 곧바로 실행됩니다.
Graph mode
API 호출 시 graph를 점진적으로 생성합니다. Graph가 완성되면 목적에 맞게 변환을 적용한 후 수행합니다:
- Back propagation을 위한 backward graph 생성
- 성능 향상을 위한 최적화 수행 (예: op fusion)
Eager mode와 graph mode를 명확히 구분할 수 있지만, 실제로는 두 가지가 동시에 작동하는 경우가 많습니다. 대표적인 예가 autograd입니다. Forward 단계에서는 각 연산이 eager mode로 즉시 실행되지만, autograd를 켜면 실행과 동시에 backward 계산을 위한 graph가 기록됩니다. Backward 계산은 forward 계산과 다르기 때문에 별도의 backward graph가 필요하며, backward propagation은 이 그래프를 따라 수행됩니다. 즉 forward에서는 eager mode가, backward에서는 graph mode가 작동하는 셈입니다.
Graph mode를 접근하는 방법
TF1의 접근법 (define-and-run)
- 개발자에게 명시적으로 graph를 생성하도록 요구
PyTorch, TF2, JAX의 접근법 (define-by-run)
- 개발자는 eager mode를 가정하고 model을 작성
- 개발자가 작성한 eager mode 기반 model로부터 graph를 추출
TF2와 PyTorch는 Eager, Graph 모두 가능합니다. JAX도 기본적으로는 eager로 실행되지만, jax.jit으로 감싼 함수는 트레이싱을 거쳐 그래프로 컴파일됩니다.
TF1 vs. PyTorch 코드 비교
TF1
a = tf.constant([[3, 3]])
b = tf.constant([[2], [2]])
c = tf.matmul(a, b)
with tf.Session() as sess:
print(sess.run(c))TensorFlow 1.x에서는 tf.constant와 tf.matmul 같은 연산자들이 실제 계산을 수행하지 않고, 계산 과정을 그래프로 만듭니다. c를 평가하기 전까지는 실제 값을 알 수 없으며, Session을 생성한 뒤 sess.run(c)(또는 c.eval())를 호출해야 비로소 계산 결과를 얻을 수 있습니다.
PyTorch
x1 = torch.rand(2, 3)
x2 = torch.rand(2, 3)
y = x1 + x2
print(y)PyTorch의 eager mode에서는 각 줄의 연산이 즉시 수행되며, y는 +가 실행된 결과를 바로 가지고 있습니다. 별도의 그래프 실행 과정이 필요 없으며, 코드 한 줄 한 줄이 실시간으로 계산됩니다.
Graph Capture: TF2와 PyTorch 비교
그래프 모드에서는 어떻게 그래프를 뽑아낼 것인가가 핵심 문제입니다. TF1은 프로그래머들에게 명시적으로 그래프를 그려달라고 요청했지만, TF2나 PyTorch는 eager 모드로 모델을 만들어주면 거기서 자체적으로 그래프를 뽑아내는 방식을 사용합니다.
TF2
@tf.function
def foo(x, y):
a = tf.sin(x)
b = tf.cos(y)
return a + b
x = tf.random.uniform((3, 4))
y = tf.random.uniform((3, 4))
foo(x, y)TF2는 기본이 eager 모드이며, @tf.function 데코레이터를 붙인 함수를 처음 호출하는 시점에 함수 내부의 연산들이 트레이싱되어 그래프로 캡처됩니다. 개발자는 eager 스타일로 코드를 작성하고, 프레임워크가 그래프 추출을 담당하는 define-by-run 구조입니다.
PyTorch 1 & 2
def foo(x, y):
a = torch.sin(x)
b = torch.cos(y)
return a + b
x = torch.rand(3, 4)
y = torch.rand(3, 4)
# PyTorch 1
traced_foo = torch.jit.trace(foo, (x, y))
traced_foo(x, y)
# PyTorch 2
optimized_foo = torch.compile(foo)
optimized_foo(x, y)PyTorch 1과 2는 모두 100% eager 모드를 지원합니다. PyTorch 1에서는 torch.jit.trace를 이용해 trace를 뽑아 그래프 모드를 수행했고, PyTorch 2에서는 이를 더 범용적으로 사용할 수 있는 torch.compile을 도입했습니다. 특히 trace를 뽑아내는 기능은 Dynamo라는 기술을 통해 더 체계적으로 대응하고 있습니다.
This is not new
Eager mode에서 graph를 추출하는 기법에는 오랜 역사가 있습니다:
- Trace scheduling for VLIW compiler (1981)
- Out-Of-Order Execution in Pentium Pro (1995)
- Trace cache (1996)
- Chrome V8 Engine (2008)

Fisher, J.A. “Trace Scheduling: A Technique for Global Microcode Compaction” IEEE Trans. on Computers, 1981
PGO(Profile-Guided Optimization)는 프로그램의 동적인 특성을 컴파일 타임에 활용해 최적화를 수행하는 더 넓은 개념이며, 트레이스 스케줄링은 PGO에서 사용하는 특정 기법 중 하나입니다. 동적인 실행 경로(Trace)를 추출하여 브랜치 예측을 통해 자주 실행되는 경로를 추적하고, 이 경로에 최적화된 스케줄링을 수행합니다. 양질의 프로파일 데이터가 필요하며, 올바른 트레이스를 만들어 롤백 없이 효율적인 성능을 제공하는 것이 핵심입니다.
Convergence on PyTorch
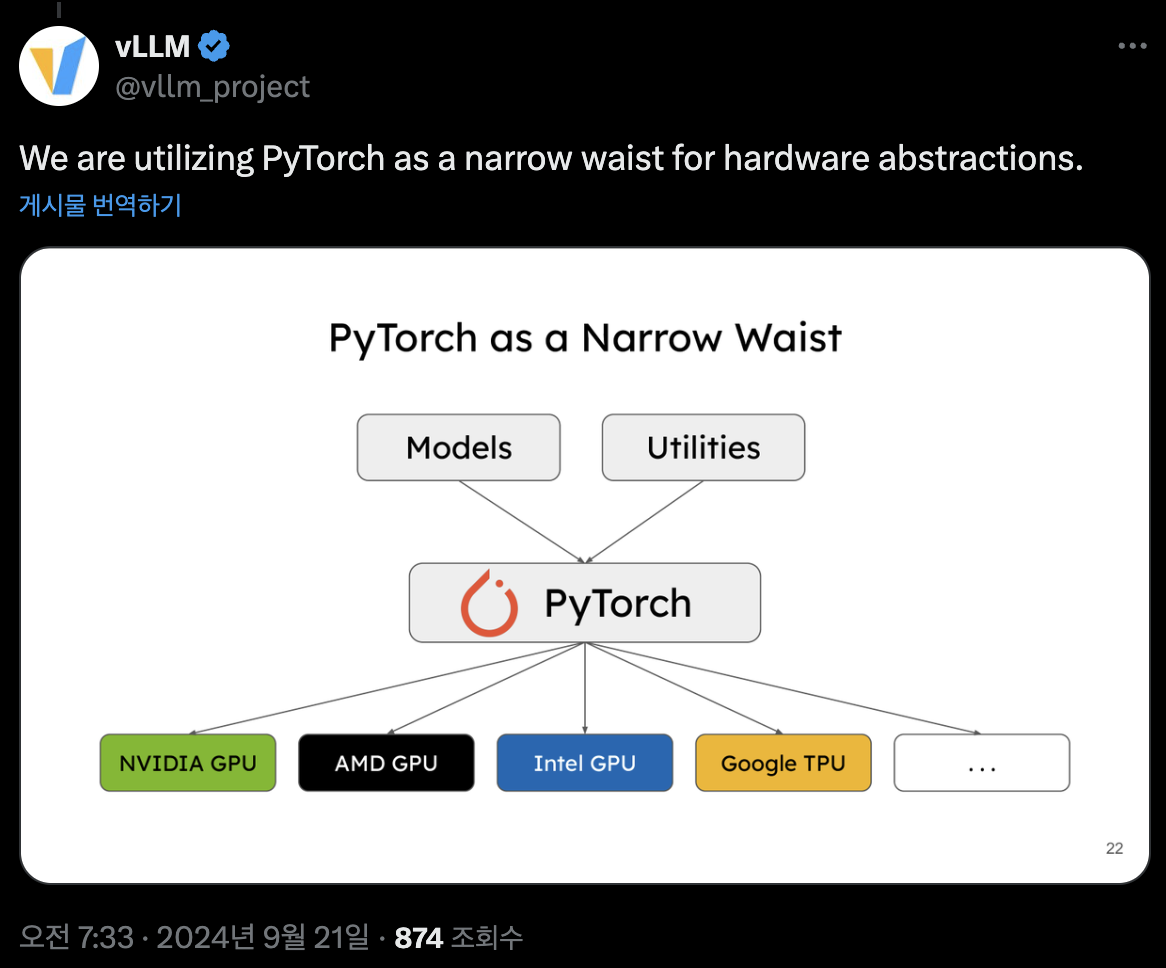
ML Framework에는 방대한 양의 배경 기술이 있지만, 시간이 흘러감에 따라 점점 더 잘 정리되어 “이런 문제는 이렇게 풀면 좋겠다”라는 것이 5년, 10년 전보다 훨씬 더 잘 정립되어 있습니다. 그리고 그런 것들이 잘 통합되어 있는 형태가 바로 PyTorch입니다.
대표적인 예로 vLLM이 있습니다. vLLM은 PyTorch 위에 올라가는 기술로, 하드웨어를 붙이기 위해 “일단 PyTorch에 잘 붙여봐라”라는 구체적인 요구 조건을 내걸었습니다. 하드웨어 종속적인 부분들은 먼저 PyTorch에 잘 통합하고, 그 다음에 제공하라는 정식 정책을 수립한 것입니다. 이 ML 에코시스템에서 다양한 하드웨어를 잘 추상화하고 단순화시키는 “Narrow Waist” 역할로 PyTorch가 점점 더 보편적으로 받아들여지고 있습니다.
PyTorch 2.0
PyTorch 2.0은 PyTorch 1.0의 특성을 거의 모두 계승(inherit)하면서, 앞서 다룬 여러 기술적 배경을 종합하여 구현된 프레임워크입니다.
핵심 특징:
- NumPy-like experience - 텐서 구조, 사전 정의된 수학 함수, 대화형 환경, Jupyter Notebook 호환성
- Heterogeneous computing as an underneath foundation - 다양한 하드웨어에서 효율적으로 동작
- MPI-like distributed programming model - 분산 프로그래밍 기본 지원
- Integration with compute libraries / ML compiler - PyTorch 1.0부터 Eager mode에서는 컴퓨팅 라이브러리를 사용하고, PyTorch 2.0에서는 Graph mode에서 ML 컴파일러와의 통합을 핵심 과제로 다루고 있음
- Three language layers: Python → C++ → kernel language (예: CUDA, Triton) - 단순한 2개 언어가 아니라 제3 랭귀지 또는 멀티 랭귀지 솔루션. 스크립팅은 Python으로 이루어지지만, 하위 레벨에서는 성능 최적화를 위해 C++로 전환되며, GPU/TPU/NPU 등의 하드웨어에서는 커널 레벨의 최적화 성능을 제공
- Define-by-run with graph capturing via TorchDynamo - Eager mode 중심으로 Graph mode를 부드럽게 지원
- Support both training and inference - Graph mode(컴파일) 경로가 inference뿐 아니라 training까지 지원하게 된 것이 PyTorch 2.0에서 가장 크게 변화한 부분
Backend Integration Points
다양한 하드웨어와 원활히 연결될 수 있도록 통합 포인트를 잘 정의하고 있습니다:
| Mode | Integration |
|---|---|
| Eager mode | As a new dispatch target |
| Graph mode (JIT & AOT) | As a backend to TorchDynamo |
| Graph mode (codegen) | As a backend to Inductor |
Q&A
TorchScript와 Python/C++ 관계
Q: TorchScript는 Python과 C++ 사이에 위치해 있다고 봐도 되나요?
그렇게 보기는 어렵습니다. TorchScript는 PyTorch에서 그래프 모드를 지원하기 위한 기술 중 하나로 보는 것이 더 적절합니다.
CUDA와 Triton의 차이점
Q: CUDA와 Triton은 어떻게 다른가요?
- 라이선스: CUDA는 proprietary, Triton은 오픈소스
- 설계 목적: CUDA는 스레드 단위의 fine-grained 처리, Triton은 코스 그레인한 데이터 블록 단위 처리
- 프로그래밍 모델: CUDA는 PTX/SASS 기반, Triton은 Python 데코레이터 형태의 API 제공
- 최적화 방식: Triton은 컴파일러가 복잡한 최적화를 처리하는 전략 채택
Triton은 단순한 Python API가 아닌, Python 신택스를 사용한 도메인 특화 언어(DSL)로 보는 것이 더 정확합니다. 원래 C 바인딩도 있었으나 현재는 Python 바인딩이 주로 사용됩니다. PyTorch 2.0에서 기본으로 채택한 커널 프로그래밍 언어로 이해할 수 있으며, “PyTorch용 compute shader”라고 부를 수도 있습니다.