Week 7: CPU / GPU / NPU
PyTorch + NPU 온라인 모임 #7 | 2025-02-12
소개
지금까지의 강의는 주로 소프트웨어적인 측면(PyTorch, 컴파일러, 모델 최적화 등)을 다뤘습니다. 이번 시간은 시리즈 전체에서 처음으로 하드웨어에 초점을 맞추는 강의이며, 다음 주에는 그동안 다룬 내용들을 실무와 연결지으며 시리즈를 마무리할 예정입니다.
오늘의 주제는 CPU, GPU, NPU가 어떻게 다른가입니다. “GPU가 병렬 처리에 좋다”는 수준을 넘어, 프로세서 설계 철학의 차이를 이해하는 것이 목표입니다. Latency hiding이라는 공통 문제를 CPU, GPU, NPU가 각각 어떤 방식으로 접근하는지를 추적하면, 왜 NPU가 GPU와 다른 프로그래밍 모델을 요구하는지 자연스럽게 이해할 수 있습니다.
디테일로 들어가기 전에 한 가지 짚어둘 점이 있습니다. 프로세서의 세계는 생각보다 훨씬 다양합니다. 같은 종류의 프로세서 안에서도 여러 접근법이 공존하고, ISCA·MICRO·HPCA 같은 컴퓨터 아키텍처 학회에서는 매년 새로운 제안들이 쏟아져 나옵니다. 따라서 이 강의에서 다루는 CPU/GPU/NPU의 구분은 절대적인 것이 아니라, 설계 철학을 이해하기 위한 하나의 큰 틀로 받아들이는 것이 좋습니다.
강의 흐름은 다음과 같습니다. 먼저 프로세서의 기본 구조와 설계 철학을 짚고, Latency와 Throughput 개념을 정리합니다. 이어서 Instruction-level pipelining부터 시작하여 Loop-level pipelining(OOO Processor와 VLIW), 그리고 Thread-level pipelining(Multi-core, GPU, NPU)까지 점진적으로 확장해 나갑니다.
Processor Stack: 개발자에서 Datapath까지
프로세서의 동작을 이해하려면, 개발자가 작성한 코드가 실제 하드웨어에서 실행되기까지 거치는 계층 구조를 먼저 파악해야 합니다. 컴퓨터라는 큰 세계는 맨 밑의 트랜지스터부터 개발자가 바라보는 프로그래밍 언어까지 한 번에 직접 연결되어 있는 것이 아니라, 그 사이에 여러 단계의 추상화 레이어를 거치도록 구성되어 있습니다.


이 스택에서 Programming Language와 Compiler는 소프트웨어 영역에 해당하고, ISA(Instruction Set Architecture)와 Control Logic, Datapath는 하드웨어 영역에 해당합니다. 특히 Control Logic과 Datapath를 합쳐서 Microarchitecture라고 부릅니다.
프로세서 설계의 핵심 질문
다양한 프로세서와 접근 방식이 존재하지만, 그 모든 것을 관통하는 질문은 하나입니다. 바로 “맨 밑에 있는 하드웨어가 개발자에게 어떻게 노출되는가?”입니다.
성능은 궁극적으로 맨 밑에 있는 하드웨어(Datapath)에서 결정됩니다. 그러나 트랜지스터 단위는 너무 낮은 수준이고, Datapath의 모든 디테일을 그대로 개발자에게 노출할 수도 없습니다. 결국 어딘가에서는 체계적으로 추상화가 이루어져 개발자가 이해할 수 있는 형태로 정리되어야 하는데, 그 추상화가 어느 단계에서 이루어지는가가 프로세서 디자인에서 가장 중요한 질문입니다.
추상화 수준에 따른 세 가지 접근 방식
이 질문에 대한 답은 크게 세 가지 접근 방식으로 나뉘며, 이들은 두 개의 큰 관점으로 묶어볼 수 있습니다. 위 그림의 우측에 있는 ①②③ 화살표가 각 접근 방식이 추상화를 어느 레이어까지 끌어올리는지를 보여줍니다.
관점 A: 개발자가 HW Detail을 알 필요가 없게. 추상화의 무게를 하드웨어 내부 또는 컴파일러에 두어, 개발자는 단순한 ISA만 보고 코드를 작성하면 되도록 합니다.
- Microarchitecture 수준의 최적화에 의존 (그림의 ①: Control Logic까지 추상화): 하드웨어의 복잡성을 하드웨어 내부에서 모두 추상화하고, 개발자에게는 간단한 ISA만 노출합니다. 파이프라이닝, 분기 예측, 캐시 등 Microarchitecture 수준의 최적화에 성능을 맡기는 방식입니다.
- Compiler 수준의 최적화에 의존 (그림의 ②: Compiler까지 추상화): 하드웨어의 복잡성은 그대로 노출하되, 그것을 사용 가능한 형태로 추상화하는 일은 컴파일러가 수행합니다. 프로세서와 컴파일러를 짝으로 함께 설계하는 접근입니다.
관점 B: 개발자가 HW 특성을 고려하여 짤 수 있도록. 결국 최적의 결정은 개발자가 내려야 한다는 철학에 기반합니다.
- 최적화 목적에 맞는 Programming Model 제공 (그림의 ③: Developer까지 노출): Datapath의 중요한 특성을 개발자에게 직접 노출하고, 그 디테일을 잘 다룰 수 있는 프로그래밍 모델을 함께 제공하여 개발자가 하드웨어 특성을 고려하며 코드를 작성하도록 지원합니다.
이 세 가지 접근 방식의 차이가 바로 CPU, GPU, NPU의 설계 철학 차이로 이어집니다.
무어의 법칙과 ISA/Microarchitecture의 분리
그렇다면 한 가지 자연스러운 질문이 생깁니다. 왜 이렇게 추상화 레이어가 많이 생기게 되었을까요? 특히 하드웨어 단에서, 보통 프로세서를 떠올리면 ISA(Instruction Set Architecture)로 소프트웨어에 노출되는 것을 생각하지만, 그 밑에 있는 Datapath와 ISA가 왜 분리되어 있는지 짚어볼 만합니다.
그 배경에는 무어의 법칙이 있습니다. 무어의 법칙이 활발히 작동하던 시절에는 트랜지스터 수가 18개월마다 두 배씩 늘어났고, 그렇게 늘어난 트랜지스터로 더 많은 컴포넌트를 집적해 프로세서가 점점 더 많은 일을 처리하도록 만들 수 있었습니다. 그 결과 하드웨어, 특히 Datapath는 세대마다 점점 더 복잡해졌습니다.
이 복잡해진 Datapath의 모든 디테일을 그대로 소프트웨어에 노출하는 것은 비현실적이었습니다. 노출해야 할 정보의 양이 너무 많아질 뿐 아니라, 세대가 바뀔 때마다 소프트웨어가 같이 바뀌어야 하기 때문입니다. 그래서 자연스럽게 하드웨어 디테일 자체와 소프트웨어가 그것을 활용하는 방식이라는 두 단계가 분리되기 시작했습니다.
이렇게 분리된 결과, ISA는 소프트웨어가 바라보는 안정적인 인터페이스로 유지되고, ISA 아래의 하드웨어 디테일(즉 Control Logic + Datapath를 묶은 Microarchitecture)은 세대마다 자유롭게 변경할 수 있게 되었습니다. Microarchitecture라는 용어는 컴퓨터 아키텍처나 컴파일러 분야에서는 익숙한 개념이지만, 상위 애플리케이션 레이어에서 일하는 분들에게는 조금 생소할 수 있습니다. 그냥 “ISA 아래에 있는 하드웨어 디테일” 정도로 이해해도 충분합니다.
Latency, Throughput, 그리고 Latency Hiding
이번 강의에서 결국 비교하고 싶은 것은 NPU가 GPU와 어떻게 다른가입니다. 그러나 그 차이를 한 번에 설명하기보다는, 다양한 하드웨어를 Latency Hiding이라는 공통 측면에서 비교하면서 점진적으로 빌드업해 나가는 편이 훨씬 이해하기 쉽습니다. 그래서 본격적인 비교에 앞서, Latency Hiding을 이야기할 때 빠지지 않는 두 가지 기본 개념(Latency와 Throughput)을 먼저 정리하고 넘어갑니다.
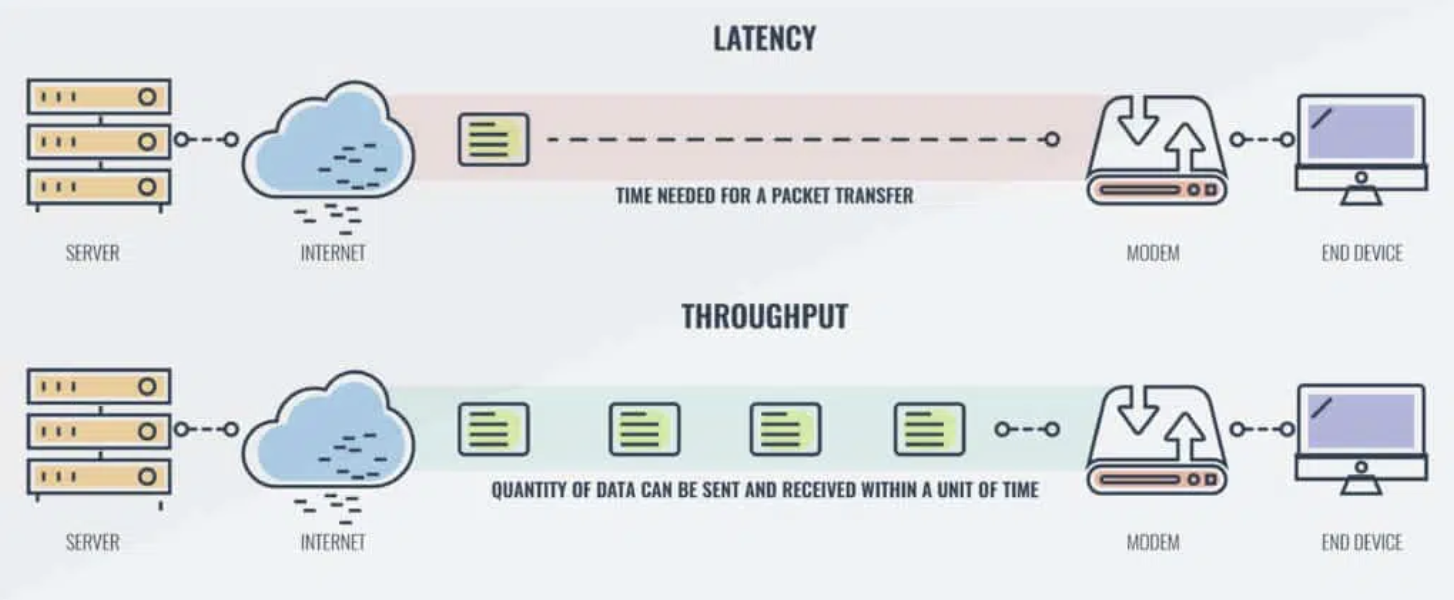
- Latency: 하나의 작업을 완료하는 데 걸리는 시간.
- Throughput: 단위 시간당 처리되는 작업의 양, 즉 얼마나 빠른 속도로 작업이 처리되는가.
직관적으로 보면 하나의 작업을 처리하는 데 걸리는 시간(Latency)이 짧을수록 단위 시간당 처리량(Throughput)이 늘어나는 것은 당연합니다. 단일 작업만 처리하는 경우라면 두 값은 거의 일대일로 연결되어 있죠. 그러나 항상 그렇지는 않습니다.
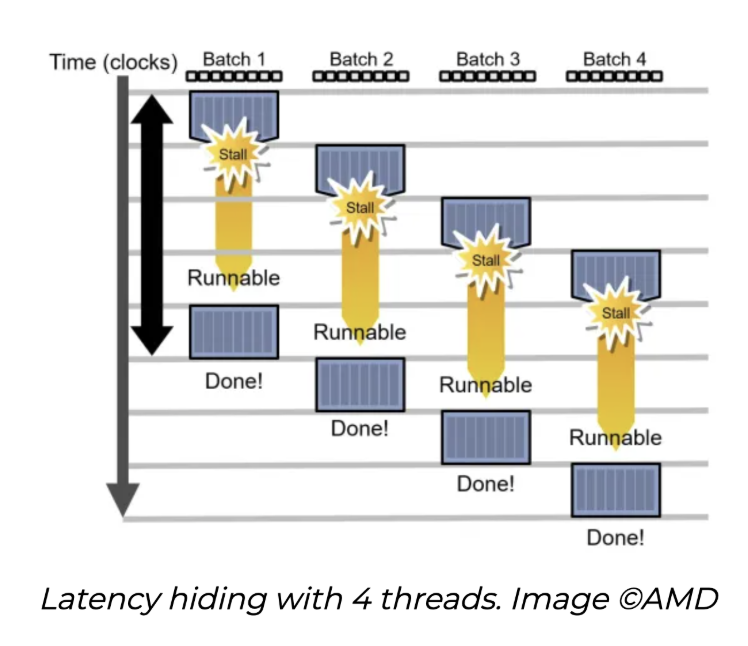
Latency Hiding & Parallelism


위 그림은 같은 길이의 작업이라도 처리 방식에 따라 Throughput이 어떻게 달라지는지를 보여줍니다.
- 단일 작업 처리 (위): 한 번에 하나의 작업밖에 처리할 수 없는 상황입니다. 이 경우 하나의 작업을 끝내는 데 걸리는 시간(Latency)이 그대로 Throughput에 직접적인 영향을 줍니다.
- 동시 작업 처리 (아래): 여러 작업을 동시에 처리할 수 있는 상황입니다. 이때는 개별 작업의 Latency 자체보다, 얼마나 빠르게 다음 작업을 새로 시작할 수 있는가가 Throughput을 결정합니다.
물론 이렇게 동시 처리가 가능하려면, 한 작업이 끝나기 전에 다른 작업을 시작할 수 있어야 합니다. 즉 작업 간 의존성이 없어야 합니다. 이 조건만 만족된다면, 개별 작업의 Latency가 길어도 Throughput은 충분히 높일 수 있습니다.
이 간극, 즉 Latency와 Throughput이 항상 직접적으로 연결되어 있지는 않다는 사실을 활용하는 것이 바로 Latency Hiding입니다. 이제 이 Latency Hiding을 통해 Throughput을 끌어올리는 여러 마이크로아키텍처 기법들(Instruction-level / Loop-level / Thread-level pipelining)을 차례로 살펴봅니다.
Instruction-Level Pipelining
Latency Hiding의 가장 기본적인 형태는 명령어 수준의 파이프라이닝입니다. 이 절에서는 교과서에서 RISC의 대표 사례로 자주 등장하는 고전적인 5-Stage RISC Pipeline(MIPS·RISC-V 교과서의 표준 예제)을 가져와 비교 기준으로 사용합니다. 프로그램은 결국 명령어들의 나열이고, 그 명령어가 프로세서에서 실제 수행되기 위해 거치는 단계를 다섯 개로 나눈 것입니다.
- IF (Instruction Fetch): 인스트럭션 메모리에서 명령어를 가져옵니다.
- ID (Instruction Decode): 가져온 명령어를 해석해 하드웨어가 무엇을 해야 할지 파악합니다.
- EX (Execute): 디코드된 정보를 가지고 실제 연산을 수행합니다.
- ME (Memory Access): 필요한 경우 데이터 메모리에 접근합니다.
- W (Write Back): 최종 결과를 레지스터에 다시 씁니다.
이 5단계를 (1) 순차적으로 실행할 때와 (2) 파이프라인으로 겹쳐서 실행할 때를 같은 cycle 범위에서 비교해 보겠습니다.
순차적 실행의 한계
컴퓨터 프로그램이 프로세서에서 실제로 수행된다는 것은, 결국 명령어들이 차례대로 수행되는 것이라고 볼 수 있습니다. 그리고 하나의 명령어가 수행되는 데 걸리는 시간이 곧 그 명령어의 Latency입니다.
이 Latency는 모든 명령어가 동일한 것이 아닙니다. 명령어마다 다를 수 있고, 한 사이클에 끝나는 경우도 있고 여러 사이클이 걸리는 경우도 있으며, 메모리 접근처럼 굉장히 긴 시간이 걸리는 경우도 있습니다.
순차 실행 방식에서는 한 명령어의 다섯 단계가 모두 끝난 후에야 다음 명령어를 시작할 수 있습니다. 각 명령어의 Latency가 그대로 처리량에 누적됩니다.
| Cycle | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| Inst 1 | IF | ID | EX | ME | W | ||||
| Inst 2 | IF | ID | EX | ME |
9 cycle 동안 단 1개의 명령어만 완전히 끝나고, 두 번째 명령어는 아직 마지막 W 스테이지를 남겨둔 상태입니다. 한 명령어가 완전히 끝나야 다음을 시작할 수 있으므로 Throughput이 심하게 제한됩니다.
파이프라이닝을 통한 Throughput 향상 (5-Stage Pipeline)
이 문제를 해결하기 위해 등장한 것이 파이프라인 아키텍처입니다. 같은 5단계를 서로 다른 명령어가 매 cycle씩 밀려서 동시에 진행하도록 겹칩니다.
| Cycle | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| Inst 1 | IF | ID | EX | ME | W | ||||
| Inst 2 | IF | ID | EX | ME | W | ||||
| Inst 3 | IF | ID | EX | ME | W | ||||
| Inst 4 | IF | ID | EX | ME | W | ||||
| Inst 5 | IF | ID | EX | ME | W |
명령어 사이에 의존성이 없다면, 매 cycle마다 새로운 명령어를 Fetch할 수 있습니다. 개별 명령어의 전체 Latency는 여전히 5 cycle이지만, 다음 명령어를 시작하기 위해 기다려야 하는 시간은 단 1 stage(1 cycle)뿐입니다.
그 결과 같은 9 cycle 동안 5개의 명령어가 끝납니다(순차 실행은 1개). 의존성이 없는 명령어들의 경우 이론적으로 x5 Throughput 향상을 얻는 셈입니다. 각 명령어의 Latency 자체는 변하지 않지만, 여러 명령어의 실행 단계가 겹치면서 전체 Throughput이 크게 개선되는 것이 파이프라이닝의 본질입니다.
Vertical Microcode (Encoding)
여기서 한 가지 짚어볼 만한 점이 있습니다. 위에서 5단계의 두 번째 스테이지로 자연스럽게 등장한 ID(Instruction Decode), 즉 “명령어가 디코딩된다”는 부분입니다. 디코딩이 있다는 것은 그만큼 인코딩 방식도 다양하다는 뜻이고, 인코딩 방식에 따라 디코딩이 하는 일도 달라집니다.
크게 보면 명령어 인코딩 방식은 Vertical과 Horizontal 두 가지로 나눌 수 있습니다. Horizontal 방식은 뒤에서 VLIW를 다룰 때 다시 등장하므로 여기서는 먼저 Vertical 방식을 살펴봅니다.
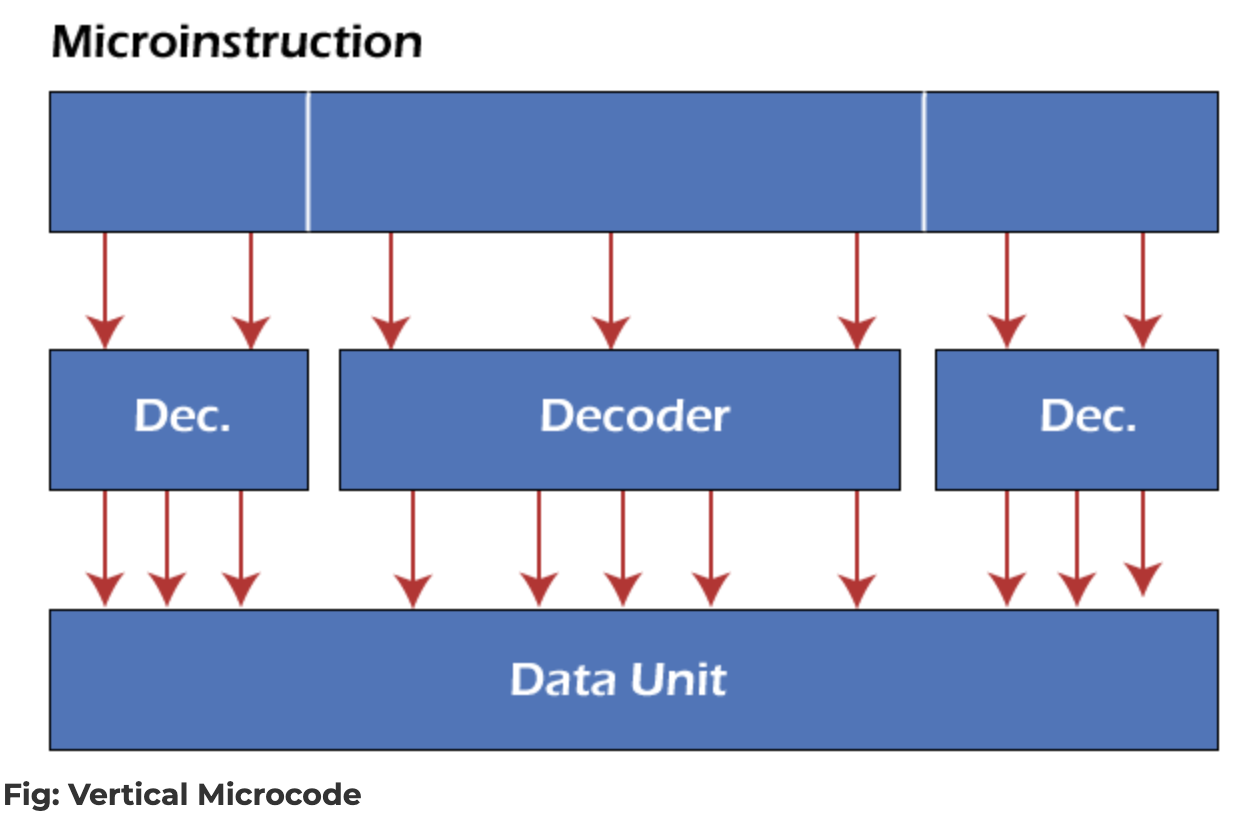
일반적으로 우리가 떠올리는 RISC나 CISC 명령어 세트는 Vertical Encoding 방식으로 인코딩되어 있습니다. 명령어의 각 비트가 실제 하드웨어에서 어떤 역할을 하는지 그대로 노출되어 있는 것이 아니라, 위쪽 (명령어) 단계에서는 정보가 중첩된 형태로 압축되어 있고, 디코딩 단계를 거쳐서야 그 중첩이 풀려 데이터패스의 각 유닛을 제어하는 실제 신호로 펼쳐집니다.
이런 구조 덕분에 파이프라인 아키텍처의 디테일은 소프트웨어에 노출되지 않습니다. ISA 위에서 코드를 짜는 개발자는 5-stage가 어떻게 겹치는지, 어떤 신호가 어느 cycle에 어떤 유닛에 도달하는지 알 필요가 없습니다. 이것은 앞서 본 세 가지 접근 방식 중 ①번, Microarchitecture 수준에서 하드웨어가 자체적으로 처리하는 최적화의 전형적인 예입니다.
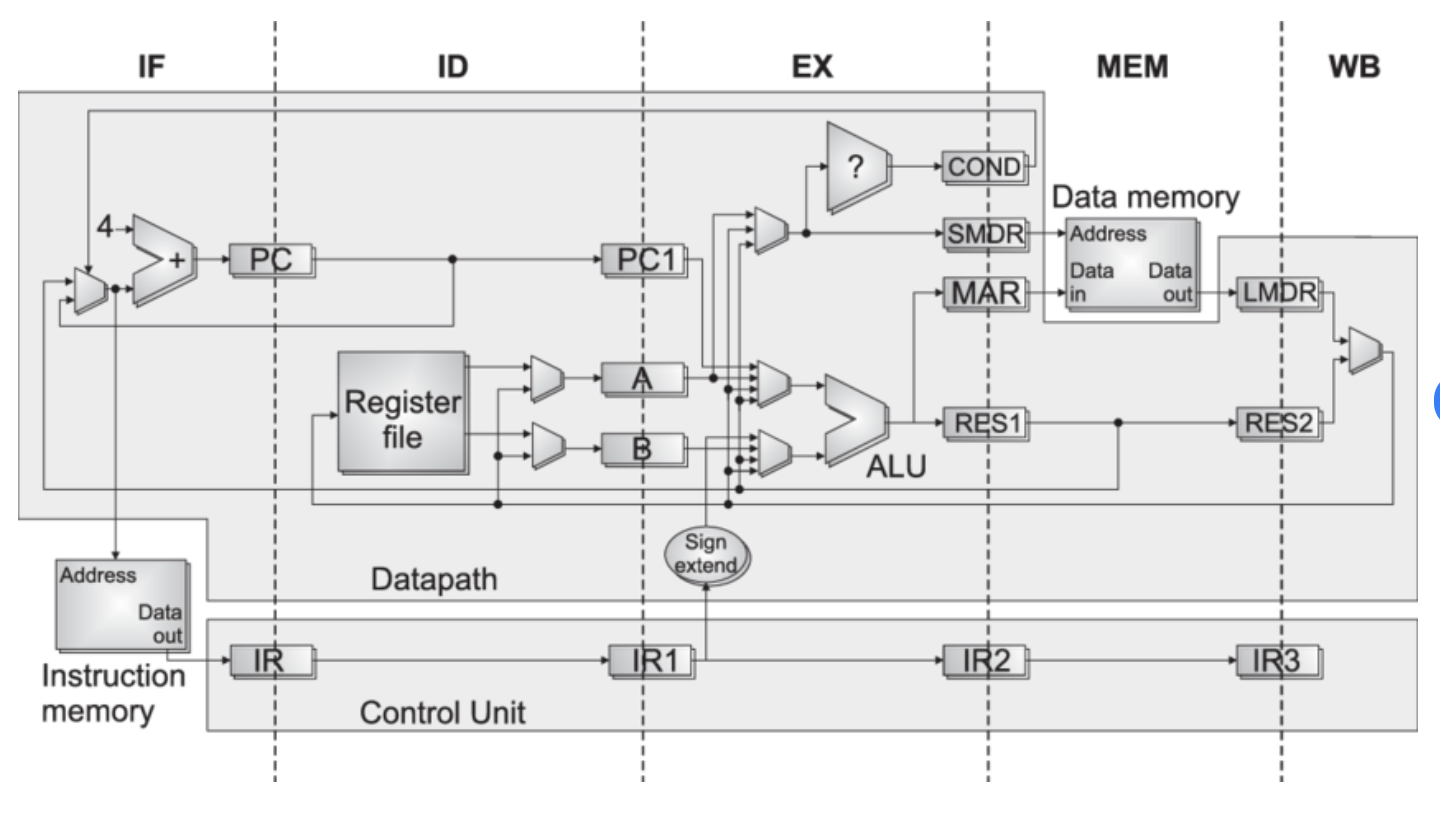
MIPS 5-Stage Pipeline 상세 구조
지금까지 추상적으로 이야기한 5단계가 실제 하드웨어에서는 어떤 모습인지 한번 들여다 보겠습니다.
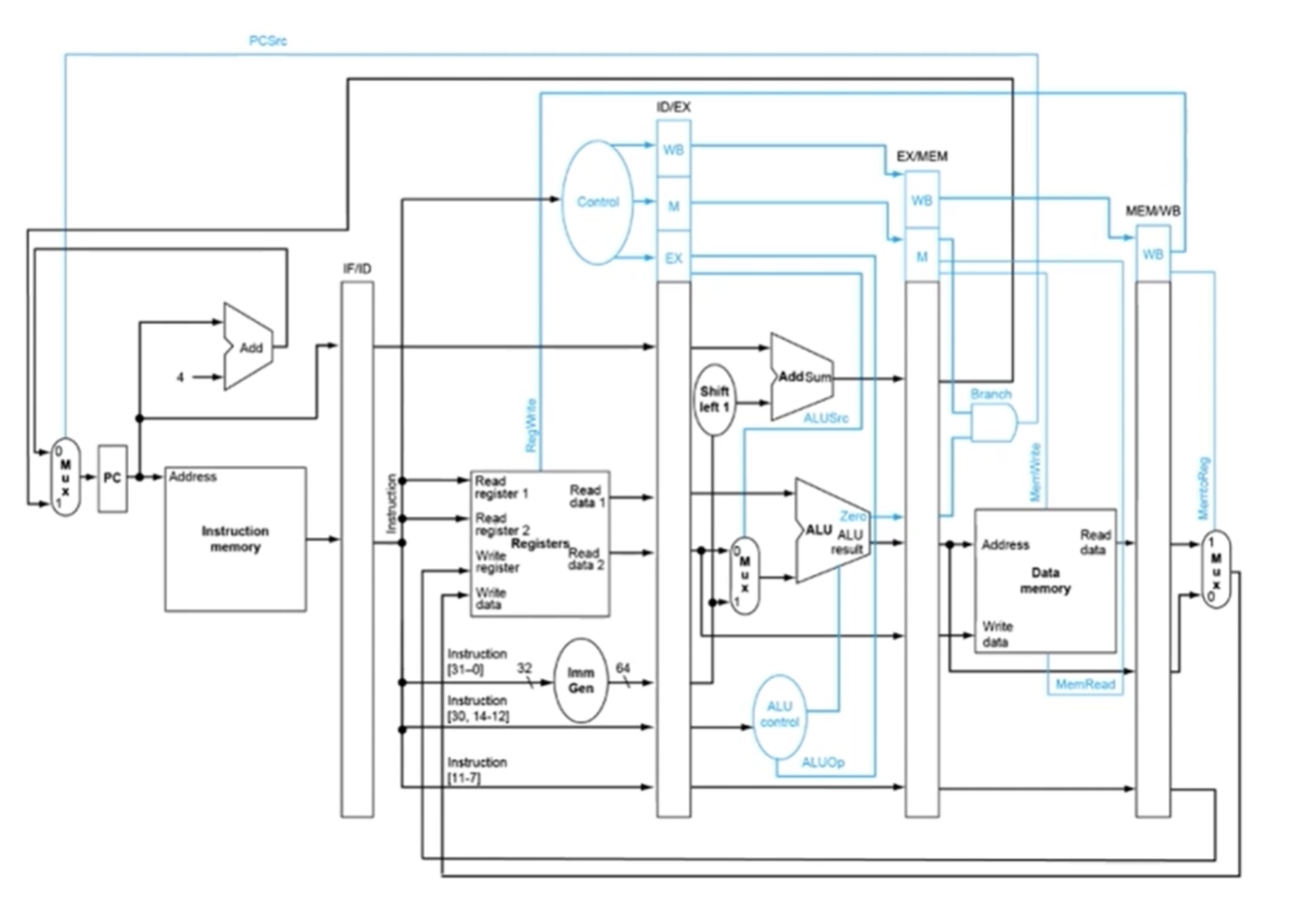
그림은 앞서 말한 다섯 개의 스테이지가 실제로 분리되어 연결된 구조를 보여줍니다. IF 단계에서 인스트럭션 메모리로부터 명령어를 가져오면, 그 다음 단에 있는 큰 박스(ID 단계)에서 디코딩이 일어나며 명령어가 여러 개의 제어 신호로 분기됩니다. 이렇게 분기된 신호들이 가는 곳이 다양합니다.
- 어떤 신호는 레지스터 파일로 들어가 레지스터를 읽습니다.
- 어떤 신호는 그 자체로 다음 스테이지의 입력이 됩니다.
- 어떤 신호는 ALU를 제어합니다.
- 어떤 신호는 더 뒤쪽 스테이지까지 전달되어 거기서 일어나야 할 동작을 결정합니다.
결국 매 cycle마다 하드웨어가 무엇을 하는지는 방금 Fetch한 명령어와 파이프라인 안의 다른 명령어들이 만들어 놓은 상태의 조합으로 결정됩니다.
여기서 다시 한번 확인할 수 있는 사실은, 이 모든 과정이 소프트웨어 입장에서는 전혀 보이지 않는다는 점입니다. ISA(인스트럭션 셋)만 봐서는 Microarchitecture가 이렇게 생겼다는 것을 알 수 없고, 실제로 디코딩되어 펼쳐졌을 때 비로소 하드웨어를 제어하는 신호들로 변환됩니다. 이것이 곧 ISA와 Microarchitecture를 분리한 이유이자, 앞 절의 Vertical Encoding이 가능하게 해 주는 구조적 토대입니다.
Data Hazard와 Bypass Logic
지금까지 본 파이프라이닝은 항상 이상적인 x5 Throughput을 보여주는 것처럼 묘사했지만, 실제로는 그렇지 않은 경우가 종종 있습니다. 파이프라인 버블(Bubble) 또는 파이프라인 스톨(Stall)이라고 부르는 현상이 그것입니다. 이 상황에서는 파이프라인의 어느 stage를 채우지 못해, 그 cycle을 통째로 낭비하게 됩니다.
버블이 발생하는 원인 중 대표적인 것이 레지스터 간 의존성에 의한 Data Hazard입니다. 앞 명령어가 아직 결과를 레지스터에 쓰지 않았는데, 뒤 명령어가 그 값을 읽어야 하는 상황이 그것입니다.
교과서에 나오는 간단한 5-stage 파이프라인 아키텍처에서는 이런 Data Hazard를 Bypass Logic(또는 Forwarding)이라고 부르는 기법으로 상당 부분 해결합니다. 아직 레지스터 파일에 정식으로 저장되지 않은 데이터라도, 이미 계산이 끝난 결과라면 뒤쪽 스테이지로 곧바로 포워딩해서 버블을 없애는 것입니다.
Data Hazard가 발생할 수 있는 상황을 하드웨어가 더 복잡한 로직을 동원해 자체적으로 해결하는 방식이라고 볼 수 있습니다. 다만 모든 해저드를 항상 해결할 수 있는 것은 아닙니다(예: 메모리 로드 직후의 의존성처럼 시점상 어쩔 수 없이 한 cycle을 멈춰야 하는 경우).
Branch Latency 문제
Bypass Logic으로 상당수의 Data Hazard를 해결할 수 있다고 했지만, 파이프라이닝에서 완벽하게 숨기기가 어려운 대표적인 케이스가 하나 있습니다. 바로 Branch(분기) 명령어입니다.
문제의 구조는 이렇습니다. 파이프라인의 첫 단계는 IF(Instruction Fetch)인데, Fetch를 하려면 인스트럭션 메모리의 어느 주소에 다음 명령어가 있는지를 알아야 합니다. 그런데 Branch 명령어를 만나면 그 다음 명령어가 어디에 있는지가 분기 조건과 분기 대상 주소가 계산되어야 비로소 결정됩니다. 그리고 그 계산은 보통 파이프라인의 후반 스테이지에서 일어납니다.
IF 단계와 분기 조건/주소가 결정되는 단계 사이에는 여러 cycle의 거리가 있고, 그 사이 동안은 다음 명령어를 Fetch할 수가 없습니다. 그래서 분기로 인해 발생하는 Latency는 Bypass Logic 같은 트릭으로 깔끔하게 숨겨지지 않으며, Stall이 어느 정도 불가피합니다.
이 문제가 실제 성능에 미치는 영향도 작지 않습니다. Integer program 기준으로 보통 6~7개 명령어 중 하나가 Branch이기 때문에, 분기 처리 비용을 줄이는 것은 파이프라인 아키텍처의 중요한 과제가 됩니다.
Branch Latency Hiding: Delayed Slot
이 Branch 문제를 해결하기 위한 기법 중 하나로, MIPS 아키텍처는 Branch Delay Slot이라는 다소 흥미로운 방법을 도입했습니다.
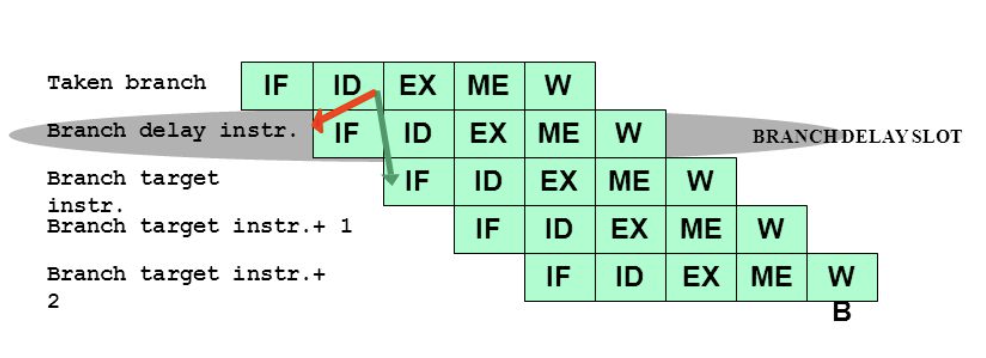
아이디어는 이렇습니다. 분기 명령어 바로 뒤에 위치한 명령어 한 개(= Delay Slot에 들어간 명령어)는, 분기가 Taken이든 Not Taken이든 무조건 실행되도록 ISA의 의미를 정해 버리는 것입니다. 그러면 파이프라인이 분기 결과를 기다리며 비어 있을 cycle 슬롯을 그 명령어로 채울 수 있어, 버블이 사라집니다.
사실 이건 고수준 프로그래밍 언어 관점에서 보면 꽤 어색한 발상입니다. 보통 우리는 “분기를 타면 타는 거고, 안 타면 안 타는 것”으로 코드를 짜지, “분기 다음 한 명령어는 분기 여부와 무관하게 무조건 실행된다”는 의미를 굳이 생각하지 않습니다. MIPS 설계자들은 Branch Delay로 생기는 빈 슬롯을 활용하기 위해, 의도적으로 ISA의 의미(Semantics)를 바꿔서 이 효과를 얻었다고 볼 수 있습니다.
다만 이 방식에는 단점이 분명합니다.
- 어셈블리 코딩이 까다로워집니다. 사람이 직접 짤 때 분기 다음 한 칸의 의미를 늘 의식해야 합니다.
- 컴파일러가 Delay Slot에 넣을 적절한 명령어를 찾지 못하는 경우가 자주 생깁니다.
- 파이프라인 depth가 깊어지면 Branch Delay도 길어지는데, Delay Slot 한두 개만으로는 그 늘어난 buffer를 다 메우기 어렵습니다.
이런 이유로 Branch Delay Slot은 현재는 거의 사용되지 않는 기법입니다. 결국 ISA의 의미를 바꾸는 방식보다는, 하드웨어 자체가 분기를 어떻게든 예측해서 미리 진행하는 방향으로 진화하게 되는데, 그것이 다음 절의 Branch Prediction입니다.
Branch Latency Hiding: Branch Prediction
Branch는 생각보다 굉장히 빈번하게 일어납니다. 워드프로세서·웹브라우저처럼 일반적으로 “Integer program”이라 부르는 워크로드에서는 6~7개 명령어 중 하나는 Branch일 정도입니다. 이때마다 Branch Latency가 그대로 노출되어 버블이 생긴다면 성능에 큰 영향을 줍니다. 그래서 Delay Slot처럼 ISA의 의미를 바꾸는 트릭이 아니라, 하드웨어 자체에 별도 장치를 두어 Branch Latency를 숨기는 방식이 등장합니다. 그 가장 보편적이고 유명한 장치가 바로 Branch Prediction입니다.
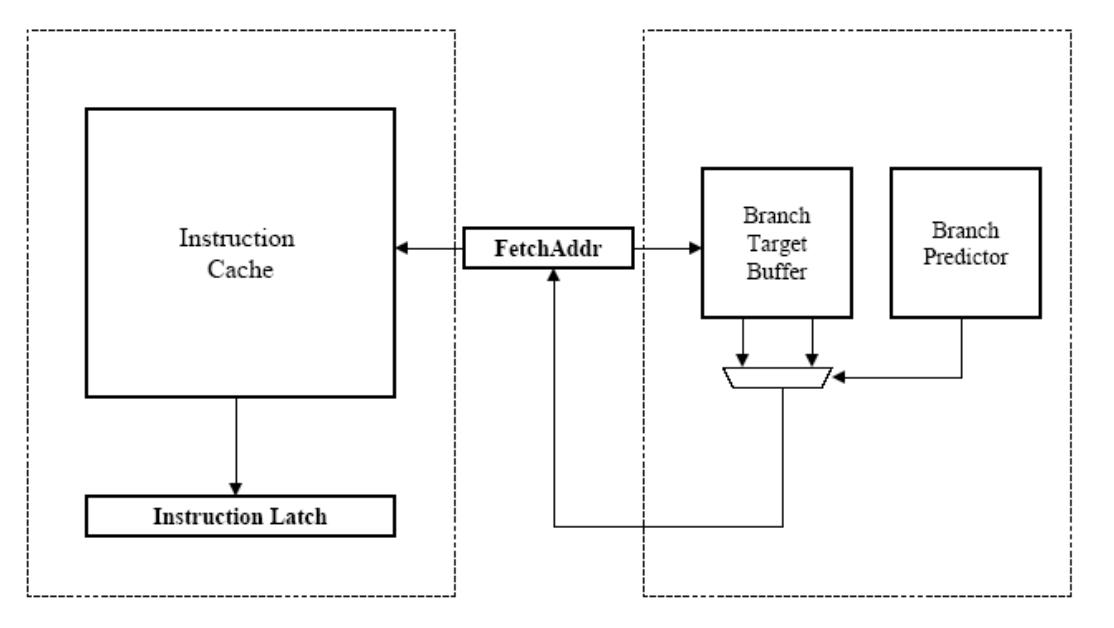
무엇을 예측해야 하는가?
Branch가 일으키는 버블을 없애려면 두 가지 정보가 필요합니다.
- Direction (Taken / Not Taken): 이 분기가 실제로 일어날 것인지 아닌지.
- Target Address: 일어난다면 어느 주소로 점프할 것인지.
문제는 Target Address를 적어도 인스트럭션 디코드(ID) 단계까지 가야 알 수 있다는 점입니다. 디코드가 끝난 다음에야 다음 Branch를 Fetch할 수 있다면, 이미 그 사이에 몇 cycle은 잃은 셈입니다. 즉 Direction만 예측해서는 부족하고, Target Address도 미리 알 수 있어야 진짜로 버블이 사라집니다.
Branch Target Buffer (BTB)
이 두 번째 문제를 해결해 주는 장치가 Branch Target Buffer (BTB) 입니다. BTB는 일종의 캐시인데, 키는 방금 Fetch한 명령어의 주소, 값은 그 명령어가 Branch라면 점프했을 때의 Target Address입니다.
흐름은 이렇게 됩니다.
- 어떤 주소의 명령어를 Fetch한다.
- 그 주소가 BTB에 들어 있는지 본다.
- 들어 있고, Branch Predictor가 “이번엔 Taken일 것”이라고 예측하면, BTB에 저장된 Target Address를 바로 사용해 다음 cycle에 그 주소로 Fetch를 이어 간다.
이렇게 Branch Predictor가 Direction을 예측하고, BTB가 Target Address를 캐싱해 줌으로써, 분기 명령어가 모두 디코드되기를 기다리지 않고 곧바로 다음 명령어를 가져올 수 있게 됩니다.
Misprediction과 Speculative Execution
당연히 Prediction은 항상 맞지는 않습니다. 예측이 맞으면 대기 없이 진행하고, branch가 실제로 resolve된 뒤 결과가 예측과 다르면 Misprediction으로 처리됩니다. (BTB의 hit/miss는 target 주소가 캐싱되어 있는지의 문제일 뿐, 예측이 맞았는지는 branch가 resolve되어야 알 수 있습니다.) Misprediction이 발생하면 그동안 잘못된 경로에서 진행한 작업을 모두 버리고 올바른 주소에서 다시 Fetch를 시작해야 하는데, 그 사이에 이미 많은 작업이 진행된 복잡한 프로세서일수록 별도의 Rollback / Recovery 로직이 필요해집니다.
이렇게 정답이 무엇인지 아직 확실히 모르는 상태에서, 확률이 더 높은 쪽을 미리 골라 실행을 진행해 나가는 방식을 컴퓨터 아키텍처에서는 Speculative Execution(추측 실행) 이라고 부릅니다. Branch Prediction은 그 가장 대표적인 예시이고, 이후 OOO Processor를 다룰 때 다시 확장된 형태로 등장합니다.
Instruction-Level Pipelining 정리
지금까지 한 절에서 다룬 내용이 적지 않으니, 여기서 한 번 큰 그림으로 정리하고 넘어가겠습니다. 이 절은 결국 “명령어 하나의 Latency를 어떻게 파이프라이닝으로 hiding하고, 거기서 생기는 부작용을 어떻게 해결하는가”라는 한 줄기 이야기였습니다.
| # | 문제 / 상황 | 원인 | 해결 기법 | 결과 / 한계 |
|---|---|---|---|---|
| 1 | 순차 실행은 Throughput이 낮음 | 한 명령어 Latency가 그대로 누적 | 5-Stage Pipelining | 의존성 없으면 이론적 x5 Throughput |
| 2 | 파이프라인 버블 (Data Hazard) | 레지스터 간 의존성 | Bypass Logic / Forwarding | 일부 hazard는 여전히 stall (예: load-use) |
| 3 | 파이프라인 버블 (Branch Latency) | Direction과 Target Address가 늦게 결정됨 | (구) Delay Slot → (현) Branch Prediction + BTB | Misprediction 시 Rollback 비용 발생 |
이 흐름을 한 줄로 요약하면 이렇습니다.
파이프라이닝으로 Throughput을 끌어올리되, 거기서 생기는 Data Hazard와 Control Hazard(Branch)를 점점 더 정교한 하드웨어 장치(Forwarding, BTB, Branch Predictor, Speculative Execution)로 잡아 나가는 과정.
여기서 중요한 메타 관찰이 하나 있습니다. Delay Slot 한 가지를 제외하면, 위의 모든 해결 기법은 소프트웨어에 노출되지 않고 하드웨어가 자체적으로 처리하는 방식이라는 점입니다. 즉 앞에서 본 「프로세서 설계의 핵심 질문」의 세 가지 접근 방식 중 ①번, Microarchitecture 수준의 최적화에 의존하는 방향이, Instruction-Level Pipelining에서는 거의 정답에 가까운 위치를 차지하고 있습니다.
다음 절부터는 같은 Latency Hiding의 줄기를 이어가되, 단위를 한 단계 키워서 다룹니다. 한 명령어가 아니라 루프 iteration 단위로 겹쳐 실행하는 Loop-Level Pipelining, 그리고 그것을 하드웨어적으로 푸는 OOO와 소프트웨어적으로 푸는 VLIW가 등장합니다.
Loop-Level Pipelining
Instruction-level pipelining이 개별 명령어의 실행 단계를 겹치는 것이었다면, Loop-level pipelining은 한 단계 더 나아가 루프의 서로 다른 iteration을 겹쳐서 실행하는 것입니다.
루프의 순차적 실행 한계
앞 절의 마지막에서 본 것처럼, 프로그램에서 Branch는 6~7개 명령어 중 하나꼴로 굉장히 자주 등장합니다. 그리고 그 중 상당 부분은 단순한 if/else가 아니라 루프(loop)의 끝에서 다시 위로 돌아가게 만드는 분기입니다. 결국 루프를 빠르게 도는 것이 곧 프로그램 전체 성능을 끌어올리는 과제가 됩니다.
Loop을 더 빠르게 돌릴 순 없을까?
loop: slli s2, s1, 2 # 1
add s3, s0, s2 # 2
lw t1, 0(s3) # 3
mul t2, t1, t1 # 4
add t3, t2, t1 # 5
sw t3, 0(s3) # 6
addi s1, s1, 1 # 7
blt s1, t0, loop # 8slli s2, s1, 2 # 1 add s3, s0, s2 # 2 lw t1, 0(s3) # 3 mul t2, t1, t1 # 4 add t3, t2, t1 # 5 sw t3, 0(s3) # 6 addi s1, s1, 1 # 7 blt s1, t0, loop # 8
slli s2, s1, 2 # 1 add s3, s0, s2 # 2 lw t1, 0(s3) # 3 mul t2, t1, t1 # 4 add t3, t2, t1 # 5 sw t3, 0(s3) # 6 addi s1, s1, 1 # 7 blt s1, t0, loop # 8
왼쪽은 루프 자체(loop: 레이블이 붙어 반복 시작점이 되는 코드)이고, 오른쪽은 그 루프를 실제로 풀어서(unroll) 순차 실행했을 때의 모습입니다. 마지막 줄에 있는 BLT(Branch if Less Than)가 조건부 분기 명령어로, 루프의 끝에서 다시 처음으로 되돌아가는 Back Edge를 형성합니다. 문제는 이 조건부 분기가 해결되어야만 다음 iteration을 시작할 수 있다는 점입니다.
따라서 아무 장치 없이 그대로 두면 이 루프는 iteration 단위로 순차 실행될 수밖에 없습니다. 한 iteration이 BLT까지 다 끝나야 비로소 다음 iteration의 첫 명령어를 시작할 수 있는 구조이기 때문입니다. 이 구조를 어떻게 깨고 iteration들을 겹쳐 실행할 것인가가 Loop-level pipelining의 출발점입니다.
Iteration 중첩을 통한 Latency Hiding
여기서 자연스럽게 떠올릴 수 있는 질문이 있습니다. 앞 절에서 명령어 수준에서 파이프라이닝을 적용해 Latency를 hiding 했듯이, 루프 수준에서도 똑같이 파이프라이닝을 할 수는 없을까요? 만약 iteration들의 실행을 겹칠 수만 있다면 루프 자체를 가속할 수 있을 것입니다.
만약 iteration들을 중첩시켜 Latency Hiding을 한다면?
앞 절의 5-Stage Pipeline에서 본 것과 동일한 아이디어를 한 단계 위(루프 iteration 단위)에 적용해 봅니다. 이전 iteration이 끝나기를 기다리지 않고, 다음 iteration을 일찍 시작해서 명령어 실행을 겹치게 만드는 것입니다.
loop: slli s2, s1, 2 # 1
add s3, s0, s2 # 2
lw t1, 0(s3) # 3
mul t2, t1, t1 # 4
add t3, t2, t1 # 5
sw t3, 0(s3) # 6
addi s1, s1, 1 # 7
blt s1, t0, loop # 8slli s2, s1, 2 # 1 add s3, s0, s2 # 2 lw t1, 0(s3) # 3 mul t2, t1, t1 # 4 add t3, t2, t1 # 5 sw t3, 0(s3) # 6 addi s1, s1, 1 # 7
slli s2, s1, 2 # 1 add s3, s0, s2 # 2 lw t1, 0(s3) # 3 mul t2, t1, t1 # 4 add t3, t2, t1 # 5 sw t3, 0(s3) # 6 addi s1, s1, 1 # 7
slli s2, s1, 2 # 1 add s3, s0, s2 # 2 lw t1, 0(s3) # 3 mul t2, t1, t1 # 4 add t3, t2, t1 # 5 sw t3, 0(s3) # 6 addi s1, s1, 1 # 7
각 iteration이 다른 data를 접근한다면 충분히 가능
아래 그림이 보여주는 것이 바로 이 중첩 실행입니다. 같은 루프 본문이 옆으로 밀린 형태로 세 번 나란히 배치되어 있는데, 이는 시간 축에서 iteration 1이 진행 중일 때 iteration 2의 첫 명령어가 시작되고, 다시 일정 시점에 iteration 3가 시작되는 모습을 시각화한 것입니다. 앞 절의 5-Stage Pipeline 표가 한 명령어의 stage 단위로 겹치는 것을 보여줬다면, 이 그림은 한 iteration의 명령어 단위로 같은 일을 하고 있는 셈입니다.
당연히 이 중첩이 항상 안전하지는 않습니다. 전제는 각 iteration이 서로 다른 데이터를 접근한다는 것, 즉 iteration 간 의존성이 약해서 현재 iteration이 끝나기 전에 다음 iteration을 시작해도 결과가 달라지지 않아야 한다는 것입니다.
다행히 우리가 실제로 짜는 많은 루프들이 이런 특성을 갖고 있습니다. 예컨대 배열의 원소들에 같은 연산을 적용하는 루프, 행렬의 행/열을 따라 순회하는 루프 등은 iteration 간 의존성이 거의 없습니다. 즉 Loop-level pipelining으로 성능을 끌어올릴 여지가 매우 큰 케이스가 현실 코드에서 광범위하게 존재하는 셈입니다. 다음 절에서는 이 가능성을 실제로 구현하기 위해 어떤 방해 요소를 넘어야 하는지 살펴봅니다.
방해요소와 해결책
이론적으로는 가능하다고 했지만, 실제로 iteration들을 중첩 실행하는 일은 그렇게 간단하지 않습니다. Loop-level pipelining을 방해하는 요소가 크게 두 가지 있고, 각각에 대응되는 해결책이 명확하게 짝지어져 있습니다.
| 방해요소 | ⇒ | 해결책 |
|---|---|---|
| Control Flow (conditional branch) | ⇒ | Branch Prediction |
| 다른 iteration의 instruction 사이 False Data Dependency | ⇒ | Register Renaming |
1. Control Flow (조건부 분기)
앞서 본 것처럼, 루프 끝에 있는 조건부 분기(BLT)는 컴파일러가 흔히 Back Edge라고 부르는 흐름을 만듭니다. 원칙적으로는 이 Back Edge가 해결되어야 다음 iteration을 시작할 수 있으므로, 분기 결과를 알기 전에는 다음 iteration을 출발시킬 수 없다는 제약이 생깁니다.
해결책은 이미 한 번 본 적이 있습니다. 명령어 수준 파이프라이닝에서 다뤘던 Branch Prediction입니다. 분기 방향과 Target Address를 미리 예측해 다음 iteration의 첫 명령어를 곧장 Fetch하면, Back Edge가 만든 stall을 hiding할 수 있습니다.
2. False Data Dependency (다른 iteration의 instruction 사이)
두 번째 방해요소는 다소 미묘합니다. 같은 루프의 서로 다른 iteration들은 계산상으로는 완전히 독립일 수 있는데도, 같은 레지스터를 재사용한다는 이유만으로 의존성이 있는 것처럼 보이는 경우가 그것입니다.
여기서 두 종류의 의존성을 구분할 필요가 있습니다.
- True Dependency - 실제로 어떤 값이 계산되고 그 값을 다른 명령어가 사용하는 관계. 값 자체가 필요하므로 반드시 지켜져야 합니다.
- False Dependency - 값을 저장해 놓은 저장 공간(레지스터)이 하필 겹쳐서 생기는 가짜 의존성. 만약 더 많은 저장 공간이 있어서 같은 레지스터를 쓰지 않았다면 처음부터 의존성이 없었을 관계입니다.
루프의 경우, iteration 1과 iteration 2가 계산상 완전히 독립이더라도, 사용 가능한 레지스터 수가 제한되어 있어 같은 레지스터(예: s2, t1, t3 …)에 반복적으로 읽고 쓰게 됩니다. 그 결과 실제로는 무관한 두 계산 사이에 False Dependency가 생기고, 중첩 실행이 막힙니다.
해결책은 Register Renaming입니다. iteration마다 서로 다른 (논리적) 레지스터를 쓰도록 이름을 바꿔 주면, False Dependency가 해소되어 iteration들을 자유롭게 겹칠 수 있습니다.
그런데, 소프트웨어로는 표현이 안 된다
여기서 결정적인 한 가지 문제가 있습니다. 우리가 일반적으로 사용하는 프로세서는 Sequential Semantics, 즉 “명령어를 적힌 순서대로 차례차례 수행한다”는 의미를 전제로 합니다. 그리고 ISA가 노출하는 레지스터의 개수와 이름은 고정되어 있습니다. 따라서 소프트웨어(컴파일러나 어셈블리)가 “iteration마다 다른 레지스터를 써라”라고 표현할 방법 자체가 없습니다.
이론적으로는 Loop-level pipelining이 가능하지만, Sequential Semantics를 가진 ISA 위에서 소프트웨어만으로는 그 중첩을 표현할 수 없다는 것이 결정적인 제약이 됩니다. 이 제약을 어떻게 푸느냐에 따라 두 가지 갈래가 생기는데, 그것이 바로 다음 절에서 다룰 OOO Processor(하드웨어가 동적으로 풀어주는 방식)와 VLIW(ISA 자체를 바꿔서 푸는 방식)입니다.
OOO(Out-Of-Order) Processor: 하드웨어적 접근
Out-of-Order Processor는 위에서 본 두 가지 방해 요소(Control Flow, False Data Dependency)를 하드웨어가 동적으로 풀어주는 방식입니다. Sequential 의미를 가진 ISA를 그대로 두면서도, 내부적으로는 Branch Prediction과 Register Renaming을 동원해 iteration들을 겹쳐 실행할 수 있는 형태로 코드를 재해석합니다. 큰 흐름은 다음 세 단계입니다.
loop: slli s2, s1, 2 # 1
add s3, s0, s2 # 2
lw t1, 0(s3) # 3
mul t2, t1, t1 # 4
add t3, t2, t1 # 5
sw t3, 0(s3) # 6
addi s1, s1, 1 # 7
blt s1, t0, loop # 8prediction
slli s2, s1, 2 # 1 add s3, s0, s2 # 2 lw t1, 0(s3) # 3 mul t2, t1, t1 # 4 add t3, t2, t1 # 5 sw t3, 0(s3) # 6 addi s1, s1, 1 # 7
slli s2, s1, 2 # 1 add s3, s0, s2 # 2 lw t1, 0(s3) # 3 mul t2, t1, t1 # 4 add t3, t2, t1 # 5 sw t3, 0(s3) # 6 addi s1, s1, 1 # 7
speculative trace를 만들고
renaming
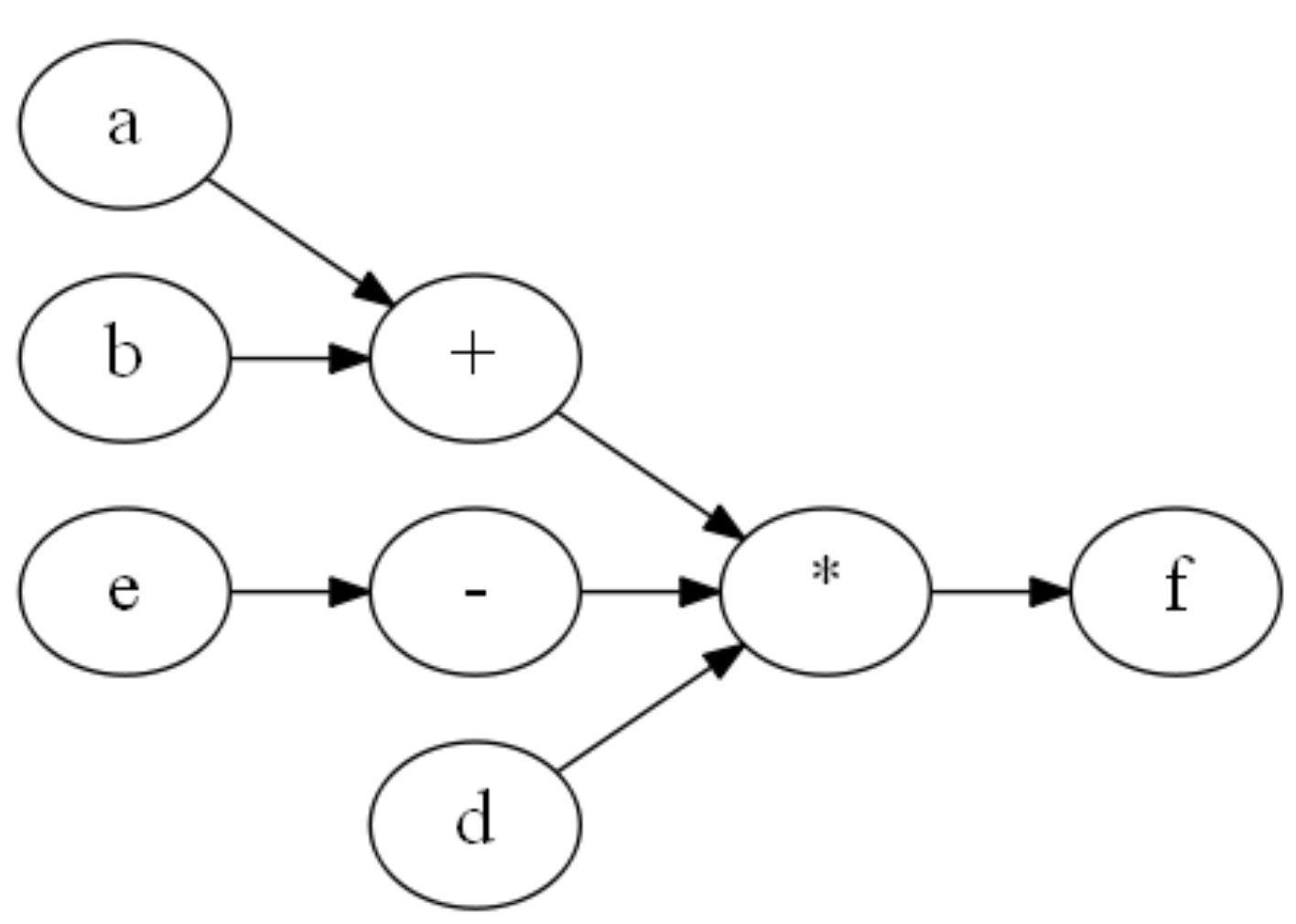
data-flow graph로 전환
각 단계를 풀어 보면 다음과 같습니다.
- Sequential code로부터 출발 - ISA는 여전히 “위에서 아래로 차례차례 실행” 의미를 가진 보통의 명령어 시퀀스입니다(
slli → add → lw → … → blt). - Branch Prediction으로 speculative trace 생성 - 루프 끝의
blt를 만나면 Branch Predictor가 “이번에도 Taken일 것”이라 예측하고, 그 결과를 받은 것처럼 다음 iteration의 명령어들을 추측해서 미리 펼쳐 둡니다. 이렇게 펼쳐진 직선형 명령어 흐름을 speculative trace라고 부릅니다. 분기가 사라진 직선 코드이므로 최적화·재배치를 적용하기 훨씬 편해집니다. - Register Renaming → Data-flow graph 전환 - 펼쳐진 trace에는 같은 레지스터 이름이 iteration마다 반복 등장하지만, 하드웨어가 이름을 바꿔 주면 False Dependency가 사라집니다. 그 결과 명령어들 사이에는 오직 True Dependency만 남고, 전체 코드는 의존 관계를 표현하는 data-flow graph(DAG) 형태로 정리됩니다. 이 DAG에서는 topological order로 묶을 수 있는 명령어들은 동시에 실행해도 결과가 같기 때문에, 자연스럽게 병렬 처리가 가능해집니다.
어떻게 하드웨어는 가능한가? Physical Register
여기서 자연스러운 의문이 듭니다. 앞에서 “소프트웨어로는 iteration마다 다른 레지스터를 쓰도록 표현할 수 없다”고 했는데, 어떻게 하드웨어는 그게 가능할까요? 비밀은 하드웨어가 ISA로 노출된 것보다 훨씬 많은 레지스터를 실제로 가지고 있다는 점에 있습니다.
- Architectural Register (논리 레지스터) - ISA가 노출하는, 소프트웨어가 보는 레지스터 이름들(
s0,s1,t0,t1, …). 그 개수는 ISA에 의해 고정됩니다. - Physical Register (물리 레지스터) - 칩 위에 실제로 존재하는 저장 장치들. 일반적으로 Architectural Register보다 수 배 더 많습니다.
OOO Processor는 명령어가 들어올 때마다 코드에 적힌 Architectural Register 이름을, 그 시점에 비어 있는 Physical Register 중 하나에 매핑합니다. 그리고 그 명령어가 같은 Architectural 이름을 읽을 때는, 매핑 테이블을 따라가서 올바른 값이 들어 있는 Physical Register를 가리키도록 만듭니다. 이름은 그대로 t1이지만, 실제로는 iteration 1의 t1과 iteration 2의 t1이 서로 다른 물리 저장소에 들어가 있는 셈입니다.
이 매핑·트래킹을 모든 명령어에 대해 매 cycle 수행하면, ISA가 보여주는 시퀀셜 코드와는 별도로 하드웨어 내부에서는 Renaming이 끝난 데이터-플로우 그래프가 생성됩니다. 그리고 이 그래프 위에서는 의존성이 해결된 명령어들이 도착하는 대로, 원래 코드 순서와 무관하게(out-of-order) 동시에 실행될 수 있습니다. 이것이 바로 이 절의 이름인 Out-of-Order Processor입니다.
결과적으로 ISA는 여전히 Sequential Semantics를 유지하지만, 하드웨어 내부에서는 루프가 파이프라인된 형태로 수행되며 매 cycle 여러 개의 instruction을 동시에 처리하는 효과를 얻습니다. 오늘날 사용되는 대부분의 CPU(Intel, AMD 등)가 이 OOO 기법을 채택하고 있습니다.
결과적으로 Loop이 Pipeline된 형태로 수행
이 흐름이 실제 실행 시점에는 어떤 모습으로 나타나는지를 그림으로 보면 다음과 같습니다.


여러 iteration의 루프 본문이 살짝씩 밀려서 나란히 진행되고, 같은 시점(cycle)을 기준으로 슬라이스를 떠 보면 서로 다른 iteration의 명령어들이 동시에 수행되고 있는 모습이 됩니다.
여기서 흥미로운 점은, 이 모습이 앞 절에서 본 Instruction-Level Pipelining의 5-Stage 표와 구조적으로 매우 닮았다는 것입니다. 다만 단위가 한 단계 커져서, “한 명령어 안의 IF/ID/EX/ME/W stage”가 아니라 “한 iteration 안의 명령어 묶음”이 각 stage를 차지하고, 서로 다른 iteration들이 다른 stage에 동시에 머무르며 매 cycle 한 칸씩 진행됩니다. 반복되는 패턴만 잘라내면 동일한 코드가 계속 돌아가는 것처럼 보이게 되는 것입니다.
다만 한 가지 주의할 점은, OOO Processor가 정확히 이 그림과 똑같이 고정된 패턴으로 돈다는 뜻은 아니라는 것입니다. OOO는 매 cycle 들어오는 명령어 윈도우의 상태에 따라 동적으로 다른 명령어 조합을 골라 실행합니다. 위 그림은 그 동작이 개념적으로 만들어 내는 중첩 효과를 단순화해서 보여 줄 뿐입니다.
보충: 데이터 플로우 그래프는 어디에 살아있는가?
수강생 질문이 있어서 잠깐 보태둡니다. 하드웨어가 데이터 플로우 그래프를 자료구조로 유지하는가?라는 질문에 대한 답은 “그렇다”입니다. OOO Processor는 다음 장치들을 통해 그 그래프를 동적으로 만들고 갱신합니다.
- Reservation Station / Reservation Table - 각 명령어가 어떤 Physical Register의 값을 기다리고 있는지 태깅해 두는 테이블. 입력 값이 도착하면 해당 명령어가 실행 가능 상태로 바뀝니다.
- Renaming Table - 어떤 Architectural Register가 현재 어떤 Physical Register에 매핑되어 있는지를 추적합니다. 새 명령어가 들어올 때마다 이 테이블을 참조해 입력 레지스터를 올바른 Physical Register로 다시 이름 붙입니다(rename).
이 자료구조들이 유지하는 그래프의 범위는 무한이 아닙니다. 명령어 윈도우(Instruction Window), 즉 아직 처리되지 않았거나 진행 중인 일정 개수의 명령어 안에 있는 명령어들에 대해서만 그래프가 만들어집니다. 명령어가 다 끝나서 윈도우에서 빠져나가면 그래프에서도 사라지고, 새로 들어온 명령어가 그 자리를 채우면서 그래프가 계속 모양을 바꿉니다. 즉 OOO의 데이터 플로우 그래프는 매 cycle 유동적으로 변하는 슬라이딩 윈도우 위의 그래프입니다.
Intel Core Architecture의 OOO Engine
지금까지 이야기한 OOO 동작이 실제 상용 프로세서에서는 어떻게 생겼는지, Intel Core 아키텍처의 다이어그램으로 한번 확인해 보겠습니다.
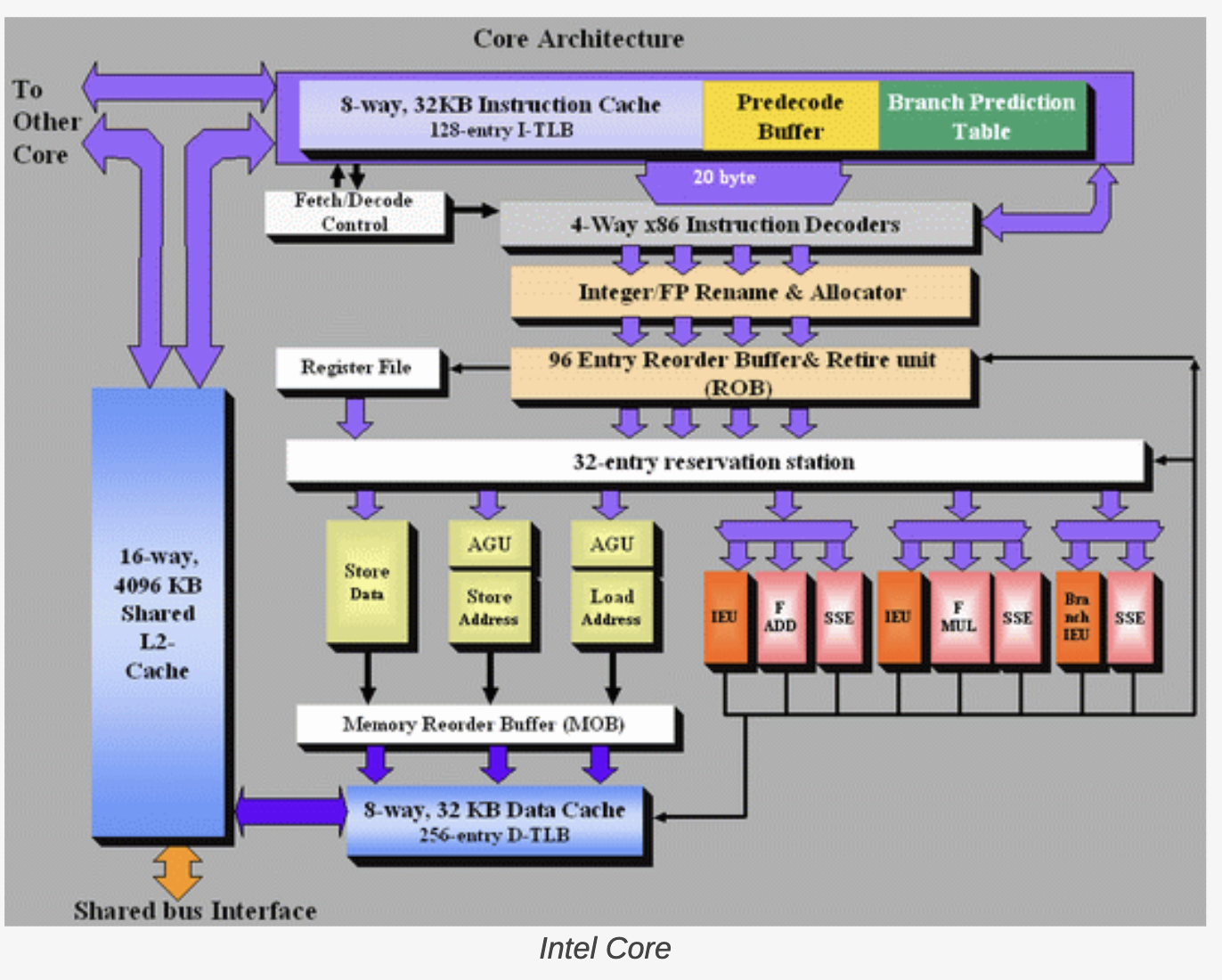
이 그림은 앞 절에서 개념적으로 설명한 “동적으로 Data-Flow Graph를 만들어서 실행하는 엔진”의 실제 구현 단면입니다. 앞 절의 추상화된 자료구조들이 각각 별도의 장치로 구현되어 함께 동작합니다.
- Register Alias Table (RAT) - Architectural Register를 그 시점의 비어 있는 Physical Register로 매핑 (register renaming)
- Reservation Station / Scheduler - 명령어 윈도우 안의 명령어들이 어떤 값을 기다리고, 어디로 결과를 보내는지 매 cycle 갱신하며 실행 가능해진 명령어를 실행 유닛으로 내보냄
- Reorder Buffer (ROB) - 내부적으로는 out-of-order로 실행되더라도, 결과를 외부로 commit할 때는 원래 프로그램 순서대로 정리 (in-order retire) 하고, misprediction 시 rollback의 기준점이 됨
요약하면, 앞 절에서 “Reservation Table + Renaming Table + Instruction Window”로 추상화해 설명한 자료구조들이 실제 Intel Core 안에서는 RAT, Reservation Station, Reorder Buffer라는 장치들로 나뉘어 유기적으로 동작하는 것입니다.
VLIW: 소프트웨어적 접근
다시 보는 OOO의 Loop Pipeline, 그리고 그 비용
VLIW로 넘어가기 전에, 앞 절에서 본 OOO의 Loop Pipeline 동작을 한 번만 더 떠올려 봅시다. OOO Processor는 루프를 파이프라인된 형태로 수행하기 위해, 하드웨어 안에서 매 cycle 다음과 같은 일을 동시에 해내고 있었습니다.
- Speculative Trace 펼치기 - Branch Predictor로 분기 결과를 예측해, 아직 도래하지 않은 다음 iteration의 명령어들까지 미리 fetch하고 펼쳐 둡니다.
- Register Renaming - Architectural Register를 비어 있는 Physical Register로 매핑해 iteration 간 False Dependency를 제거합니다.
- 동적 Data-Flow Graph 유지 - Reservation Station / Renaming Table / Reorder Buffer를 통해, 명령어 윈도우 위에서 그래프를 매 cycle 갱신합니다.
이 모든 일을 하드웨어가 직접, 그리고 동적으로 해내야 한다는 점은 곧 상당한 설계 복잡도를 의미합니다. 게다가 Branch Prediction이 틀린 순간에는 그동안 진행한 작업을 되돌리는 Rollback이 필요해집니다. 더 많은 병렬성을 짜내려고 명령어 윈도우를 크게 잡을수록, 한 번 예측이 빗나갔을 때 되돌려야 하는 양이 커지고 복구 로직 자체도 함께 복잡해집니다. 결국 OOO 방식으로 Loop Pipeline 효과를 얻는 일은, 그것을 가능하게 하는 하드웨어 자체가 매우 복잡할 수밖에 없는 길입니다.
VLIW의 발상
VLIW는 여기에 정반대 방향의 답을 내놓습니다. OOO와 똑같은 결과(즉 루프 iteration들을 펼친 데이터 플로우 그래프를 매 cycle 병렬 실행하는 모습)를, 하드웨어가 동적으로 만들어내는 대신 소프트웨어(컴파일러)가 미리 정적으로 만들어 두는 것입니다. 컴파일러가 Loop Pipeline 모양을 컴파일 타임에 결정해 두면, 하드웨어는 그 계획대로 매 cycle 정해진 일만 하면 되므로 Branch Prediction, Rollback, Reorder Buffer 같은 복잡한 동적 장치를 사실상 버릴 수 있습니다. 이 갈래의 대표 아키텍처가 VLIW(Very Long Instruction Word) 입니다.


생긴 모습은 OOO 때 본 그림과 닮아 있지만, 이 파이프라인을 누가 만들어 내느냐가 결정적으로 다릅니다. OOO에서는 매 cycle 하드웨어가 동적으로 그려내던 그림을, VLIW에서는 컴파일러가 미리 그려서 ISA 차원에서 하드웨어에 던져 줍니다. 하드웨어는 그 모양을 그대로 반복 실행하면 되기 때문에, 하드웨어가 훨씬 단순해지고 실행 효율성도 더 좋을 수 있습니다.
이 하드웨어 동적 vs 소프트웨어 정적의 대비는 강의 초반에 본 「프로세서 설계의 핵심 질문」(① Microarchitecture 최적화 ↔ ② Compiler 최적화)의 대비와 정확히 같은 패턴이고, 뒤에서 다룰 GPU vs NPU의 설계 철학 차이와도 매우 닮아 있습니다. 그래서 OOO와 VLIW 비교는 이번 강의 후반부의 대비를 미리 짚어 보는 작은 예행 연습이기도 합니다.
VLIW 아키텍처의 구조
VLIW의 발상이 실제 하드웨어 도면 위에 어떻게 그려지는지 보겠습니다.
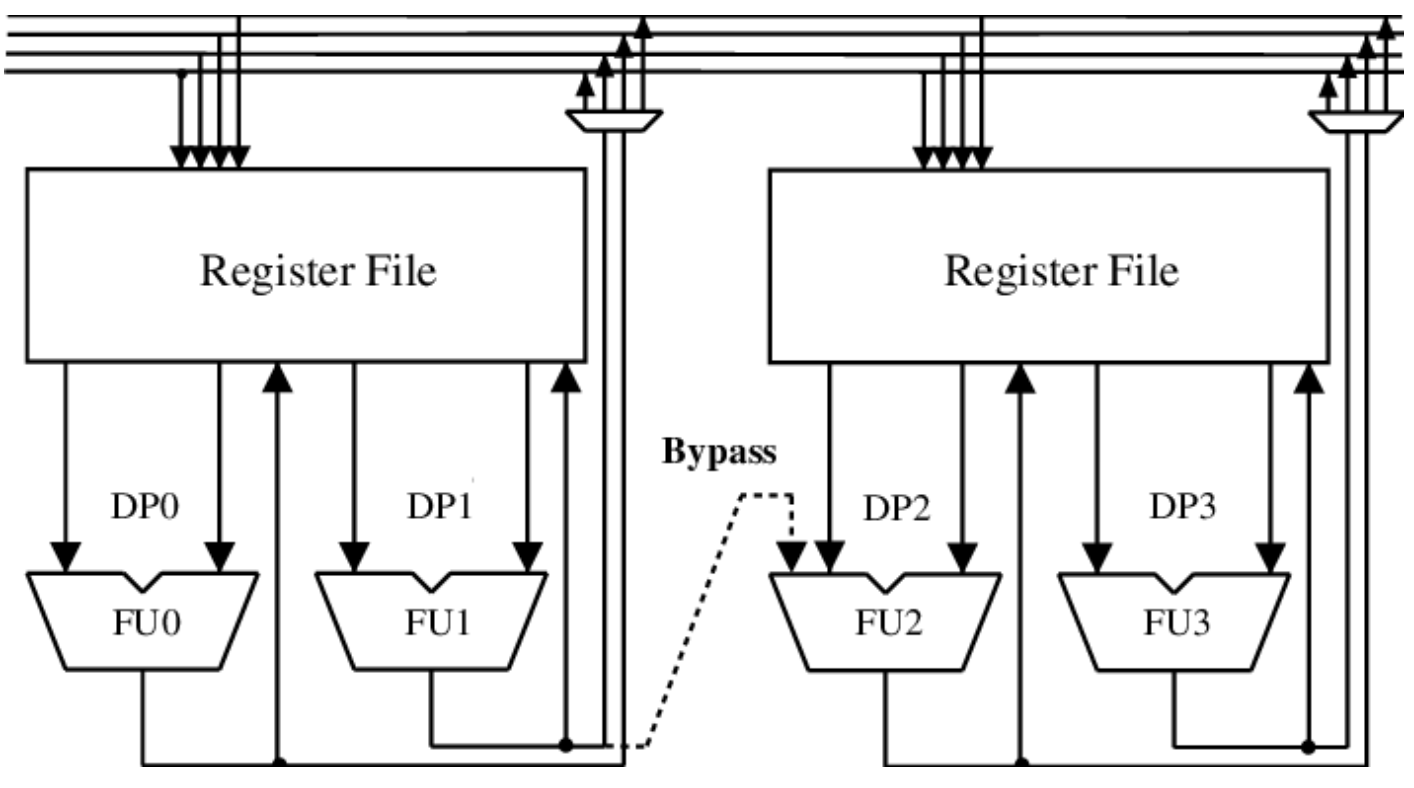
그림에서 가장 눈에 띄는 점은, 여러 Functional Unit(연산 유닛)이 병렬로 늘어서 있고 그 옆에 값을 저장·읽을 수 있는 레지스터 파일이 함께 배치되어 있다는 점입니다. 이런 외형 자체는 사실 OOO Processor의 실행부와도 꽤 닮아 있습니다. 결정적인 차이는 이 유닛들에게 매 cycle 무엇을 시킬지를 누가, 어떻게 표현하느냐에 있습니다.
Register File Partitioning
VLIW에서 한 가지 미묘한 어려움이 있습니다. Functional Unit 개수가 늘어날수록, 그 모두가 하나의 큰 레지스터 파일에 동시에 물리는 것이 점점 어려워진다는 점입니다. 레지스터 파일에는 동시에 읽고 쓸 수 있는 포트(port) 개수가 정해져 있는데, 유닛이 많아질수록 필요한 포트 수가 폭발적으로 늘고, 포트가 많아질수록 레지스터 파일의 회로 자체가 급격히 복잡해집니다.
그래서 VLIW에서는 보통 레지스터 파일을 여러 개로 파티션해서 각 파티션에 일부 Functional Unit만 묶어 두는 형태로 설계합니다. 한 파티션 안에서는 익숙한 레지스터 read/write로 통신하지만, 서로 다른 파티션 간에는 레지스터 파일을 직접 공유할 수 없고 별도의 Interconnect를 거쳐 데이터를 옮겨야 합니다. 이는 컴파일러가 명령어를 배치할 때 “이 값은 어느 파티션에서 살아야 하나”까지 함께 결정해야 한다는 것을 의미하고, VLIW 컴파일러를 어렵게 만드는 요인 중 하나입니다.
Explicit Parallel Programming과 “Very Long Instruction Word”
이 구조 위에서 코드를 짤 때, VLIW는 시퀀셜한 명령어 한 줄에 한 가지 일을 시키는 식이 아니라, 한 번에 여러 Functional Unit이 무엇을 할지를 명시적으로(Explicit) 한꺼번에 표현합니다. 즉 “한 cycle = 여러 명령어 묶음”이고, 각 묶음 안에는 해당 cycle에 각 유닛이 수행할 동작이 그대로 들어 있습니다.
예를 들어 한 cycle에 3개의 Functional Unit이 동시에 동작한다면, 명령어 한 묶음 안에 3개의 Sub-instruction이 함께 묶여 있고, 다음 cycle에는 또 다른 3개가 묶음으로 표현되는 식입니다. 이렇게 묶음 단위로 진행되는 명령어 흐름이 곧 앞에서 본 VLIW Loop Pipeline 그림과 같은 모양을 만들어 냅니다.
이렇게 한 번에 하드웨어 전체를 제어하기 위한 명령어가 매우 길어지기 때문에, 이 아키텍처에 Very Long Instruction Word(VLIW)라는 이름이 붙은 것입니다. 다음 절에서는 이 “한 명령어로 여러 유닛을 동시에 제어하는” 표현 방식이 RISC/CISC와 어떻게 다른지를 인코딩 관점에서 정리해 봅니다.
Very Long Instruction Word (VLIW): Horizontal Encoding
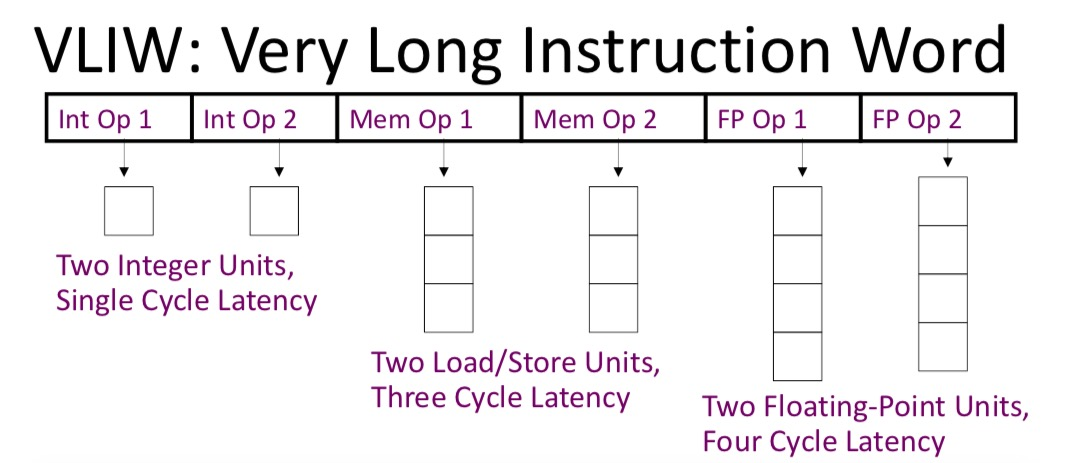
이 절의 제목인 “Very Long Instruction Word”는 이름 그대로, 한 cycle에 하드웨어 전체에게 무엇을 시킬지가 한 줄에 길게 적혀 있는 명령어 형식을 가리킵니다. 이 형식을 인코딩 관점에서 보면, 앞서 Instruction-Level Pipelining 절에서 다뤘던 Vertical Encoding의 정반대 방향에 위치합니다. 그래서 이 방식을 흔히 Horizontal Encoding이라고 부릅니다.
| Vertical Encoding (RISC/CISC) | Horizontal Encoding (VLIW) | |
|---|---|---|
| 명령어가 담은 정보 | 어떤 동작을 할지가 비트 단위로 인코딩되어 압축되어 있음 | 하드웨어의 각 유닛이 그 cycle에 무엇을 할지 펼쳐서 그대로 적혀 있음 |
| 하드웨어 매핑 | 디코딩 단계를 거쳐야 비로소 어떤 유닛이 어떤 일을 할지가 결정됨 | 명령어 자체가 Datapath 구조와 1:1로 대응 |
| 누가 결정하나 | 하드웨어가 디코딩하면서 신호를 분기 (① 접근) | 소프트웨어(컴파일러)가 명시적으로 미리 결정 (② 접근) |
쉽게 말해 Vertical Encoding은 “무엇을 할지 짧게 적어 두면, 디코더가 알아서 풀어서 하드웨어 곳곳에 보내겠다”는 방식이고, Horizontal Encoding은 “하드웨어 각 부분이 매 cycle 무엇을 할지를 소프트웨어가 직접 표 형식으로 늘어놓겠다”는 방식입니다. VLIW의 명령어가 Very “Long”인 이유가 바로 이것입니다.
Vertical vs. Horizontal Microcode
두 방식의 차이는 microinstruction에서 datapath로 신호가 흘러가는 모양을 보면 가장 분명히 드러납니다.
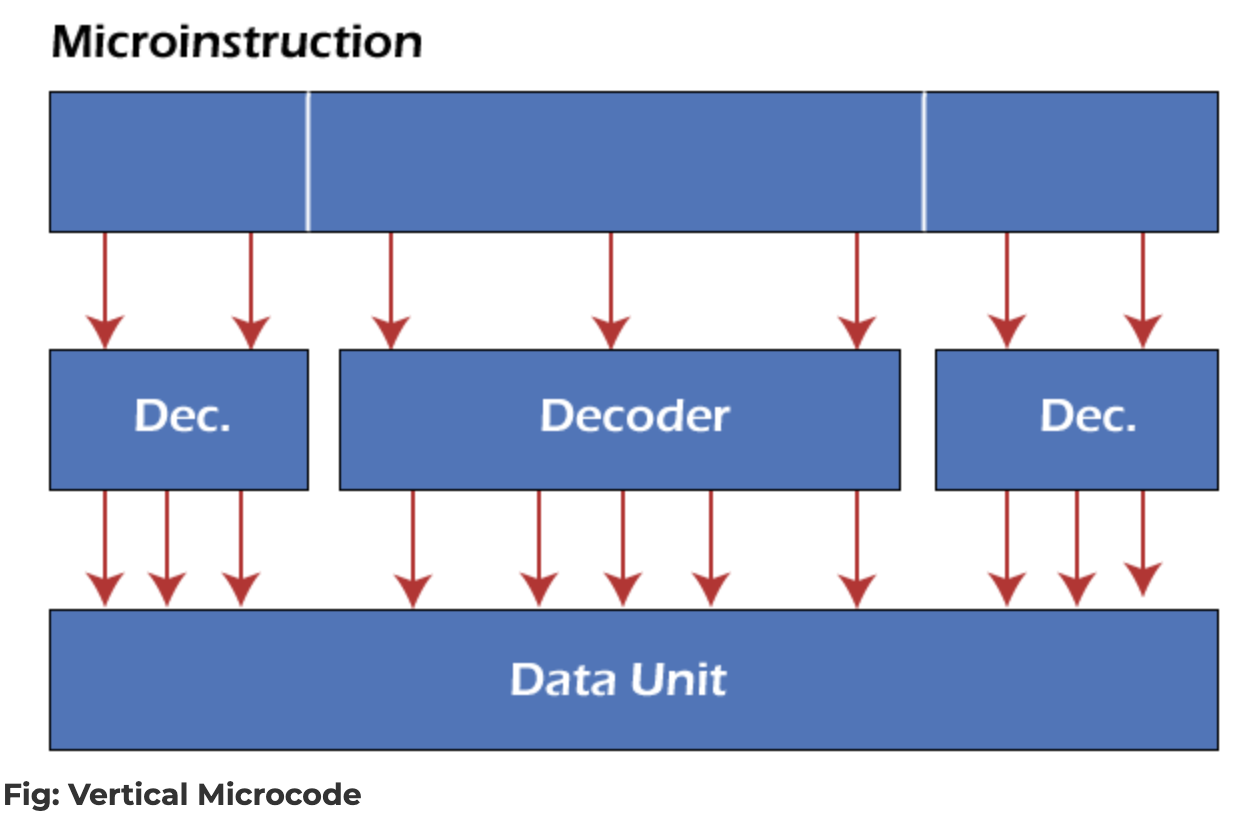
microinstruction이 여러 Decoder를 거쳐 Data Unit의 신호로 펼쳐짐
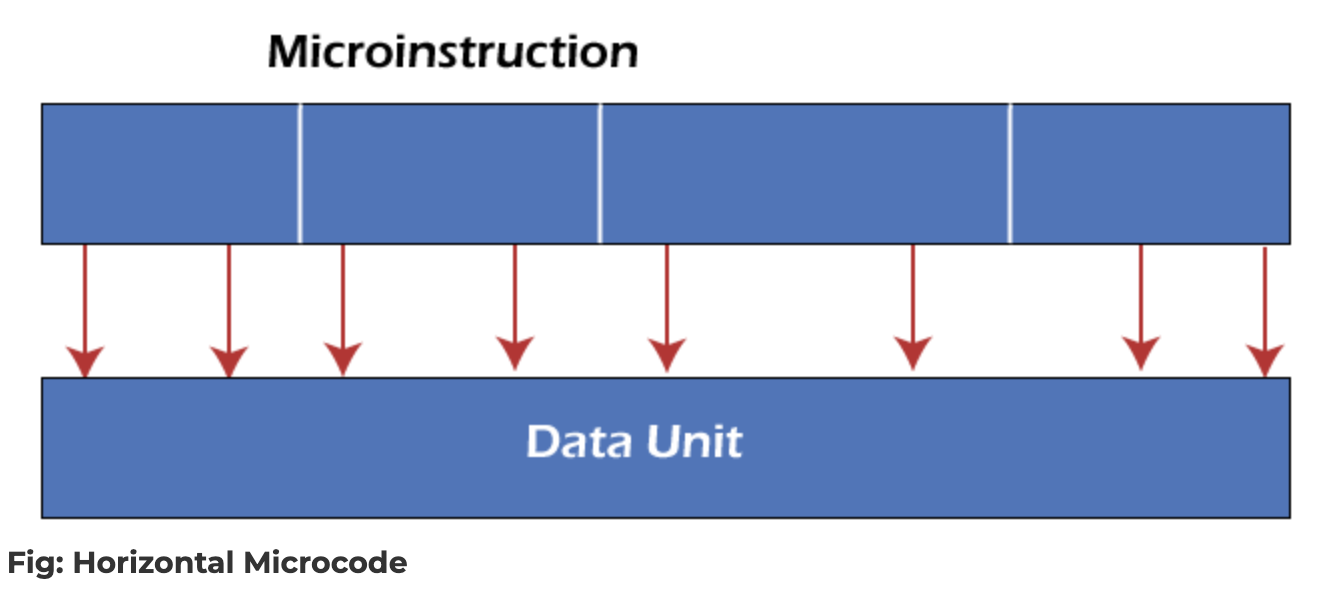
microinstruction의 각 비트 묶음이 Decoder 없이 곧장 Data Unit의 각 부분으로 연결
두 방식 모두 Can Be Hierarchical. 인코딩 방식은 둘 중 하나만 쓰이지 않고 계층적으로 결합될 수 있습니다.
왼쪽 Vertical은 명령어를 받아 Decoder가 하드웨어 제어 신호로 펼쳐 주는 형태이고, 오른쪽 Horizontal은 명령어 비트가 곧장 Data Unit의 각 부분에 직결되는 형태입니다.
두 방식은 서로 배타적이지 않다 (계층적 결합)
흥미로운 점은, 이 둘이 완전히 분리된 선택지가 아니라 하나의 시스템 안에서 계층적으로(hierarchical) 같이 쓰일 수 있다는 것입니다. 흔히 쓰이는 절충은 다음과 같습니다.
- 상위 레벨에서는 Horizontal Encoding으로 “어떤 유닛이 어떤 묶음에 참여하는지” 전체 구조를 명시적으로 펼쳐 둔다
- 각 묶음 안의 개별 유닛에 들어가는 명령어는 Vertical Encoding으로 짧게 인코딩하고, 그 단위에서는 디코더가 다시 하드웨어 제어 신호로 풀어낸다
이 절충 덕분에 명령어 길이가 무한정 길어지는 것을 막으면서도, “여러 유닛을 한 cycle에 동시에 제어한다”는 VLIW의 본질은 유지할 수 있습니다.
진짜 결정적 차이: HW 디테일을 어디까지 SW에 노출하는가
계층적 결합이 가능하다는 사실보다 더 본질적인 차이가 있습니다. Horizontal Encoding은 하드웨어의 디테일 자체를 그대로 소프트웨어에 노출한다는 점입니다. 명령어의 각 비트가 어느 유닛에 직결되는지가 ISA 차원에서 보이기 때문에, 그 코드를 만드는 컴파일러나 프로그래머가 하드웨어 구조를 깊이 이해하고 있어야 합니다. 어떤 유닛이 매 cycle 무엇을 할지를 명시적으로 코딩해 줘야 하는 것입니다.
반면 Vertical Encoding은 짧은 명령어 뒤에 디코더가 모든 디테일을 흡수하므로, 소프트웨어는 하드웨어 구조를 몰라도 코드를 작성할 수 있습니다. 강의 초반에 본 「프로세서 설계의 핵심 질문」으로 다시 돌아가면, Vertical = ① Microarchitecture 최적화 의존, Horizontal = ② Compiler/Programmer 최적화 의존이라는 매핑이 정확히 여기에서 성립합니다. 즉 인코딩 방식의 선택은 단순한 비트 배치 문제가 아니라, 하드웨어와 소프트웨어 사이의 책임을 어디에서 끊을 것인가라는 설계 철학의 선택입니다.
Modulo Scheduling: SW Pipelining의 핵심
지금까지 본 VLIW 기법들(Loop Pipeline, Horizontal Encoding, Functional Unit 병렬 제어)은 사실 꽤 오래된 아이디어입니다. 그리고 이 모든 것을 컴파일러가 실제로 만들어 내기 위해 사용하는 가장 대표적인 알고리즘이 바로 Modulo Scheduling(대표적인 구현이 Iterative Modulo Scheduling)입니다.
이 알고리즘의 개념은 1980년대에 Bob Rau가 처음 만들었고, 그가 HP Labs에 있을 때 잘 정리해서 1994년 논문으로 발표했습니다.
B. Ramakrishna Rau, “Iterative modulo scheduling: an algorithm for software pipelining loops,” Proceedings of the 27th Annual International Symposium on Microarchitecture (MICRO-27), 1994.
알고리즘이 워낙 잘 설계되어 있어서, 비슷한 구조의 아키텍처를 다루는 거의 모든 컴파일러가 이 틀 위에서 SW Pipelining을 구현합니다.
알고리즘이 도입한 주요 개념들
이 강의에서 알고리즘 자체를 깊게 다루지는 않습니다. 대신, Bob Rau가 제안한 여러 가지 주요 개념들이 어떤 모양인지를 그림으로 한 번 훑고 넘어갑니다. 아래 두 그림이 그 전체 그림을 압축해서 보여 줍니다.
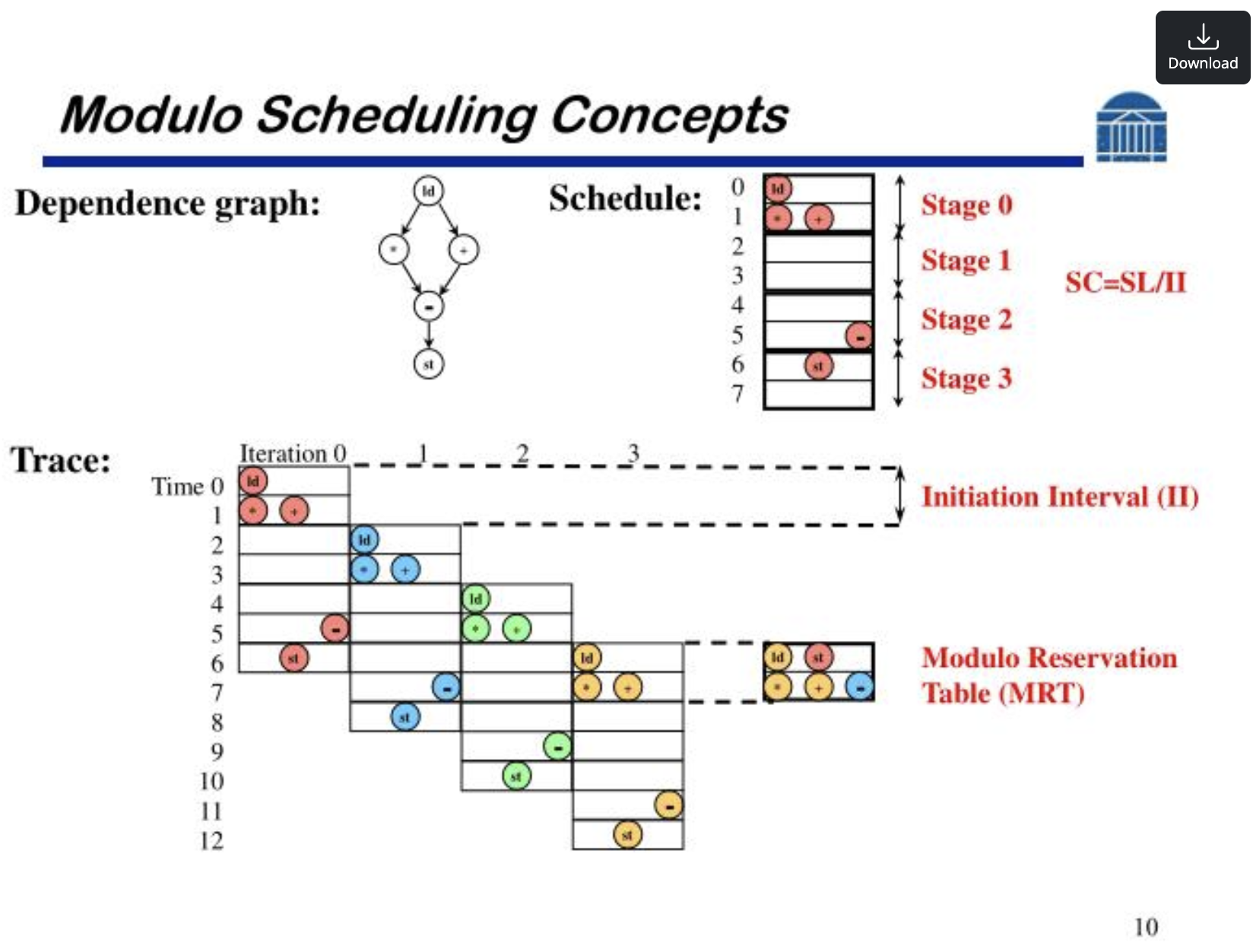
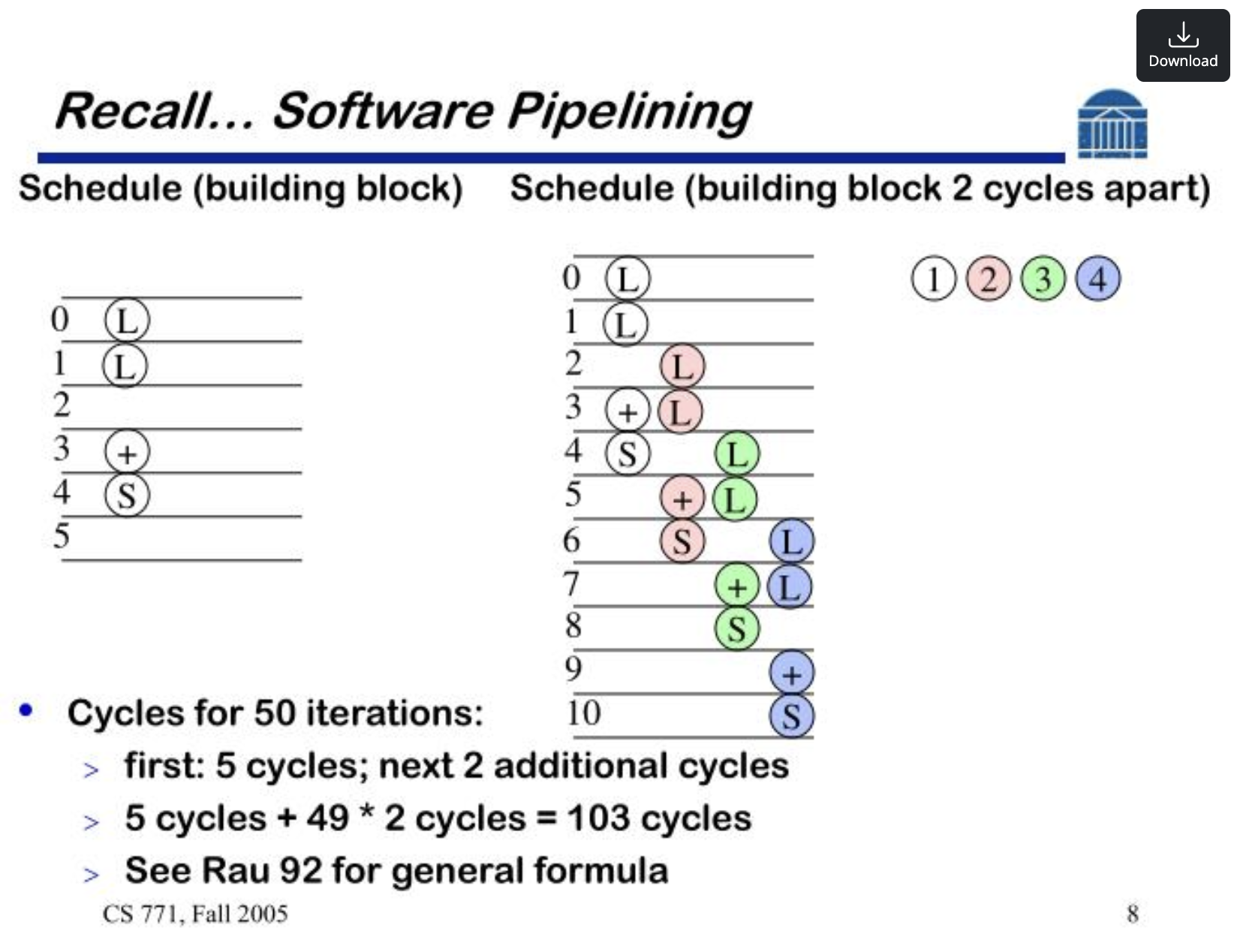
요약하면 이렇습니다. Dependence Graph(명령어 간 의존성)와 Schedule(매 cycle 어떤 명령어가 어떤 stage에 들어가는지), 그리고 그것을 Initiation Interval(II) 마다 모듈로 패턴으로 반복시키며 자원 충돌을 추적하는 Modulo Reservation Table(MRT), 이 개념들이 한 묶음으로 작동해서, 컴파일러가 루프를 파이프라인된 형태로 배치하고 그 위에 새로운 iteration을 일정 간격으로 계속 흘려보낼 수 있게 만듭니다. 슬라이드 두 번째에 나오는 “50 iterations → 5 cycles + 49 × 2 cycles = 103 cycles” 같은 예시가 그 효과를 그대로 보여 주는 사례입니다.
직관적으로 보면, Modulo Scheduling은 OOO Processor가 하드웨어적으로 매 cycle 동적으로 만들어내던 그 일(루프 iteration들의 명령어를 펼쳐서 의존성에 맞게 재배치하고, 매 cycle 무엇이 동시에 실행될 수 있는지 결정하는 일)을, 컴파일러가 정적으로 한 번에 풀어내는 알고리즘입니다. 즉 OOO 안의 Reservation Station / Renaming Table / Reorder Buffer 가 동적으로 유지하던 “데이터 플로우 그래프 + 자원 할당 + 시점 결정” 의 역할을, 컴파일 타임에 Dependence Graph + MRT + Schedule 형태로 미리 풀어 놓는다고 보면 정확합니다. 앞 절에서 본 “OOO와 똑같은 결과를 SW가 미리 만들어 둔다”는 발상이 실제 실행 가능한 형태로 구현되는 곳이 바로 여기입니다.
Reconfigurable Architecture (Extreme VLIW)
최근에는 VLIW를 Reconfigurable Processor라고 부르기도 합니다. 이름이 바뀌는 이유는 그렇게 거창하지 않습니다. Horizontal Encoding의 본질을 다시 떠올려 보면, 명령어가 하드웨어의 각 부분이 매 cycle 무엇을 할지를 직접 지정하고 있죠. 이건 보기에 따라 그 cycle에 하드웨어를 어떤 모양으로 작동하게 할지를 소프트웨어가 매번 다시 그려 주는 것과 같습니다. 즉 매 cycle마다 하드웨어를 다른 용도로 재구성(reconfigure)하는 셈인 것입니다.

이 관점을 더 극단으로 밀고 나가면 어떻게 될까요? 하드웨어가 더 잘게 분산되어 있고, 각 부분의 디테일이 소프트웨어에 더 많이 노출되어 있으며, 그 모든 부분을 매 cycle 명시적으로 제어할 수 있다면, 이건 사실상 일반 VLIW를 넘어 하드웨어를 매 cycle 재구성하는 데 특화된 프로세서가 됩니다. 이런 형태가 바로 Reconfigurable Architecture, 즉 Extreme VLIW 입니다.
이 개념이 단순한 학술적 이상으로만 남아 있는 것은 아닙니다. 최근 출시되는 많은 NPU들이 바로 이 Reconfigurable Architecture 개념에 맞춰 설계되고 있습니다. 강의 후반부에서 NPU의 구조와 프로그래밍 모델을 살펴볼 때, 이 절의 “Horizontal Encoding → 하드웨어 재구성 → 컴파일러 책임 증가” 라는 흐름이 그대로 다시 등장하는 것을 보게 될 것입니다.
Loop-Level Pipelining 정리
지금까지 다룬 내용을 크게 세 가지로 정리할 수 있습니다.
- Loop Pipelining = loop iteration을 중첩, Latency Hiding - 한 iteration이 끝나기 전에 다음 iteration을 시작해 명령어 실행을 겹치는 것이 요점. 거의 모든 프로그램이 실행 시간을 루프에 쏟기 때문에, 이 효과를 잘 내는 것이 곧 성능 향상의 관건이 됩니다.
- Out-of-Order Processor에서는 하드웨어가 동적으로 자연스럽게 이 효과를 만들어냅니다. 그 이론적 기반은 1960년대의 Tomasulo Algorithm으로, 오늘날의 ROB·Reservation Station·Renaming Table까지 곧장 이어집니다.
- VLIW (또는 Reconfigurable) Processor에서는 소프트웨어(컴파일러)가 정적으로 이 효과를 만들어냅니다. 대표적인 컴파일러 알고리즘이 1994년의 Iterative Modulo Scheduling입니다.
정적 접근(VLIW)의 장단점
같은 효과를 SW가 미리 만들어 두는 방식의 장단점도 짚어 두면 좋습니다.
- 장점
- 하드웨어가 훨씬 단순해집니다 (Branch Prediction, Reorder Buffer, Rollback 같은 동적 장치 불필요).
- 컴파일 타임에 더 다양한 스케줄·최적화 옵션을 충분히 탐색할 수 있어, 잘 짜인 워크로드에 대해서는 더 최적화된 코드를 만들 수 있습니다.
- 단점
- Integer 프로그램(워드프로세서·웹브라우저류, 즉 Intel CPU에서 흔히 도는 코드)처럼 분기가 많고 동적 이벤트가 많은 워크로드에는 약합니다. 루프 안에 분기가 들어 있으면 의존성을 정적으로 풀기가 까다로워지고, 캐시 미스 같은 이벤트도 컴파일 타임에 모두 고려하기 어렵습니다.
- 분기를 줄이기 위해 Predication 같은 기법을 도입할 수 있지만, 결국 컴파일러 복잡도가 그만큼 올라갑니다.
- 하드웨어가 단순한 만큼, 코드가 충분한 병렬성을 갖지 못한 경우에는 하드웨어가 그것을 보완해 줄 방법이 없습니다. 프로그램을 다시 짜거나 더 강력한 컴파일러를 쓰는 수밖에 없습니다.
요약하면 Integer-heavy한 워크로드에서는 동적(OOO) 접근이 일반적으로 더 효율적이고, 반복적이고 의존성이 깔끔한 워크로드(많은 ML / DSP / 미디어 처리 등)에서는 VLIW 계열이 잘 맞습니다.
Q&A
강의 중 나온 질문들을 정리합니다.
Q. VLIW 프로세서에서 동작시킬 소프트웨어를 위한 지정된 언어가 있나요? 아니면 컴파일러로 지정 가능한가요? 우리가 흔히 말하는 Integer 프로그램은 결국 C/C++ 같은 기존 언어로 짜여 있고, VLIW 프로세서가 그런 프로그램을 타깃하려면 그 언어들을 그대로 지원해야 합니다. 따라서 “VLIW 전용 언어”가 따로 있다기보다는, 순차 코드(C/C++ 등)를 받아 병렬 파이프라인 형태로 변환하는 컴파일러 기법이 핵심입니다.
Q. VLIW 구조에 잘 맞지 않는 코드는 버블이 발생할 텐데, 별도로 처리해 주는 방법이 있나요? 안타깝게도 하드웨어 단에서 보완해 줄 방법은 거의 없습니다. VLIW는 애초에 하드웨어를 단순하게 만들기 위해 도입되는 구조라, 코드가 충분한 병렬성을 제공하지 못하면 그대로 손실로 이어집니다. 정공법은 프로그램을 다시 짜거나 더 고도화된 컴파일러를 쓰는 것이고, 특히 루프 안 분기가 문제일 때는 Predication으로 분기를 평탄화해 SW Pipelining을 적용할 수 있도록 ISA가 보조 기법을 함께 제공하기도 합니다.
Q. TPU나 Tensor Core의 Systolic Array 같은 하드웨어 블록 프로그램에는 VLIW가 유리한가요? Systolic Array는 VLIW와는 꽤 다른 형태의 가속기로 보는 편이 정확합니다. 더 극단적으로 프로그래머빌리티 측면의 제약이 크지만, 하드웨어 효율 자체는 훨씬 높습니다. 가지고 있는 프로그래밍 모델 자체가 VLIW와 다르기 때문에, “VLIW가 유리하냐 아니냐”의 문제라기보다는 별도의 갈래로 이해하는 것이 맞습니다.
이 두 접근(HW 동적 / SW 정적)의 대비는 이후 살펴볼 GPU와 NPU의 설계 철학 차이로 그대로 이어집니다.
Thread-Level Pipelining: Multi-Core, GPU, NPU
지금까지 우리는 두 가지 단위에서 Latency Hiding을 이야기했습니다. Instruction-level pipelining에서는 한 명령어 안의 stage들을 겹쳤고, Loop-level pipelining에서는 루프의 서로 다른 iteration들을 겹쳤습니다. 이제부터 다룰 것은 그보다 한 단계 더 큰 단위, Thread-level pipelining 입니다. 그리고 이 절은 자연스럽게 GPU와 매우 밀접하게 연관됩니다. GPU의 설계 철학이 본질적으로 Thread 수준의 Latency Hiding을 극대화하는 방향으로 만들어져 왔기 때문입니다.
Instruction-level과 Loop-level pipelining에 이어, 가장 큰 규모의 Latency Hiding이 Thread 수준에서 이루어집니다. 이 전환의 배경에는 CPU 아키텍처의 중요한 변곡점이 있습니다.
CPU의 변곡점: Clock Frequency Scaling의 종료
Thread-level 이야기로 본격적으로 넘어가기 전에, 잠깐 시계를 GPU가 막 등장하던 시점으로 되돌려서 빌드업을 해 보겠습니다.
1990년대: ILP의 황금기
1990년대는 CPU·프로세서 설계자들에게 정말로 흥미로운 시기였습니다. Intel 프로세서가 세대를 넘길 때마다 클럭 속도가 눈에 띄게 빨라졌고, 새로운 아키텍처 아이디어들이 빠르게 칩에 반영되어 프로세서가 무서운 속도로 발전하던 때입니다.
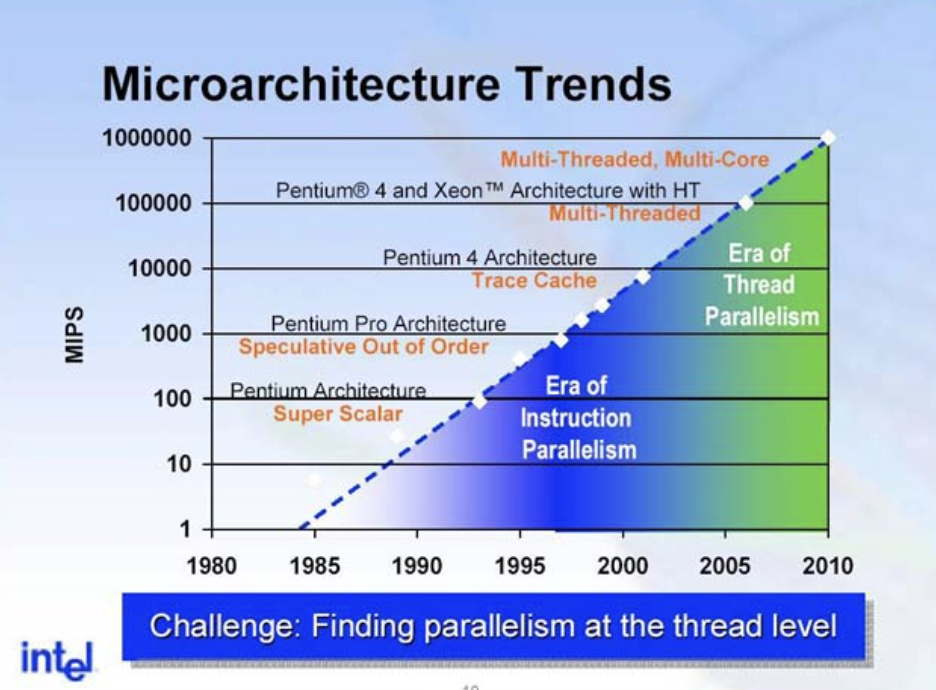
이 시기의 구조적 개선은 거의 전부 명령어 수준의 중첩(Overlap)을 어떻게 더 잘 짜낼 것인가에 집중되어 있었습니다. 앞서 다룬 두 축이 정확히 이 시기에 정착됩니다.
- 한 명령어를 어떻게 stage로 잘게 나눠 파이프라인할 것인가 (Instruction-Level Pipelining)
- 여러 명령어를 어떻게 잘 중첩해 동시에 실행할 것인가 (OOO를 통한 Loop-Level Pipelining)
이 둘을 통틀어 Instruction-Level Parallelism (ILP) 라고 부르고, 1990년대~2000년대 초의 CPU 설계는 이 ILP를 극대화하는 데 많은 자원과 시간을 쏟아부었습니다. 그림에서도 1990년대 영역이 “Era of Instruction Parallelism” 으로 표시되어 있습니다.
2000년대: Clock Frequency 경쟁의 끝
그러나 이 흐름이 영원하지는 않았습니다. 그 한계가 가장 상징적으로 드러난 사건이 바로 Pentium 4의 실패입니다. Pentium 3까지의 성공 방정식을 그대로 한 번 더 적용해 보려고, 파이프라인을 더 깊게 파고, 클럭을 더 끌어올리고, OOO 엔진을 더 복잡하게 만들면서 ILP를 극단까지 짜내려 한 것이 Pentium 4였는데, 결국 클럭을 무리하게 올린 데서 비롯된 발열 문제로 인텔이 대대적으로 실패한 대표 사례가 되었습니다.
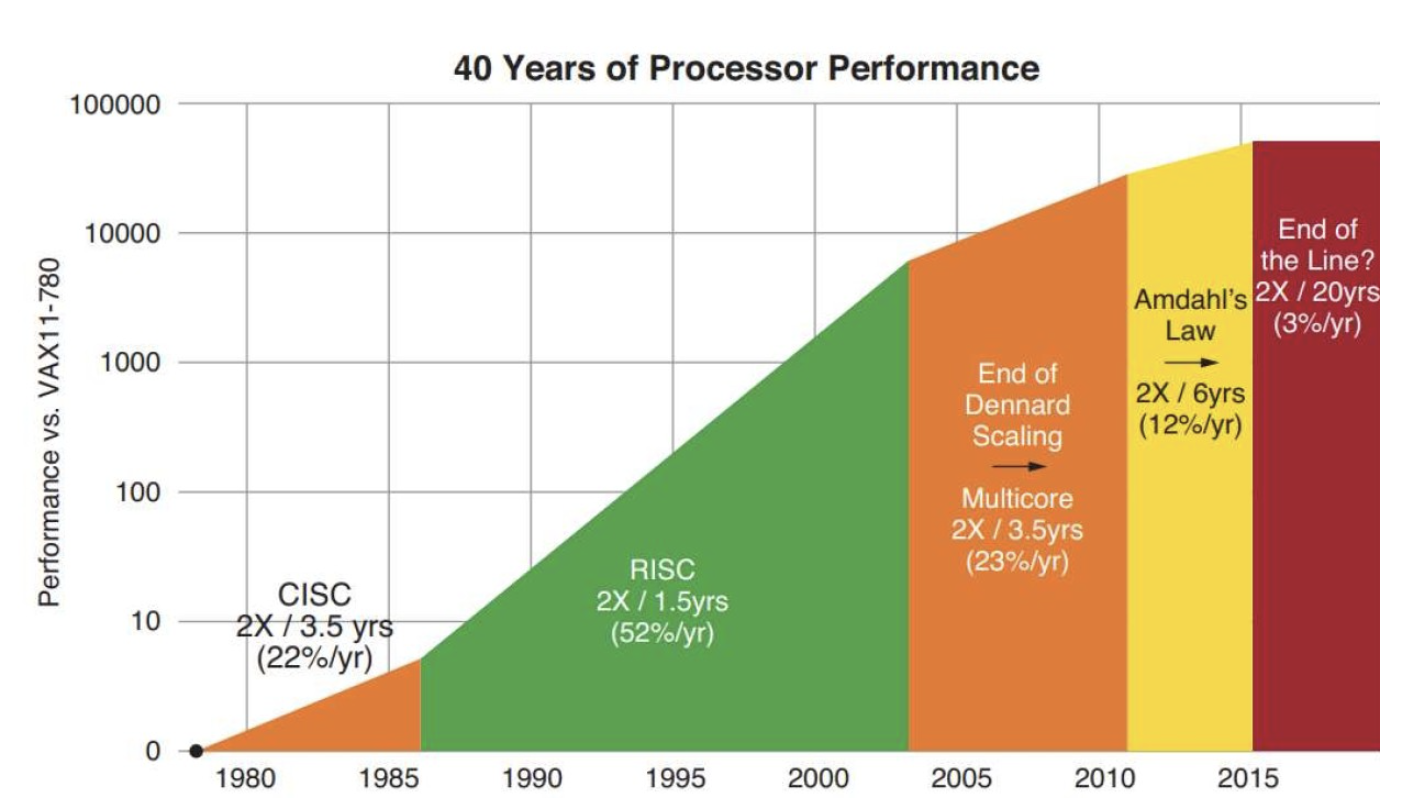
이 발열 문제의 근본 원인이 바로 Dennard Scaling의 한계입니다. 우리는 공정 미세화 덕분에 트랜지스터 자체는 점점 작게 만들 수 있지만, 빠져나가는 전력은 트랜지스터 크기에 비례해 줄어들지 않습니다. 트랜지스터 집적도가 올라가고 클럭 주파수가 함께 올라갈수록 단위 면적당 열 밀도가 빠르게 증가하고, 이를 더 이상 식혀 낼 수 없는 지점에 도달하면 결국 칩이 버티지 못합니다. 이런 현상이 누적되며 “클럭을 더 끌어올리는 게임” 자체가 2000년대에 사실상 종료됩니다.
마침 같은 시기에 인터넷과 서버 시장이 폭발적으로 성장하면서, 시스템에 요구되는 워크로드의 성격도 함께 바뀝니다. 단일 명령어 스트림 안에서 ILP를 더 짜내는 것보다, 서로 독립적인 큰 작업(요청, 세션, 사용자)을 여러 개 동시에 처리할 수 있는 프로세서가 훨씬 중요해진 것입니다. 그래서 Intel은 ILP 추구를 접고 Multi-Core + Multi-Threading 방향으로 깔끔하게 전환했고, 이 전환은 매우 성공적이었습니다. 그림에서 2000년대 후반 영역이 “Era of Thread Parallelism” 으로 바뀌어 있는 것이 바로 이 변화를 그대로 보여 줍니다. 그 기조는 지금도 그대로 유지되고 있어서, 2000년대 이후 Intel 프로세서는 한 칩 안에 점점 더 많은 코어를 담는 방향으로 진화해 왔습니다.
Memory Wall: DRAM Bandwidth를 어떻게 최대한 활용하느냐?
Thread-level 병렬 아키텍처가 특히 서버 시장에서 중요해진 이유 중 하나는, 그 시장이 단순한 ILP가 아니라 메모리 시스템 전체를 어떻게 잘 굴리느냐의 게임이기 때문입니다. 그 그림을 보려면 우선 일반적인 프로세서의 메모리 계층 구조를 떠올려 봐야 합니다.
위에서부터 차례대로 보면, 실제 연산을 담당하는 Compute Unit들이 가장 위에 있고, 그 밑에 빠른 On-Chip Memory(CPU의 경우 보통 Cache)가 있고, 가장 아래에 DRAM 같은 오프칩 메모리가 자리합니다. 위로 갈수록 빠르고 작고, 아래로 갈수록 느리지만 큰, 이것이 우리가 흔히 부르는 Memory Hierarchy 입니다.
문제는 현대 프로세서에서 가장 큰 성능 병목이 바로 이 오프칩 메모리(DRAM)에 접근할 때의 Bandwidth와 Latency라는 점입니다. 연산 능력은 세대를 거치며 계속 향상되지만, DRAM에 접근하는 속도는 그 속도를 따라가지 못합니다. 이 현상을 가리키는 용어가 바로 Memory Wall 이고, 1994년경에 처음 등장한 표현으로 알려져 있습니다. 결국 프로세서 설계의 과제는 한 줄로 요약됩니다. “DRAM Bandwidth를 어떻게 최대한 활용할 것인가?”


이 Memory Wall을 가장 효과적으로 풀어내는 방법으로 잘 알려진 것이 바로 Multithreading 입니다.
Multithreading을 활용한 Memory Latency Hiding
앞에서 말한 것처럼, Memory Wall 문제를 가장 효과적으로 풀어낼 수 있는 방법 중 하나가 Multithreading입니다.
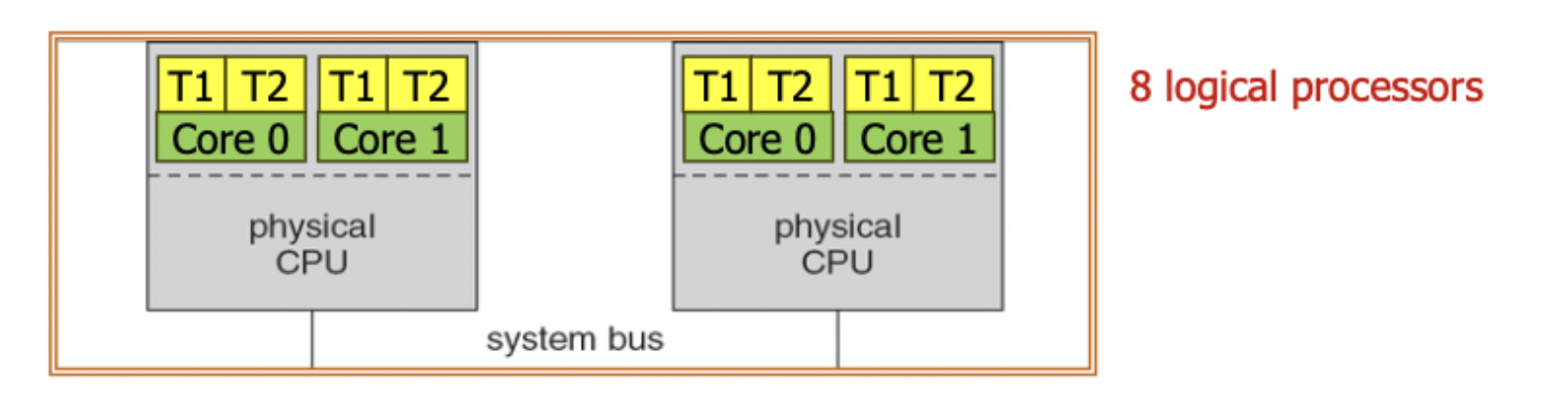

하나의 스레드가 메모리 접근으로 대기 중일 때, 즉시 다른 스레드를 실행합니다. 이렇게 하면 메모리 접근의 긴 Latency를 다른 유용한 작업으로 채울 수 있어, 전체 Throughput이 향상됩니다.
GPU: Massive Parallelism으로 Latency를 숨기다
CPU가 Multi-Core로 전환하던 같은 시기인 2000년대에, 그래픽스 프로세서도 큰 변화를 겪고 있었습니다.
Fixed-Function에서 Programmable Device로
흥미롭게도 GPU의 결정적인 전환은 Intel CPU가 Dennard Scaling 벽에 부딪혀 Multi-Core + Multi-Threading 으로 방향을 트는 그 시기와 거의 정확히 같은 시점인 2000년대에 일어납니다. 그래픽스 프로세서가 Fixed-Function 하드웨어에서 Programmable Device로 변신한 시점이 바로 이때입니다.
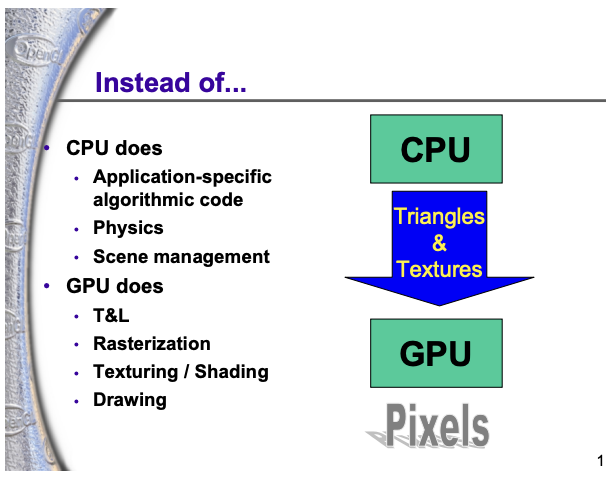
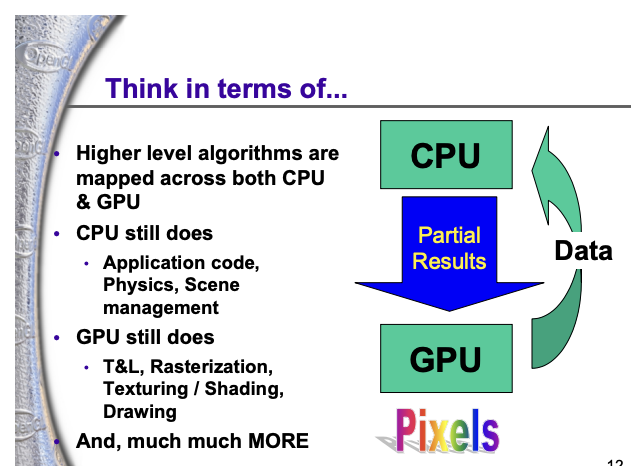
이 변화의 중심에는 Shader Programming의 등장이 있습니다. 이전 GPU는 미리 정해진 그래픽스 파이프라인 연산(정해진 종류의 변환·조명·텍스처링 등)만 처리할 수 있는 Fixed-Function 디바이스였지만, Shader가 도입되면서 개발자가 GPU의 동작을 일정 범위 안에서 직접 프로그래밍할 수 있게 되었습니다. CPU가 ILP의 한계 앞에서 “한 칩에 여러 일을 동시에”라는 방향으로 전환하던 바로 그 시기에, GPU도 “정해진 일만 하는 가속기”에서 “개발자가 짠 코드를 대규모로 병렬 실행하는 프로세서”로 변신하기 시작한 것입니다.
CPU vs GPU: 설계 철학의 차이
GPU가 노리고 있는 그래픽스 워크로드는 본질적으로 픽셀이나 삼각형(triangle) 단위의 엄청나게 많은(abundant / massive) 병렬성을 가지고 있습니다. GPU는 이 풍부한 병렬성을 그대로 활용하는 데 초점을 맞추는 방향으로 진화했고, 그 결과 CPU와는 매우 다른 설계 선택을 하게 됩니다.
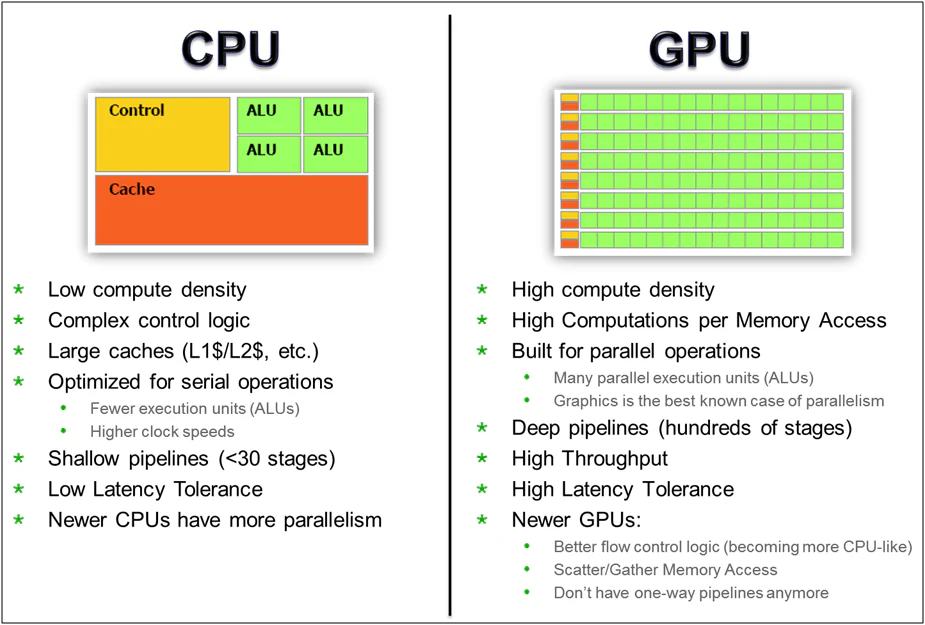
CPU와 비교해서 GPU의 특징을 정리하면 이렇습니다.
- Computing Density (연산 밀도) - GPU가 CPU보다 훨씬 높습니다. 같은 면적/전력 안에 더 많은 연산 유닛을 욱여넣습니다.
- 동시 처리 가능한 스레드 수 - GPU가 CPU보다 압도적으로 많습니다. 한 GPU 안에서 수천~수만 개 스레드가 동시에 in-flight 상태로 존재합니다.
- Control 단순화 - CPU가 단일 스레드 성능을 끌어올리려고 OOO 엔진·Branch Predictor·Reorder Buffer 같은 부가 장치를 잔뜩 짊어진 반면, GPU는 그 장치들을 과감히 덜어냅니다. 한 스레드가 좀 오래 걸려도 상관없으니, 대신 여러 스레드를 한꺼번에 효율적으로 흘리는 데 최적화된 아키텍처를 선택한 것입니다.
한 줄로 줄이면, CPU는 단일 스레드 Latency 최소화에 가까운 길을 가고, GPU는 Throughput 극대화에 모든 것을 거는 길을 갑니다. 메모리 Latency는 앞 절에서 본 Multithreading으로 가립니다. 한 스레드가 메모리에서 기다릴 때, 그 자리에 즉시 다른 스레드를 끼워 넣어 연산 유닛이 노는 시간을 줄이는 것입니다. 이렇게 GPU와 CPU는 같은 시기에 갈라져 굉장히 극명하게 다른 길을 걷기 시작합니다.
CUDA와 SIMT
Shader Programming에서 출발한 GPU의 진화는, CUDA가 정의되는 시점에서 결정적으로 완성됩니다. CUDA는 Shader 시절부터 다듬어진 GPU의 아키텍처적 개념들을 소프트웨어가 이해할 수 있는 프로그래밍 모델로 잘 정리한 것입니다. NVIDIA는 이 모델을 2007년경에 발표했고, 이때부터 GPGPU 시대가 본격적으로 열립니다.
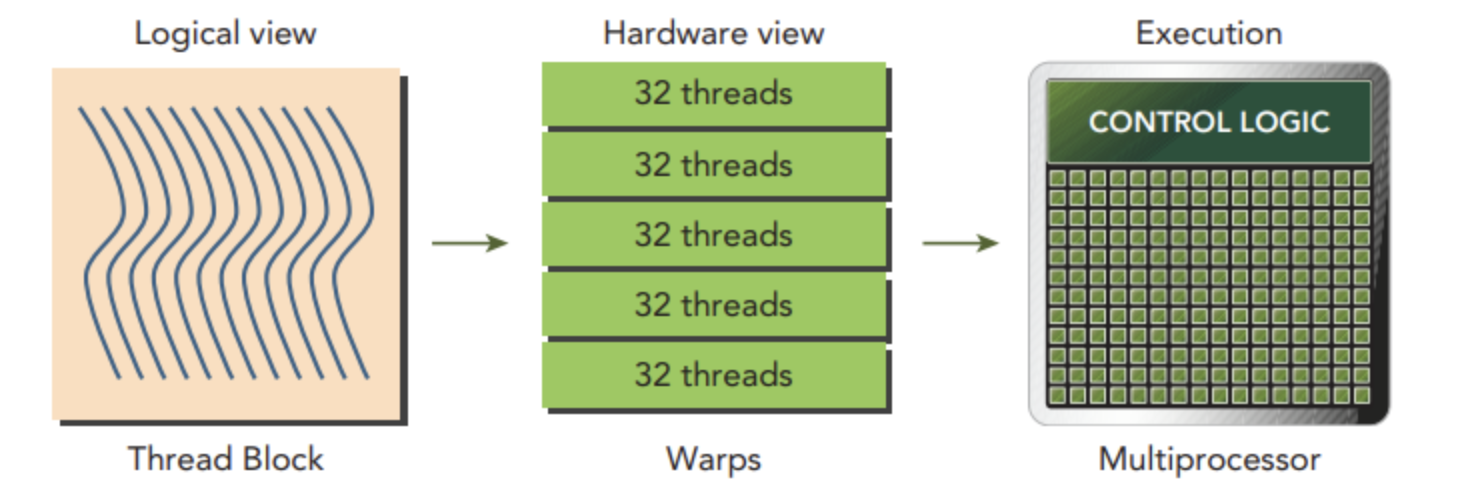
CUDA가 제시한 실행 모델이 바로 SIMT (Single Instruction Multiple Threads) 입니다. 같은 명령어를 여러 스레드가 함께 실행한다는 점에서 익숙한 SIMD (Single Instruction Multiple Data)와 구조적으로 크게 다르지는 않지만, NVIDIA GPU 특유의 메모리 Latency Hiding 메커니즘에 맞게 특화된 이름이 SIMT라고 보면 됩니다.
ThreadBlock, Warp, Multiprocessor
SIMT 모델의 기본 단위는 다음과 같습니다.
- Thread - 가장 작은 실행 단위. 프로그래머는 CUDA로 수많은 Thread를 SIMT 형태로 짭니다.
- Warp - 같은 명령어를 함께 실행하는 스레드 묶음(NVIDIA 구현에서는 보통 32개). Warp 단위로 하드웨어가 명령어를 발행합니다.
- ThreadBlock - Warp들을 묶은 그룹. 같은 ThreadBlock 안의 스레드들은 공유 메모리·동기화 같은 자원을 함께 쓸 수 있습니다.
- Streaming Multiprocessor (SM) - Warp들을 실제로 흘려 보내는 하드웨어 단위. 여러 ThreadBlock을 동시에 in-flight 상태로 들고 있으면서 매 cycle 실행할 Warp을 골라냅니다.
Latency Hiding 메커니즘
CUDA 프로그래머가 굉장히 많은 Thread를 작성해 두면, GPU는 이를 다음과 같이 굴립니다. 어떤 Thread/Warp이 실행되다가 Cache Miss나 메모리 접근 같은 긴 Latency 이벤트를 만나면, 그 Warp은 일시 중단되고 SM은 즉시 실행 가능한 다른 Warp으로 전환해 연산 유닛을 계속 가동합니다. 그러다가 처음 Warp이 기다리던 메모리 접근이 끝나면 그 Warp은 다시 후보 큐에 들어가 실행됩니다.
이 구조의 핵심 전제는 언제든 갈아 끼울 수 있는 다른 Warp이 충분히 많다는 것입니다. 그래서 GPU는 OOO Processor처럼 한 스레드의 Latency를 줄이려고 애쓰는 대신, 항상 in-flight 상태의 Thread를 풍부하게 유지해 매 cycle 실행 유닛이 노는 일이 없도록 만드는 방향으로 설계됩니다. 이것이 GPU가 “메모리 접근이 느려도 Throughput만큼은 절대 떨어뜨리지 않는” 비결이고, 다음 절에서 다룰 “GPU = All About Hiding Latency” 의 가장 직접적인 구현입니다.
GPU: All About Hiding Latency
지금까지 본 흐름을 한 줄로 줄이면, GPU는 “All About Hiding Latency”라고 부를 수 있을 정도로 메모리 Latency 문제 하나를 위해 만들어진 아키텍처입니다. 그래픽스 워크로드의 풍부한 병렬성을 SIMT 모델로 노출하고, 그 위에서 Warp 단위 스케줄링과 풍부한 in-flight 스레드를 동원해 메모리 접근으로 인한 빈 cycle을 채워 넣는, 이 모든 설계 결정이 결국 “느린 DRAM에도 불구하고 연산 유닛을 놀리지 않는다”라는 한 가지 목표로 수렴합니다.

물론 한 가지 단서를 달아 둘 필요가 있습니다. 우리가 지금 이야기하는 GPU의 일반적 특성은 사실 2000년대에서 2010년대 사이에 그래픽스 워크로드를 기준으로 정의된 모습에 가깝습니다. 최근의 GPU는 ML 워크로드의 특성에 맞춰 빠르게 변모하고 있고, 내부 구조가 모두 공개되지는 않기 때문에 위에서 정리한 특성들이 어디까지 그대로 유지되는지는 외부에서 정확히 단정하기 어렵습니다. 특히 “All About Hiding Latency” 라는 측면에서는 현재 세대에서 적지 않은 부분이 다르게 설계되고 있을 가능성도 큽니다.
다만 GPU가 처음 만들어졌을 때의 설계 철학(단일 스레드 Latency가 아니라 Throughput을 끌어올리고, 그 길의 핵심 도구로 Multithreading을 통한 Latency Hiding을 쓴다)은 지금까지도 그대로 유지되고 있다고 보면 됩니다. 이어지는 절들은 이 철학 위에서 NVIDIA GPU가 어떻게 성장했고, 또 어떤 한계에 부딪히고 있는지를 살펴봅니다.
NVIDIA GPU의 성장과 한계
GPU는 처음부터 머신러닝을 염두에 두고 설계된 것이 아닙니다. 그래픽스 워크로드의 픽셀·삼각형 단위 Massive Parallelism을 활용하기 위해 만들어진 구조였는데, 마침 그 특성이 ML 워크로드와도 굉장히 잘 들어맞았던 것이 결정적이었습니다.
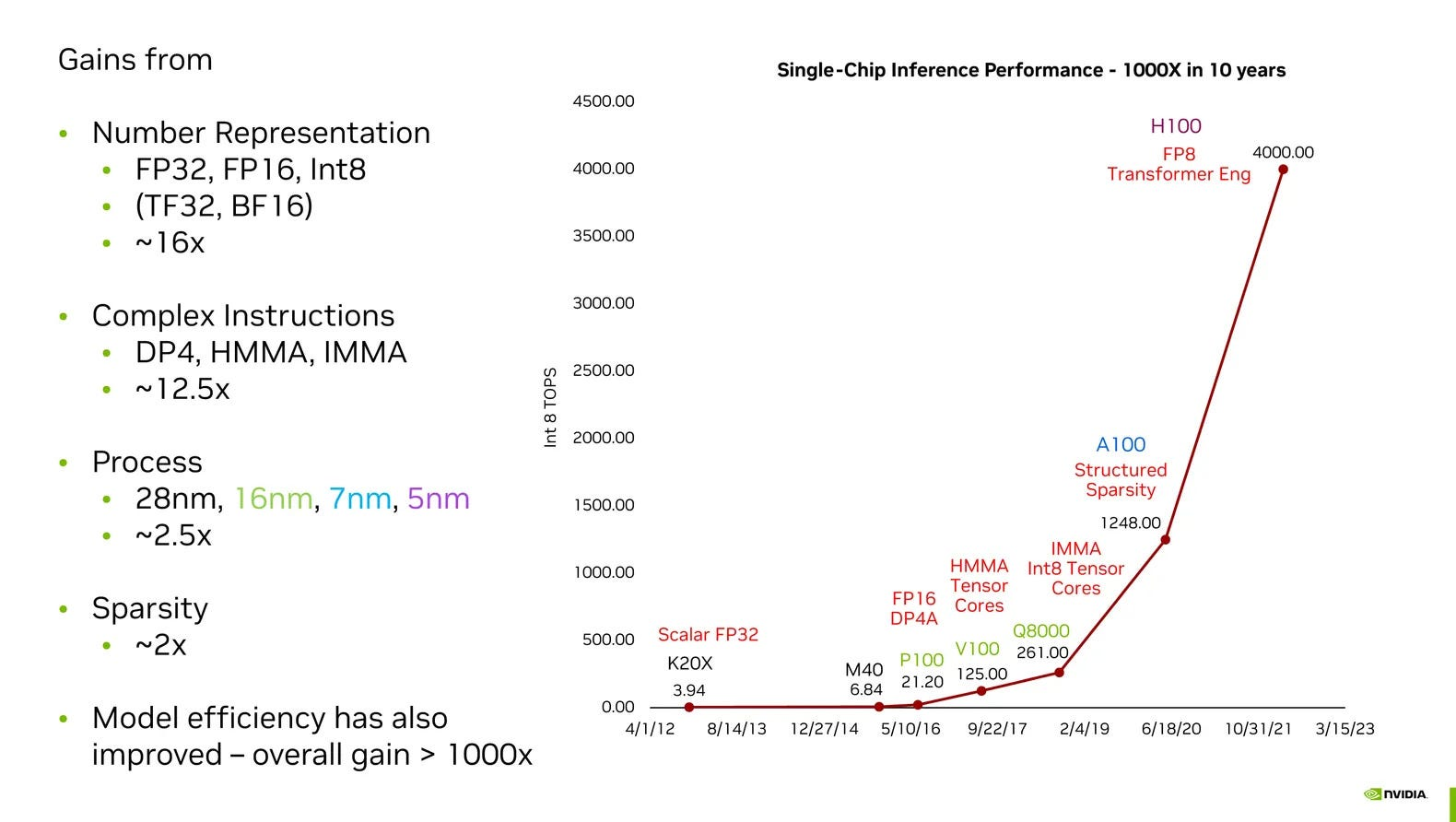
ML 붐이 본격화되면서 NVIDIA는 이 우연한 적합성을 발판으로 폭발적인 성장을 거듭했고, 그 성장에 맞춰 NVIDIA GPU의 컴퓨팅 성능(FLOPS) 도 세대마다 빠르게 올라갔습니다. 그림에 나타난 곡선이 바로 그 흐름을 그대로 보여 줍니다.
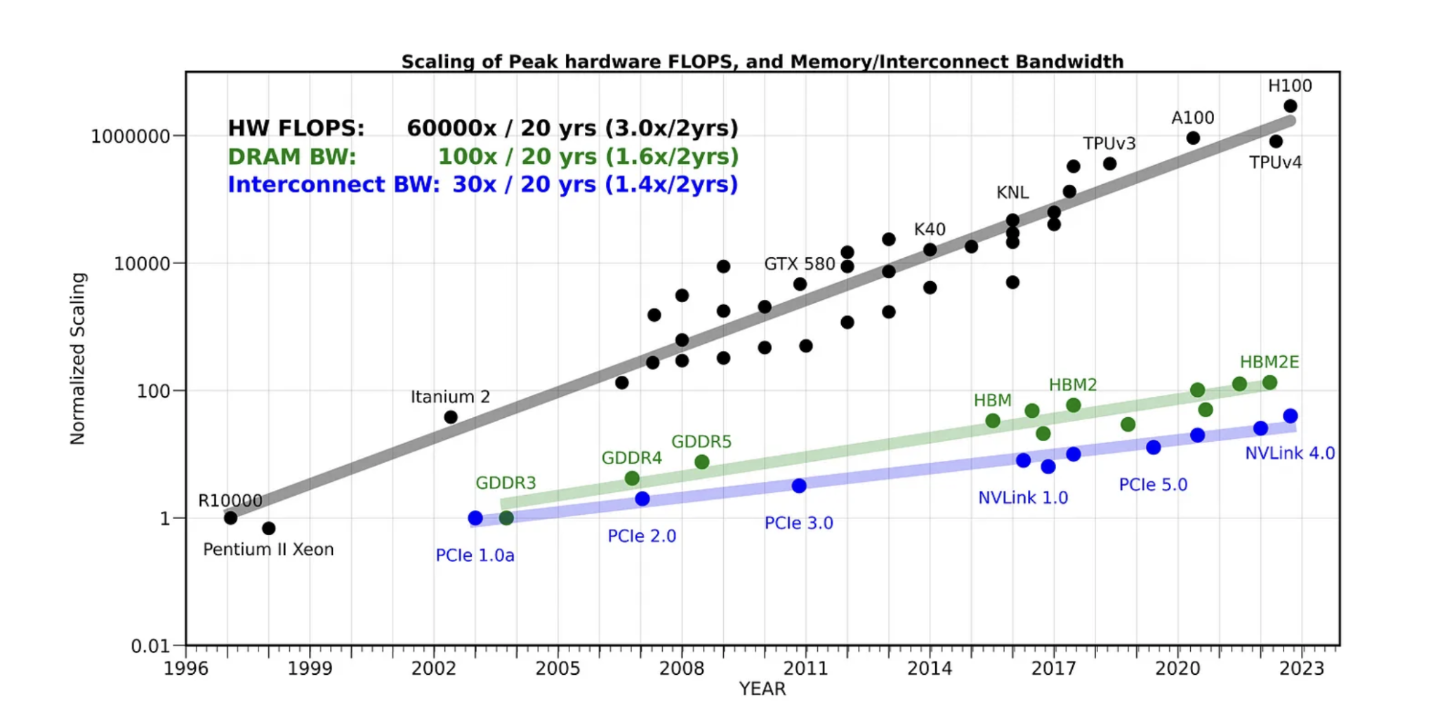
다만 컴퓨팅 성능이 올라가는 만큼 메모리 Bandwidth가 같은 속도로 따라오지는 못하고 있다는 점은 매우 중요한 한계입니다. 메모리 인터페이스 기술 자체도(HBM 세대 교체 등) 빠르게 발전하고는 있지만, NVIDIA가 컴퓨팅 밀도를 끌어올리는 속도를 따라잡지는 못하고 있고, 그 사이의 갭은 오히려 점점 더 벌어지는 추세입니다.
특히 최근 세대인 Blackwell 정도에 이르면 “이제 거의 이 게임의 끝에 온 것 아닌가” 하는 느낌이 들 만큼 컴퓨팅 쪽으로 한참 멀리 가 있는 상황입니다. 거기에 DeepSeek처럼 효율적인 모델 사례가 등장하면서, 앞으로도 계속 괴물 같은 컴퓨팅을 욱여넣은 칩이 필요할지, 아니면 이 정도 선에서 멈출지, 또는 오히려 스케일백(scale back)할지에 대한 논의가 시작되고 있습니다. 다만 지난 10년의 행보만 놓고 보면, 인텔이 한때 그랬듯이 NVIDIA도 GPU를 꾸준히 스케일업해 온 흐름이 그대로 이어지고 있는 상황입니다.
GPU의 Multithreading Overhead
메모리 Latency 문제를 해결하기 위해 NVIDIA가 선택한 길은 한마디로 “프로그래밍 모델은 최대한 단순하게, 복잡한 일은 하드웨어 안쪽으로” 였습니다. Latency Hiding을 위해 안쪽에서 돌아가는 여러 메커니즘(Warp 스케줄링, in-flight 스레드 관리 등)은 CUDA 차원에서 개발자에게 거의 노출되지 않습니다. 대신 NVIDIA는 개발자와 다음과 같은 일종의 계약을 맺습니다.
“이런 식으로(SIMT 모델로) 프로그래밍해 두면, 굉장히 많은 Thread가 만들어질 것이고, 그 Thread들을 잘 분배해 Throughput을 뽑아내는 일은 하드웨어가 알아서 처리한다.”
문제는 이 방식이 정말로 머신러닝 워크로드에 가장 잘 맞는 선택인가 하는 것입니다. 강사 본인을 포함해 여러 사람이 이 점에 대해 의문을 가지고 있고, 학계에서도 명시적으로 논의가 이루어지고 있습니다.
“(1) GPGPU’s multithreading overhead: It is not our intention to lessen GPGPUs’ huge contribution to ML’s recent success… Overhead or not, there were no alternatives, until other options came along”
출처: https://www.sigarch.org/why-the-gpgpu-is-less-efficient-than-the-tpu-for-dnns
최근 세대의 NVIDIA GPU는 위에서 본 원래 구조의 한계들을 여러 방식으로 보완·극복하고 있고, 그 내부가 모두 공개되지는 않기 때문에, “GPU의 일반적 방식이 ML에 잘 맞지 않는다”는 평가가 현재 칩에 그대로 적용되는지는 별개의 문제입니다.
그럼에도 불구하고, NVIDIA가 처음 내린 그 선택(Multithreading 기반의 Latency Hiding을 SIMT라는 단순한 프로그래밍 모델 뒤에 숨기는 것)이 ML 워크로드에 정말 최적이었느냐라는 질문은 여전히 열려 있습니다. 그리고 이 의문이 바로 다음 절에서 다룰 NPU, 즉 “같은 Latency Hiding을 하드웨어가 아닌 소프트웨어가 주도하는” 갈래의 등장 배경이 됩니다.
NPU: 소프트웨어 주도의 Latency Hiding
CPU 영역에서 우리는 같은 문제를 두 가지 방향에서 푸는 것을 이미 봤습니다. OOO Processor가 하드웨어 안에서 복잡한 장치를 동원해 Loop-level pipelining을 동적으로 만들어 냈다면, VLIW Processor는 같은 효과를 소프트웨어(컴파일러)가 미리 정적으로 만들어 두는 길을 갔습니다. 머신러닝 영역에서도 같은 분기가 일어납니다. GPU가 OOO 쪽에 해당한다면, 그 반대편에서 동일한 문제를 소프트웨어로 풀려고 하는 갈래가 바로 NPU입니다.
GPU vs NPU: 핵심 대비
이 분기를 한 장의 표로 보면 다음과 같습니다.
HW가 동적으로 Data-Flow Graph 생성
HW가 동적으로 Warp 스케줄링·Latency Hiding
컴파일러가 정적으로 Loop Pipeline 결정
컴파일러가 정적으로 전체 실행 계획 생성
비례식으로 줄이면 한 줄입니다. OOO : VLIW = GPU : NPU. OOO Processor가 하드웨어적으로 Loop-level pipelining을 달성하는 것처럼 GPU는 하드웨어적으로 Thread-level Latency Hiding을 수행하고, 반대로 VLIW가 소프트웨어적으로 Loop-level pipelining을 달성하는 것처럼 NPU는 소프트웨어(컴파일러)가 정적으로 전체 실행 계획을 생성합니다.
NPU의 공통 특징
NPU라는 이름으로 묶인 칩들의 구체적인 구조는 회사마다 꽤 다르고, “NPU란 이런 것이다”라고 한 줄로 못 박기는 어렵습니다. 다만 공통적으로 발견되는 특징이 하나 있습니다. 메모리 Latency·Bandwidth를 최대한 활용하기 위한 장치들을 하드웨어 안쪽에 가두지 않고, 소프트웨어에 노출시킨다는 점입니다. 그리고 노출된 그 디테일을 컴파일러나 프로그래머가 코드에 충분히 반영해서, 매 cycle 무엇이 어디서 어떻게 흐를지를 결정합니다. 이것이 NPU 갈래가 가지는 가장 큰 정체성입니다.
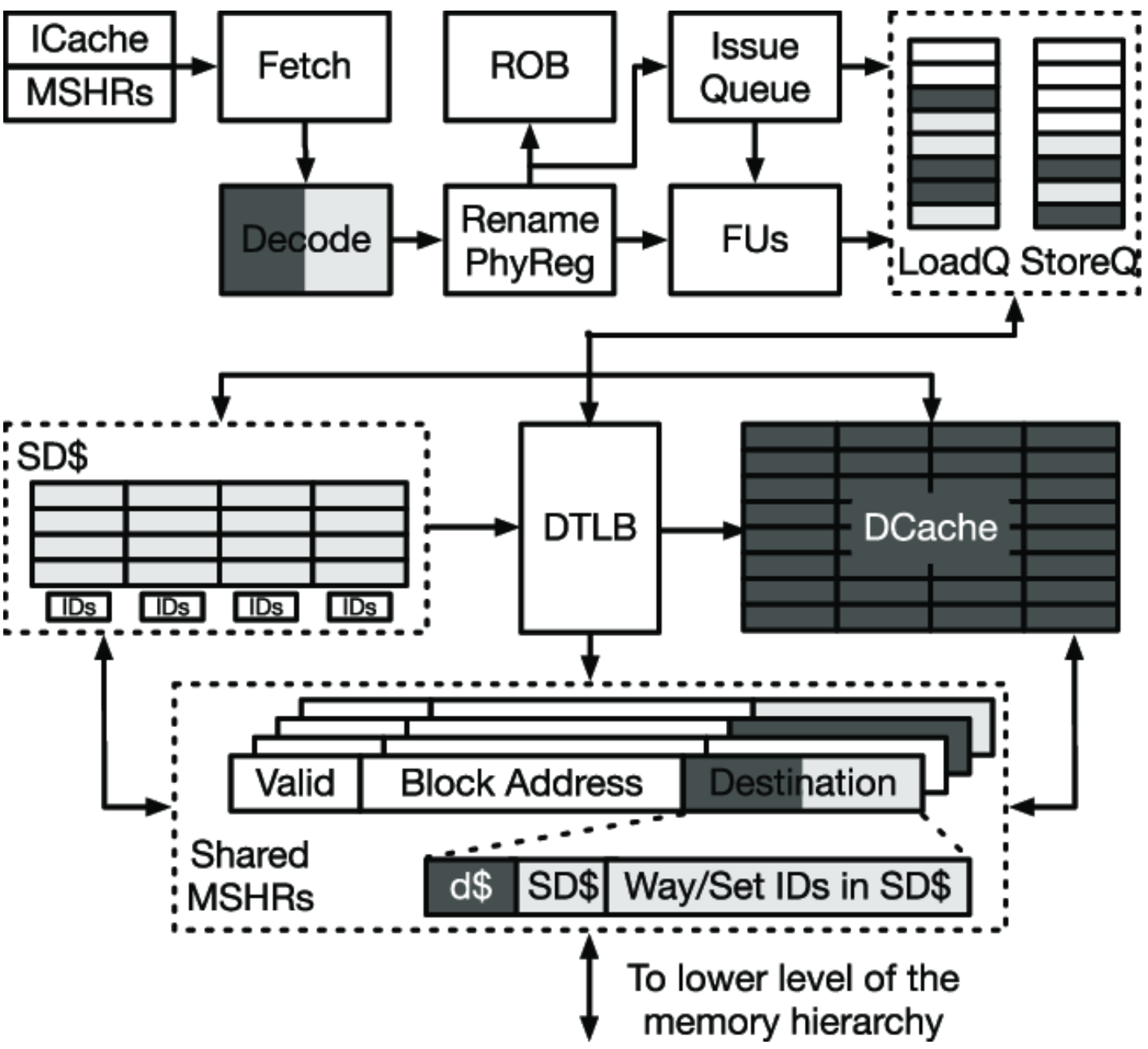
NPU Architecture: Scratchpad Memory와 DMA
전반적인 그림 자체는 사실 GPU나 NPU나 크게 다르지 않습니다. 위쪽에 연산을 담당하는 Compute Unit들이 있고, 그 사이를 잇는 Interconnect가 있고, 빠른 온칩 메모리가 있고, 비용이 큰 오프칩 경계를 넘어 DRAM이 있는, 앞 절의 Memory Wall 그림과 같은 형태입니다.
차이는 작아 보이지만 본질적입니다. NPU의 그림에서는 공통적인 두 가지 특징이 발견됩니다.
- 온칩 메모리가 Cache가 아니라 Scratchpad - 일반 CPU/GPU에서는 하드웨어가 자동으로 데이터를 캐시 라인 단위로 관리하지만, NPU에서는 어떤 데이터를 어디에 둘지를 소프트웨어가 직접 결정하는 Scratchpad 형태로 노출됩니다.
- Scratchpad에 값을 넣고 빼는 모든 동작이 DMA로 명시 프로그래밍 - 위 그림 좌측의 L1 DMA / L2 DMA stack 이 그것입니다. 이 DMA 들이 단순히 하드웨어 디테일로 숨겨져 있는 것이 아니라, 소프트웨어가 매 순간 어느 DMA로 어떤 영역을 옮길지 명령으로 직접 적어 주는 구조입니다.
결국 NPU 다이어그램에서는 Compute Unit 뿐 아니라 데이터를 옮기는 DMA들까지 모두 소프트웨어에 노출된 개별적으로 프로그래밍 가능한 병렬 유닛으로 취급됩니다. 이 모든 유닛에 대해 “누가 언제 무엇을 한다”를 소프트웨어가 매 cycle 표 형태로 적어 두면, 하드웨어는 그 표대로만 실행하면 됩니다. GPU에서는 하드웨어가 자동으로 캐시를 관리하고 스레드 스케줄링까지 동적으로 처리해 주던 일을, NPU에서는 모두 컴파일러(혹은 프로그래머)가 정적으로 계획하는 것입니다.
Horizontal Encoding과 Command Stream
NPU의 내부 구조를 위 Memory Hierarchy 그림이 아니라 명령어 관점에서 다시 보면, 하드웨어가 횡으로 쭉 펼쳐져 있고 그 위에 각 유닛이 매 cycle 무엇을 할지를 명령어가 직접 지정해 주는 구조에 가깝습니다. Compute Unit 들과 L1 DMA 들과 L2 DMA 들이 모두 각각 독립적으로 프로그래밍 가능한 유닛으로 노출되어 있는 셈입니다.


이런 모습은 앞 절에서 본 Horizontal Encoding의 형태와 정확히 닮아 있습니다. 다시 말해 NPU는 VLIW (또는 Reconfigurable Architecture) 계열에 가까운 ISA를 가진 셈입니다.
이 구조에서 Command Processor가 소프트웨어가 미리 만들어 놓은 실행 계획을 받아 각 하드웨어 유닛에 분배하고, Sync Network를 통해 서브태스크 간 순서 관계를 유지합니다. 그래서 NPU에서 “프로그래밍한다”는 것은 곧 이 Command Stream을 어떻게 짤 것인가의 문제가 됩니다.
NPU Compiler의 역할


NPU에서 컴파일러가 실제로 무엇을 하는지를 한 번 따라가 보면, NPU와 GPU의 차이가 가장 분명해집니다. ML 모델은 일반적으로 노드 단위의 그래프 형태로 컴파일러에 들어옵니다. 그런데 그래프의 한 노드(예: 큰 matmul, attention 한 블록)가 곧바로 한 cycle에 끝낼 수 있는 작업인 경우는 거의 없고, 하드웨어가 한 번에 처리할 수 있는 작은 단위로 더 잘게 쪼개야 합니다.
이 쪼개기와 그 후의 결정들이 모두 NPU 컴파일러의 몫입니다.
- 그래프 노드 → 하드웨어가 처리 가능한 작은 sub-task로 분할
- 각 sub-task가 어떤 Compute Unit / DMA / Scratchpad 영역에서 수행될지 결정
- sub-task들 사이의 순서 관계와 동기화 결정
- 최종적으로 각 유닛에 보낼 Command Stream을 생성
이 모든 결정이 아키텍처의 디테일을 깊이 이해한 컴파일러의 종합적 판단으로 이루어집니다. 그리고 NPU는 이렇게 정적으로 짜인 계획을 받아 그대로 기계적으로 실행만 합니다.
| GPU | NPU | |
|---|---|---|
| 작업 분할 | HW가 동적으로 처리 | SW(컴파일러)가 정적으로 처리 |
| 스케줄링 | HW가 스레드 스케줄링 | 컴파일러가 전체 실행 계획 생성 |
| HW 복잡도 | 높음 (스케줄링 로직) | 낮음 (실행만 담당) |
| 추상화 수준 | 높음 (CUDA) | 낮음 (HW 디테일 노출) |
GPU의 경우 이런 디테일은 사용자에게 거의 보이지 않습니다. 개발자는 “한 스레드가 어떻게 생겼는지” 와 “그런 스레드가 몇 개나 필요한지” 정도의 명세만 던져주면, 하드웨어가 그것을 받아 알아서 쪼개고 스케줄링합니다. 반면 NPU는 GPU에서 하드웨어가 내리던 결정을 모두 소프트웨어 쪽으로 끌어와 미리 결정해 두는 구조입니다. 그 결과 NPU의 하드웨어는 단순하게 “받은 계획을 실행만” 하면 되지만, 대신 컴파일러가 하드웨어 디테일을 깊이 이해하고 최적화된 실행 계획을 짜내야 한다는 무거운 책임을 갖게 됩니다.
정리
이번 강의에서 다룬 내용을 정리하면 다음과 같습니다.
현대 프로세서의 가장 큰 성능 병목은 오프칩 메모리(DRAM) 접근의 Bandwidth/Latency, 즉 Memory Wall입니다. 따라서 메모리 Latency를 어떻게 숨기는가, 또는 동치 표현으로 메모리 Bandwidth를 어떻게 최대한 활용하는가가 모든 현대 프로세서 설계의 공통 과제가 됩니다.
Pentium 4가 상징하는 Clock Frequency 경쟁이 끝난 뒤, 인텔은 Multi-Core로 깔끔하게 전환했고, 그 위에서 Multithreading을 통한 Memory Latency Hiding을 적극적으로 활용하기 시작했습니다.
GPU는 Massive Parallelism으로 Latency를 숨깁니다. 같은 시기에 GPU는 Shader Programming이라는 수요를 따라 Programmable Device로 변신했습니다. 그래픽스 워크로드의 픽셀·삼각형 단위 Massive Parallelism을 활용하기 위해 GPU는 단일 스레드 성능을 깎고 Throughput을 우선하는 길을 갑니다. 복잡한 OOO 엔진 같은 부가 장치를 덜어내고, 단순한 코어를 잔뜩 박아 넣어 매 cycle 새로운 Warp으로 갈아 끼우며 메모리 Latency를 가립니다. 이 구조가 마침 ML 워크로드에 매우 잘 맞아, NVIDIA가 오늘날의 AI 가속기 시장을 선점하게 됩니다.
GPU와 NPU는 HW 접근과 SW 접근으로 갈립니다. 최근 등장하는 AI 가속기인 NPU는, Loop-Level Pipelining에서 본 OOO ↔ VLIW의 대비가 그래픽스/ML 영역에서 그대로 다시 나타나는 케이스입니다. GPU는 Vertical Encoding 쪽에 가까워서, 하드웨어 디테일을 숨기고, 하드웨어가 동적으로 Warp을 스케줄링하며 Latency를 가려 줍니다. 프로그래머는 “어떤 병렬성이 있는가” 만 표현하면 됩니다. 반대로 NPU는 Horizontal Encoding 쪽에 가까워서, 하드웨어 디테일을 소프트웨어에 노출하고, 하나의 작업을 작은 sub-task로 쪼개고 그들 사이의 의존성과 동기화까지 모두 컴파일러가 미리 계획해서 던져주면 하드웨어가 그대로 실행만 합니다. 비례식으로 줄이면 OOO : VLIW = GPU : NPU가 그대로 성립합니다.