Week 6: Beyond PyTorch: Custom Kernel과 vLLM
PyTorch + NPU 온라인 모임 #6 | 2025-02-05
소개
이번 강의에서는 PyTorch를 넘어서(Beyond PyTorch) LLM 추론에 필요한 기술들을 다룹니다. 크게 네 가지 주제로 구성됩니다:
- LLM inference의 성능 문제 - Prefill과 Decode의 차이, Roofline analysis, Memory wall
- Memory overhead를 줄이기 위한 기술들 - Continuous batching, Speculative decoding, Flash Attention, Paged Attention, Quantization
- Kernel Programming - CUDA, CUTLASS, OpenAI Triton
- Serving 최적화 Framework - vLLM과 기타 상용 프레임워크
오늘의 질문
이번 강의는 “Beyond PyTorch”라는 제목 그대로, PyTorch 외에 무엇을 더 준비해야 하는지를 다룹니다. 특히 리벨리온을 비롯해 이번 강의에 참여하고 계신 다른 AI 반도체 회사들 관점에서, 그리고 그중에서도 추론(inference)에 특화된 AI 반도체 관점에서, 개발 환경으로 PyTorch만 지원하면 충분한가, 아니면 무엇을 더 갖춰야 하는가를 함께 고민해 보려고 합니다.
성능이 가장 중요한 이슈라고 본다면, 자연스럽게 다음 세 가지 질문이 따라옵니다.
- 성능 측면에서 LLM 추론의 가장 큰 문제는 무엇인가?
- 그 문제들을 어떻게 해결할 수 있는가?
- 그 해결책을 개발자가 잘 구현하기 위해 PyTorch만으로 충분한가, 아니면 보조적인 다른 개발 환경이 필요한가?
이 세 질문에 답을 하다 보면 오늘 다루려는 주제들을 자연스럽게 모두 짚게 됩니다.
답부터 먼저 드리면(어디까지나 개인적인 생각이지만 많은 분들도 비슷하게 보실 거라 생각합니다), LLM 추론 관점에서 PyTorch는 전체 큰 그림의 (매우 중요한) 일부입니다. 전체 생태계의 구심점은 분명히 PyTorch이지만, PyTorch만 가지고 모든 게 되지는 않습니다. 우리가 잘 활용하고 있는 Llama, DeepSeek 같은 공개 Pretrained LLM, 그리고 이들이 배포되는 Hugging Face 중심의 배포 기술 모두가 큰 그림 안에서 굉장히 중요한 환경 중 하나입니다.
성능에 초점을 맞춰 보면 더 분명해집니다. PyTorch만으로는 해결되지 않는 영역이 분명히 존재하고, 이를 메우려면 커널 프로그래밍(병렬 프로그래밍)과 더 상위 레이어인 서빙 최적화까지 함께 갖춰져 있어야 합니다. 이 모든 것이 갖춰져야 비로소 개발자들이 LLM 추론에서 제대로 된 성능을 낼 수 있고, 따라서 AI 반도체 회사 입장에서도 PyTorch 외의 환경을 함께 잘 준비해야 합니다. 오늘 아젠다는 이 관점에서 정리한 것입니다.
⌐ 오늘의 초점 ¬
Open Pretrained LLM
LLM 배포
ML Framework
Kernel Programming
서빙 최적화
LLM Inference의 성능 문제
Self Attention과 Scaled Dot-Product
LLM에서 가장 중요한 연산을 하나 꼽으라면 단연 Self-Attention, 그중에서도 실제로 그것을 계산하는 연산인 Scaled Dot-Product입니다. 왼쪽 그림처럼 한 문장이 주어졌을 때, 단어들 사이의 관계를 통해 “이 문장 안에서 이 단어가 어떤 의미를 갖는가”를 더 명확하게 뽑아내는 과정이 곧 self-attention이라고 생각할 수 있습니다.
이 과정은 잘 알려져 있듯이 K(Key), Q(Query), V(Value) 세 가지 값으로 이루어집니다. Attention은 단어들 사이의 연관성의 크기이고, query–key 내적으로 그 크기를 구한 뒤 value를 곱해 누적하면(=scaled dot-product), 특정 단어에 self-attention이 반영된 새로운 표현(embedding)이 만들어집니다.
오른쪽 그림에서 계산 측면의 재미있는 포인트가 몇 가지 있는데, 하나는 처음에 입력 단어 embedding으로부터 K·Q·V를 뽑아내는 부분은 모두 병렬로 처리할 수 있다는 점입니다. 그다음 새로운 representation을 만들고자 하는 단어의 query와, 모든 단어의 key를 곱해 attention score를 만들고, 거기에 softmax를 거쳐 분포를 normalize한 뒤, 다시 V와 곱해 모든 단어를 더하면 새로운 embedding이 나옵니다.
요약하자면 계산 특성은 다음과 같습니다.
- 병렬 처리가 자연스러운 부분 - 입력 embedding으로부터의 K·Q·V 계산, 그리고 단어별로 독립적인 하위(아래쪽) 연산
- 병렬 처리가 까다로운 부분 - 전체 분포를 봐야 하는 softmax, 그리고 그 결과와 V를 곱한 뒤 모든 단어에 대해 합산하는 summation
이 “위쪽이 병렬화하기 까다롭다”는 점은 이후 Flash Attention 같은 GPU-aware 알고리듬이 풀어야 하는 문제로 다시 등장합니다.

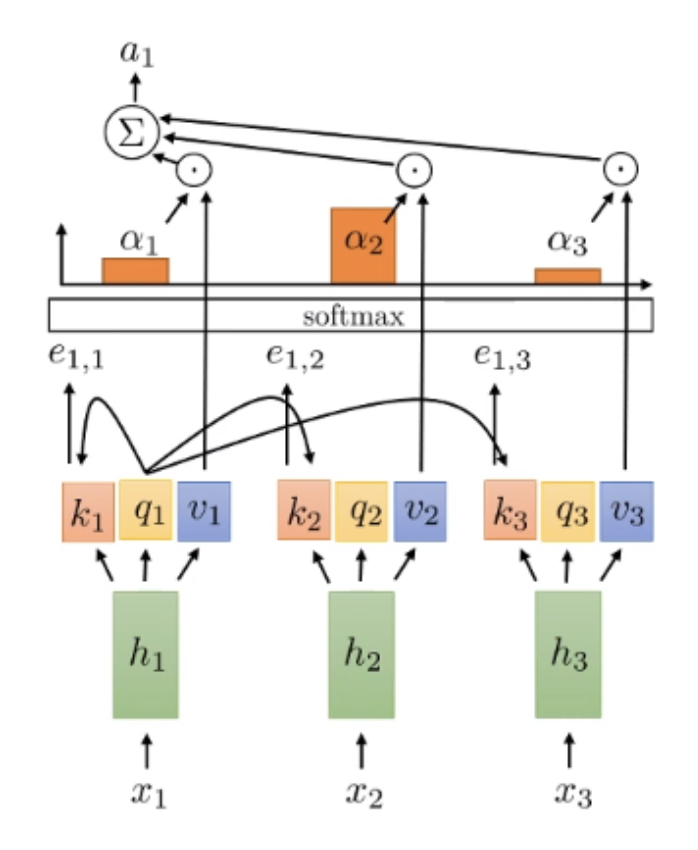
④ Self-attention이 반영된 “it”(=)의 새 embedding
출력 이 곧 “it”의 새 표현
③ 모든 단어의 영향을 더함
softmax 분포로 정규화 후 로 합산
② 단어별로 와 를 곱함
attention score()와 value를 element-wise 곱
① “it”(=)의 query가 모든 k에 반영
을 , , 와 각각 내적해 attention score 계산
출처: https://jalammar.github.io/illustrated-transformer/
출처: Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures
Non-Causal vs. Causal Attention
Self-Attention의 또 다른 중요한 특징은 Causal이냐, Non-Causal이냐입니다. 앞 슬라이드에서 본 “it” 예시는 사실 Non-Causal에 해당합니다. “it”의 attention을 구할 때 이 단어 앞에 있는 단어들과 뒤에 있는 단어들을 모두 사용해 계산했죠. 반면 오른쪽 그림처럼 Causal Attention에서는 자기보다 먼저 나온 단어들로부터만 attention을 받도록 제한됩니다.
이 두 방식은 단순한 옵션 차이가 아니라 뉴럴 네트워크 구조 자체가 크게 달라질 만큼 계산 패턴이 다릅니다. 그럼에도 불구하고 GPT 등장 이후로는 Causal Attention만으로도 충분히 좋은 성능을 낼 수 있다는 공감대가 형성되어, 현재 거의 대부분의 LLM은 Auto-regressive(Causal) Attention을 사용합니다.
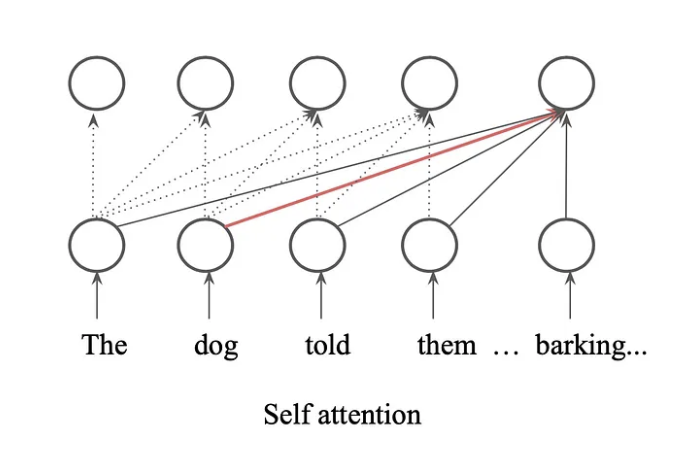
Non-Causal Attention
앞/뒤 모든 단어를 고려 (양방향)

Causal Attention
이전 단어만 고려 (단방향)
Prefill과 Decode
Decoder-Only LLM이 결국 하는 일은 한 가지입니다. 주어진 단어들로부터 다음 단어를 예측하는 작업을 끝없이 반복하는 것이죠 (Autoregressive). 이를 위해 먼저 Pretraining 단계에서 “개의 단어가 주어졌을 때 그다음 단어가 무엇인가”를 엄청나게 많이 반복 학습해 Trained Weights를 만듭니다. 학습이 끝나고 나면 같은 weight를 가지고 추론(decoding) 단계에서는 프롬프트가 들어왔을 때 그에 대한 답을 차례로 뱉어내는데, 이 과정은 다시 Prefill(프롬프트를 처리하는 단계)과 Decode(문장이 끝날 때까지 단어를 반복 생성하는 단계)로 나뉩니다.
Prefill과 Decode는 하나의 큰 모델의 두 단계로 볼 수도 있지만, 실제 계산 특성이 너무 다르기 때문에 weight를 공유하는 두 개의 별도 모델로 보는 편이 자연스럽습니다. 회사마다 접근이 다르지만, 예를 들어 리벨리온에서는 Prefill과 Decode를 두 번 따로 컴파일해서 별도의 binary로 만들어 사용하고 있습니다.
앞에서 LLM 이야기, 그리고 Prefill·Decode 이야기를 길게 한 진짜 이유는 두 단계가 서로 다른 계산적 특성을 가진다는 점을 짚기 위해서입니다. 실제 추론 과정을 시간축에 펼쳐 보면 다음과 같이 생겼습니다.
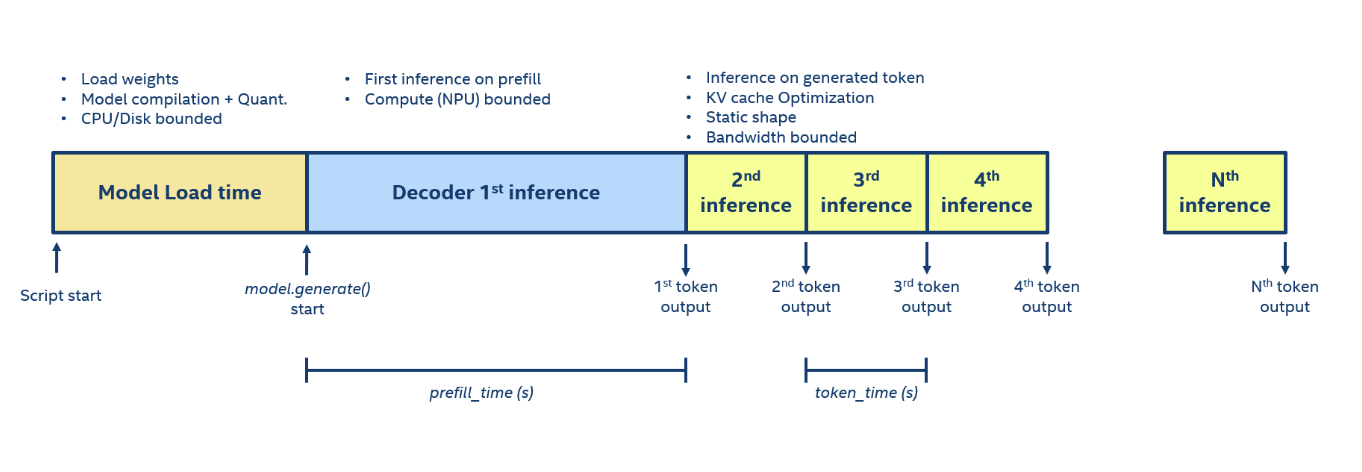
출처: https://intel.github.io/intel-npu-acceleration-library/llm_performance.html
가장 먼저 모델 로딩이 한 번 일어나고(이후로는 다시 로딩하지 않음), 거기서부터 첫 번째 토큰이 만들어질 때까지가 Prefill입니다. Prefill은 사실상 프롬프트를 이해하는 과정으로 볼 수 있습니다. 첫 토큰이 만들어진 뒤에는 한 토큰씩 차례로 만들어내며 문장이 끝날 때까지 반복하는데, 이 부분이 곧 실제 답을 만들어내는 Decode 과정입니다.
LLM 추론 성능을 이야기할 때 자주 등장하는 두 지표가 이 두 단계와 정확히 매칭됩니다.
- TTFT(Time to First Token) - Prefill이 얼마나 빠르게 끝나는지를 나타내는 지표
- TPS(Tokens Per Second) - Decode 단계에서 초당 몇 개의 토큰을 만들어내는지를 나타내는 throughput 지표
TPS의 미묘한 점은 매 스텝마다 같은 모델을 그대로 돌린다는 점입니다. 그런데 Self-Attention에 반영해야 하는 이전 문맥(KV)은 토큰이 늘어날수록 함께 길어지기 때문에, 이론적으로는 두 번째보다 세 번째, 네 번째 토큰을 만들 때 자연스럽게 시간이 더 걸리고 TPS가 점점 떨어지는 형태가 됩니다.
Prefill vs. Decode: 병렬성의 차이
Prefill과 Decode의 가장 중요한 차이는 여러 토큰을 처리하는 방식, 즉 병렬성의 양상 자체가 다르다는 점입니다. 둘이 결국 하는 일(“주어진 단어들로부터 다음 단어를 예측”)은 똑같은데, 한 스텝에 처리해야 할 토큰들 사이의 의존 관계가 달라서 계산의 모양 자체가 달라집니다.
Decode 쪽이 직관적으로 이해하기 쉽습니다. 이전 토큰들은 이미(생성이든 입력이든) 모두 처리가 끝나 있고, 방금 막 만들어낸 마지막 토큰 하나로 그 다음 토큰을 예측합니다. 마지막 토큰 위치에서 self-attention을 다시 계산하고, linear layer + classification을 거쳐 다음 단어를 고르는 과정을 매 토큰마다 반복합니다. 그런데 그 다음 토큰을 만들려면 이전 토큰이 무엇이었는지가 입력으로 들어가야 하므로, 첫 번째 토큰이 끝나야 두 번째가 시작될 수 있고, 본질적으로 순차 처리(sequential)가 됩니다. 또한 누적된 토큰이 늘어날수록 self-attention에서 봐야 하는 KV도 함께 늘어납니다.
Prefill 쪽도 개념적으로는 거의 같습니다. Decoder-Only LLM이 할 줄 아는 일은 “단어들이 주어졌을 때 다음 단어를 예측하는 것” 하나뿐이니까요. 다만 이미 개 단어가 주어진 상태라는 점이 결정적인 차이를 만듭니다. 예를 들어 프롬프트가 U R A HELP CHAPP라면, 두 번째 토큰 R를 처리할 때 “U의 다음 토큰이 무엇인지”는 이미 정해져 있고(=다음 입력 토큰 자체가 그것), 따라서 U의 처리 결과를 기다릴 필요가 없습니다. 그래서 U R A HELP CHAPP를 모두 동시에 첫 레이어부터 통과시킬 수 있습니다.
여기서 헷갈리기 쉬운 부분이 있는데, “동시에 처리해도 된다”는 건 토큰 간에 영향이 없다는 뜻이 아닙니다. attention을 통해 왼쪽 토큰이 오른쪽 토큰에 영향을 주는 것은 그대로지만, 어떤 한 토큰의 다음 토큰을 만들어내기 위한 최종 출력이 옆 토큰을 처리하는 데 필요한 입력이 아니기 때문에, 모든 토큰을 첫 레이어부터 차근차근 병렬로 진행할 수 있는 것입니다.
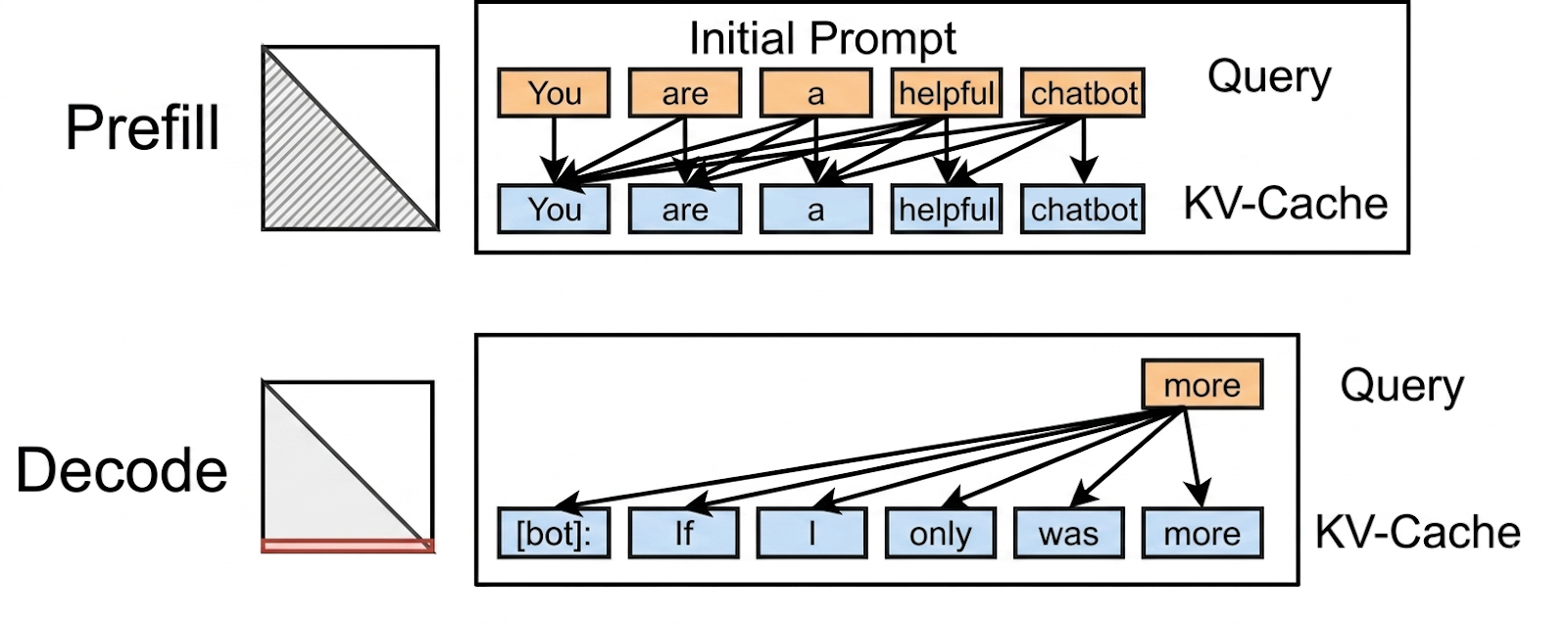
출처: https://flashinfer.ai/2024/02/02/introduce-flashinfer.html
다이어그램에서 화살표는 attention(=토큰 간 의존)을 뜻합니다. Prefill은 수직(레이어 간) + 우상향(KV 전달) 의존성만 있어 같은 레이어 안의 모든 토큰을 가로로 병렬 처리할 수 있는 반면, Decode는 새 토큰을 만들 때마다 직전 토큰의 결과가 입력으로 다시 들어가야 해서 토큰 단위로 순차 처리가 됩니다.
Q&A 정리 (강의 중 질의응답)
- Q. Transformer의 디코더와 다른 아키텍처인가요? Prefill·Decode를 두 모델로 만든다면 (Encoder–Decoder) Transformer와 비슷한 것 아닌가요? → 아니요. Decoder-Only LLM 자체가 Transformer decoder만으로 구성된 구조라고 보면 됩니다. Prefill과 Decode를 개념적으로 두 모델처럼 다루는 이유는 여러 토큰을 한 번에 처리할 때의 병렬 가능성 양상이 다르기 때문이지, Encoder–Decoder 구조와는 다른 결의 구분입니다.
- Q. 리벨리온이 Prefill·Decode를 두 번 컴파일한다고 했는데, 컴파일러 옵션을 달리 주는 건가요? → 옵션 차이가 아니라 실제 생성되는 계산 자체가 다릅니다. 배치 사이즈도 다르고, Prefill은 한 토큰의 출력이 옆 토큰의 입력이 될 필요가 없어 모양 자체가 달라지므로, 결과적으로 별도의 binary로 빌드해 사용합니다.
- Q. Prefill 그림의 화살표는 attention을 뜻하나요? → 네, 여기서의 화살표는 attention을 의미합니다.
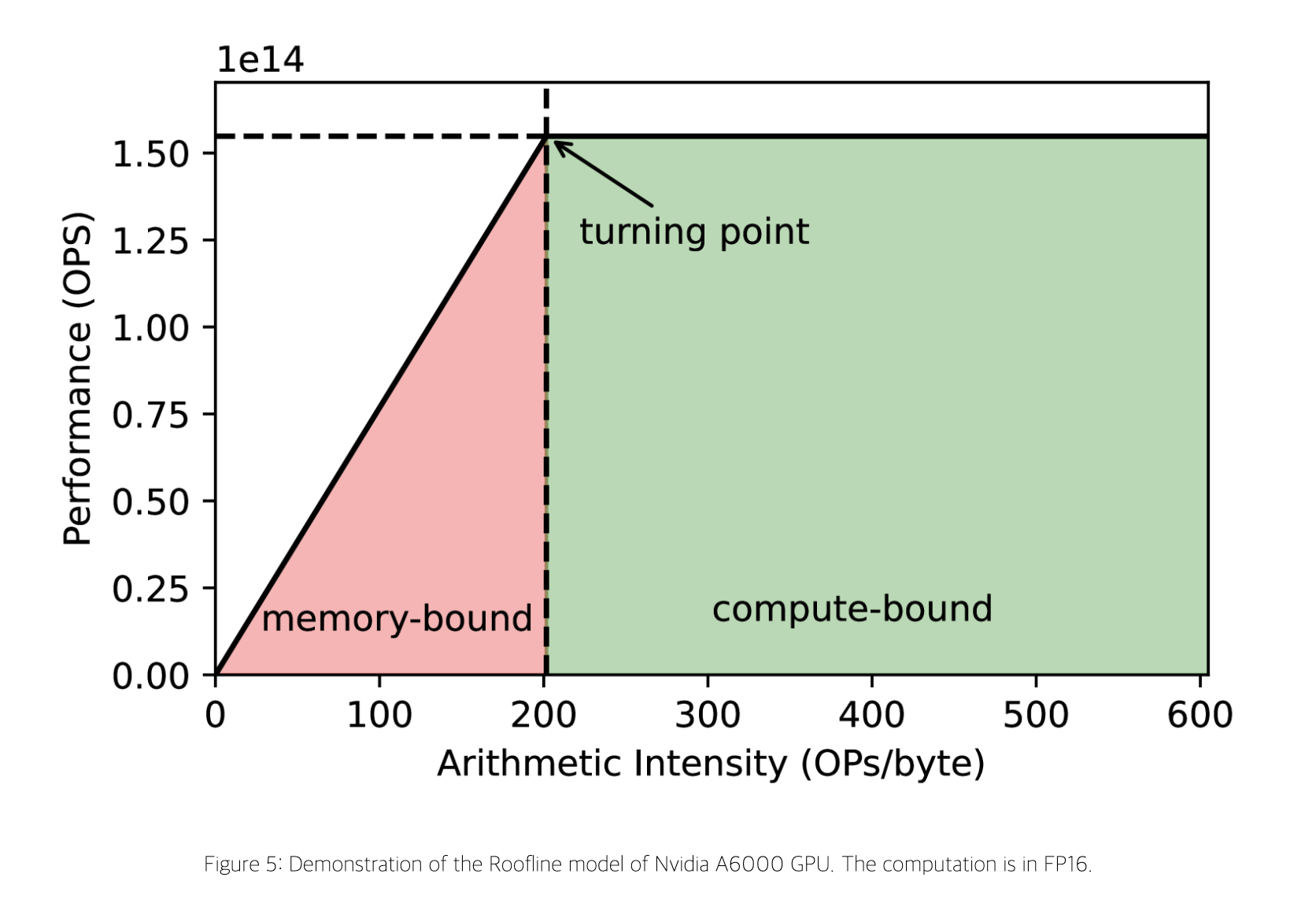
Roofline Analysis
사실 지금까지 Self-Attention → Causal/Non-Causal → Prefill/Decode를 차례로 빌드업해 온 것은 이 그래프 한 장을 설명하기 위해서라고 봐도 무방합니다. 아키텍처나 성능 분석을 하는 분들에게는 익숙한 그래프인데, 이걸 Roofline Analysis라고 부릅니다. “Decode 쪽 Memory Bound 영역의 사선”과 “터닝 포인트 이후 평평해지는 가로선”이 마치 지붕(roof)처럼 보인다고 해서 붙은 이름입니다.
출처: LLM Inference Unveiled: Survey and Roofline Model Insights
컴퓨터를 (1) 메모리에서 데이터를 읽고 쓰는 비용 + (2) 가져온 데이터로 실제 연산을 수행하는 비용 두 가지로만 나눠 모델링했을 때, 지금 내가 어느 쪽에 묶여 있는가, Memory Bound인지 Compute Bound인지를 판별해 주는 그래프입니다.
- 왼쪽 영역 (Memory Bound) - 연산기는 아직 여유가 있는데, 데이터를 들여오고 내보내는 속도가 따라오지 못해 칩이 자기 풀스펙 연산력을 다 못 쓰는 상황
- 오른쪽 영역 (Compute Bound) - 연산기 자체가 이미 꽉 차 있어, 아무리 Arithmetic Intensity가 더 높아져도 더는 빨라지지 않는 상황
X축의 Arithmetic Intensity는 알고리즘의 고유 특성으로, “메모리에서 한 번 들고 온 데이터로 몇 번의 연산을 수행하는가”를 뜻합니다.
이걸 Prefill·Decode에 대입하면 차이가 명확합니다. Prefill에서 I like my cat처럼 4개 토큰을 횡적으로 동시에 처리할 때, 한 레이어의 weight는 한 번만 들고 와서 4번 재사용됩니다. 즉 메모리 접근당 연산량이 4배라 Arithmetic Intensity가 높습니다. 반면 Decode에서 lot 한 토큰을 만들 때는 같은 weight를 들고 오지만 연산은 1번뿐이라 Intensity가 1/4 수준이 됩니다.
결과적으로:
- Decode - Arithmetic Intensity가 낮아 Memory Bound, 원하는 만큼 계산을 다 못 함
- Prefill - Arithmetic Intensity가 높아 Compute Bound, 연산기는 꽉 차 있어 더 끌어올릴 여지가 적음
연산기 활용도 측면에서 보면 Prefill은 이미 이상적인 상황이고, 사람들이 보통 이 그래프를 보면 “메모리 대역폭을 더 늘려야 하나?”보다는 “Decode 쪽이 프로세서 성능을 다 못 쓰고 있다”는 결론을 내립니다. 즉 LLM 추론 최적화의 진짜 전장은 Decode 단계입니다.
Q. Sparse Matrix 연산처럼 “의미 없는 계산”이 많이 끼는 경우 Arithmetic Intensity 자체가 의미가 있을까요? → 그런 경우 intensity가 다소 희석되긴 합니다. 다만 머신러닝에서는 모델이 본질적으로 가져야 할 “유효 곱셈(effective multiplication)” 수와, 프로세서가 그 관점에서 얼마나 빠르게 처리하는지를 따로 측정하는 별도 용어가 있습니다. 덴스(dense) 계산이고 무의미한 연산 비중이 충분히 작다면 Arithmetic Intensity는 여전히 유효한 지표입니다.
Memory Wall
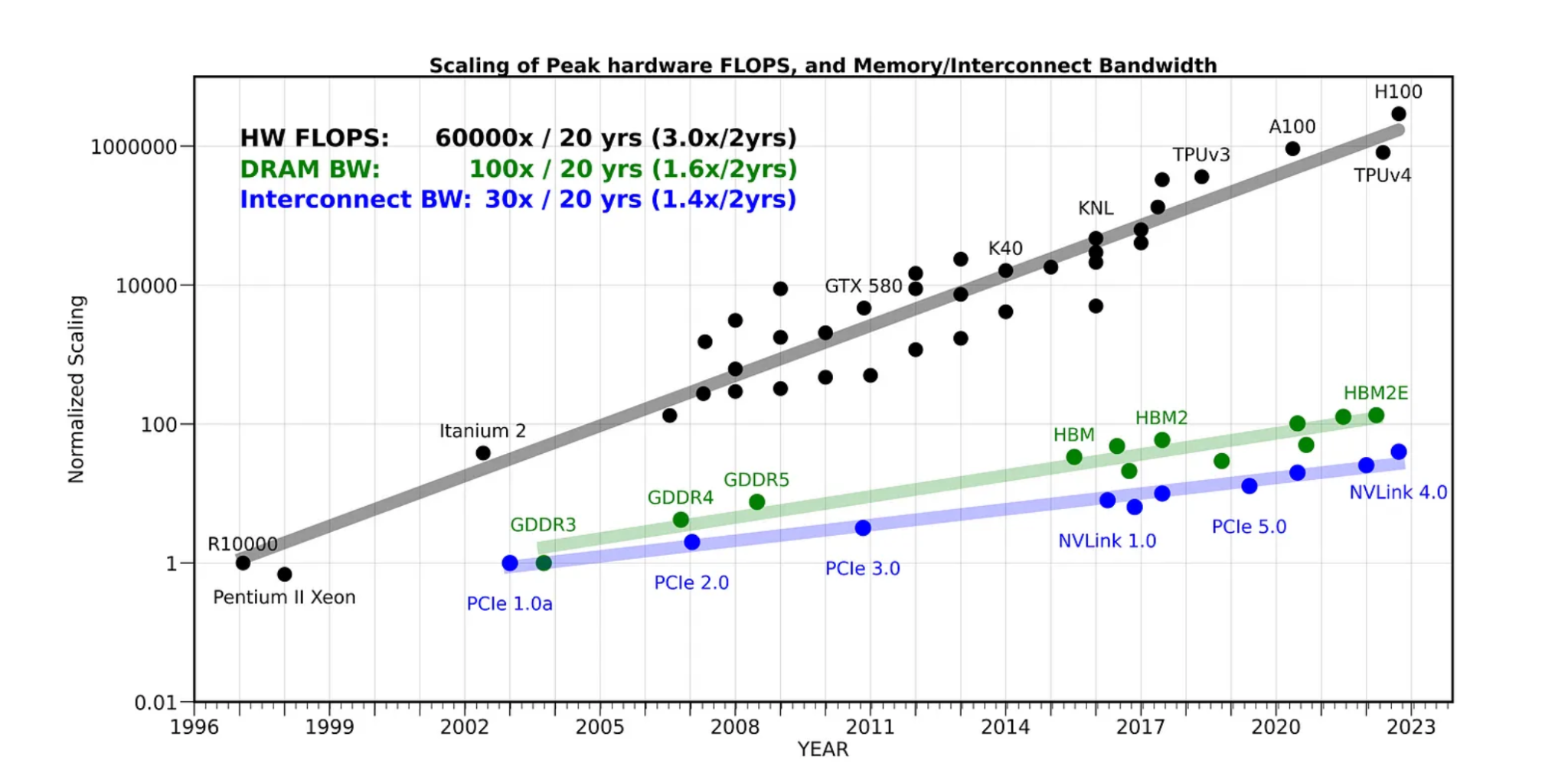
이런 현상이 LLM 추론에서만의 특수한 이슈가 아니라는 점도 짚을 만합니다. 요즘 프로세서를 설계할 때도 메모리 쪽이 가장 자주 병목이 되는 영역이고, 메모리 퍼포먼스가 전체 시스템 성능을 사실상 좌우한다고 보는 것이 일반적인 관점입니다.
이건 최근 몇 년 사이의 트렌드가 아니라 아주 오래전부터 알려져 온 현상입니다. 아래 인용한 논문은 1995년에 나온 것으로, “Memory Wall” 이라는 용어를 처음 쓰거나 적어도 널리 알린 출발점이 된 논문입니다. 그때 이미 “프로세서의 성능은 연산을 얼마나 빨리 처리하느냐가 아니라, 데이터를 얼마나 빨리 들고 오고 내보낼 수 있느냐로 결정된다” 는 이야기가 나오고 있었던 셈입니다.

물론 메모리 인터페이스 기술이 정체된 것은 결코 아닙니다. 다들 알고 계신 HBM 같은 새로운 기술이 계속 등장하면서 메모리 인터페이스와 대역폭(bandwidth) 자체는 꾸준히 향상되고 있습니다.
문제는 그 향상 속도에 비해 하드웨어의 연산 밀도(Computing Density) 증가 속도가 훨씬 빠르다는 점입니다. 두 곡선의 격차가 점점 벌어지고 있어, 시간이 갈수록 프로세서에서 상대적인 메모리 성능 문제는 오히려 더 심해지는 상황입니다. 그래서 LLM 추론을 비롯해 거의 모든 워크로드에서 메모리 대역폭을 얼마나 효율적으로 쓰느냐가 결정적인 성능 지표가 됩니다.
Memory Overhead를 줄이기 위한 기술들
앞서 본 것처럼 Decode는 연산을 그렇게 많이 하지도 않는데 이미 메모리에 바운드되는 상태입니다. 바꿔 말하면 메모리 대역폭을 그만큼 비효율적으로 쓰고 있다는 뜻이기도 합니다. 그래서 LLM 추론 최적화의 무게중심은 자연스럽게 Prefill보다 Decode, 그리고 Decode 단계에서 발생하는 메모리 비효율을 줄이는 방향에 놓이게 됩니다. 이 절에서 다루는 Continuous Batching, Speculative Decoding, Flash Attention, Paged Attention, 모델 경량화는 모두 이 흐름에서 등장한 기술들입니다.
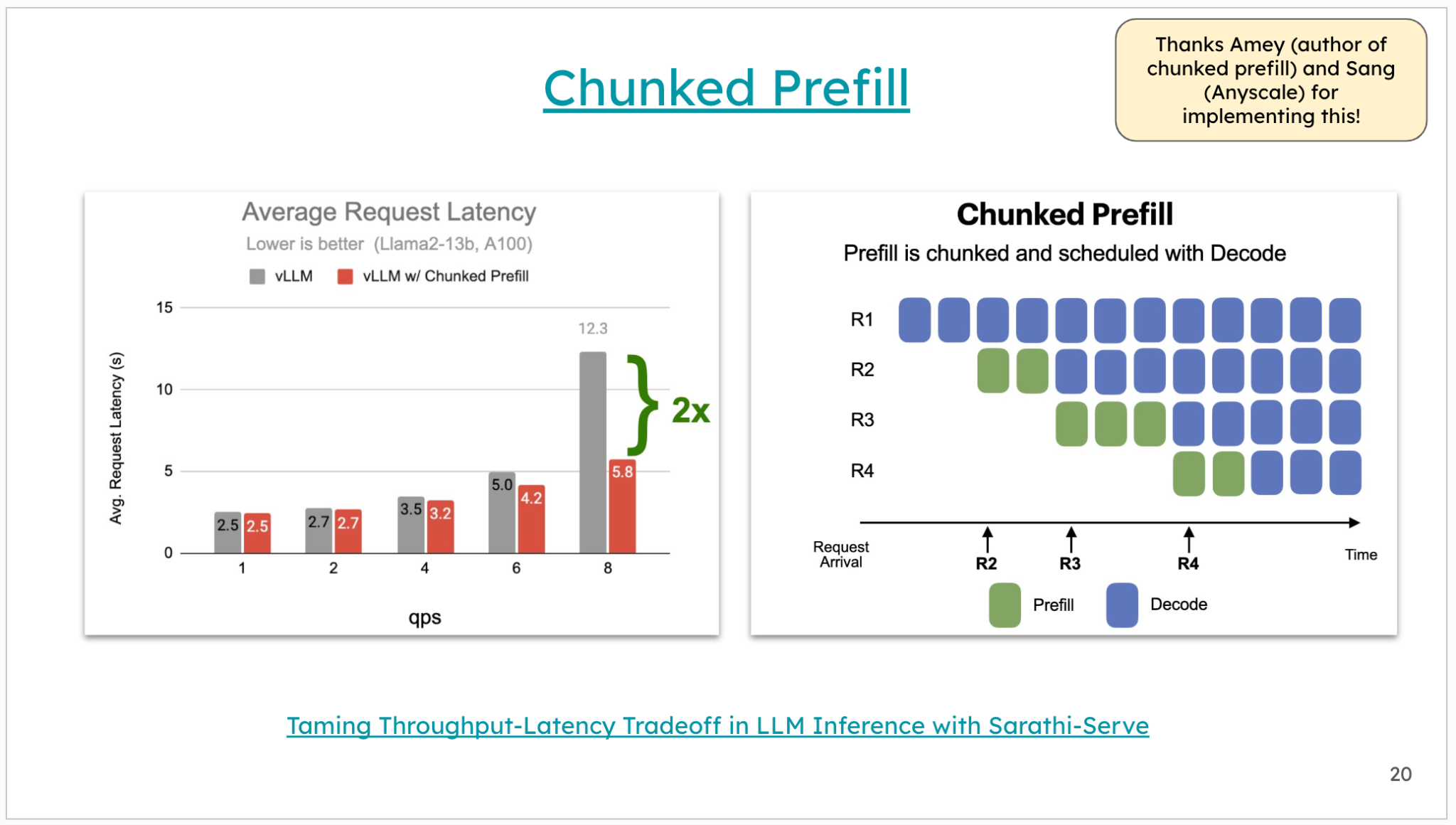
Continuous Batching
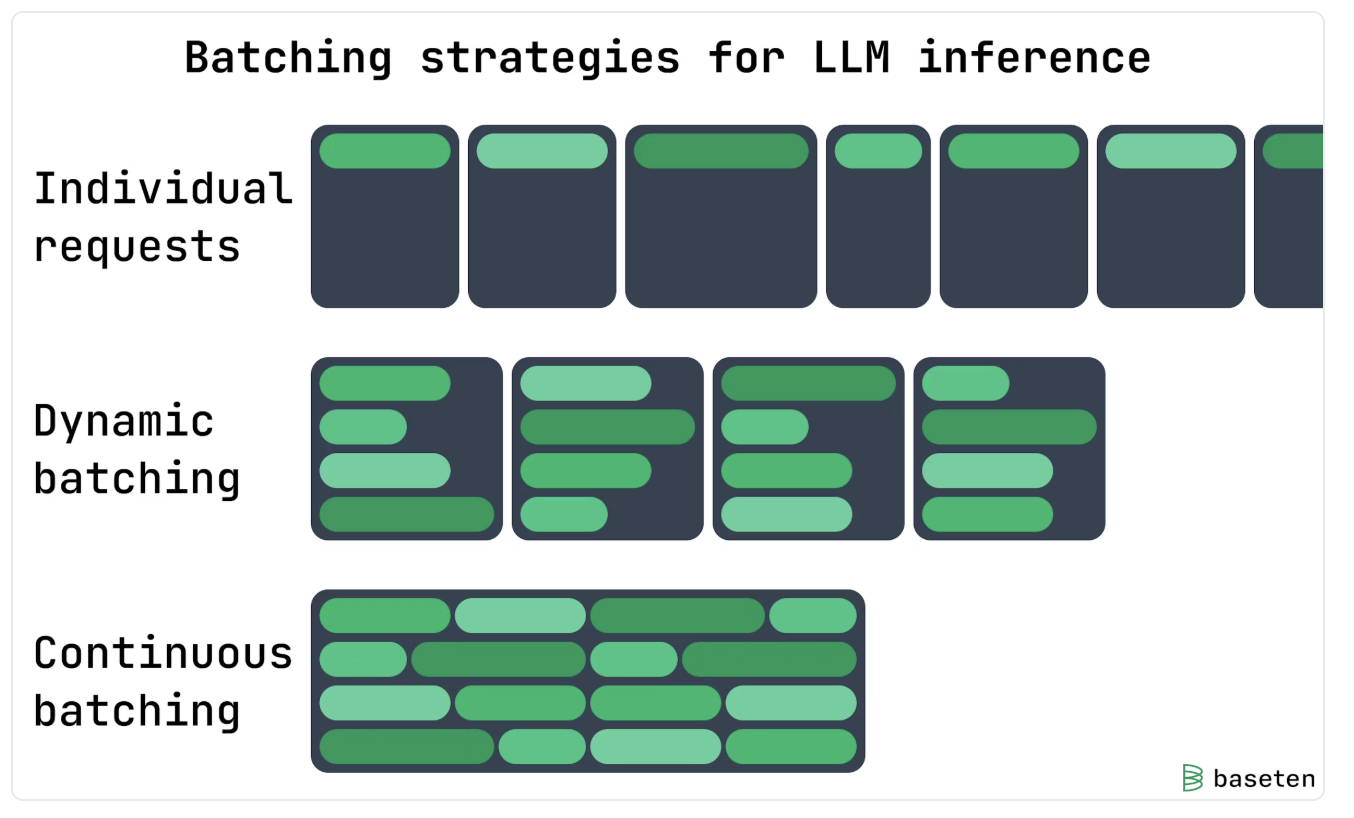
가장 직관적인 발상은 Prefill에서 했던 것처럼 여러 토큰을 동시에 처리하면 된다는 것입니다. 다만 Decode 안에서 한 토큰과 다음 토큰 사이에는 의존성이 있어 그게 어렵습니다. 그래서 여러 request를 묶어 병렬로 돌리는 쪽으로 시선을 돌립니다.
가장 단순한 형태가 Static / Dynamic Batching입니다. 여러 request를 묶어서 모든 layer를 lock-step으로 동시에 진행합니다. 메모리 효율은 individual request 처리보다 분명히 올라가지만, 각 request가 얼마나 빨리/느리게 끝날지 미리 알 수 없다는 게 문제입니다. 한 배치의 모든 request가 같은 lock-step으로 가야 하므로, 가장 느린 애가 끝날 때까지 모두 기다려야 하고, 빈 자리가 생겨 원하는 만큼 성능이 안 나옵니다.
이를 해결하기 위해 등장한 것이 Continuous Batching입니다. 아이디어는 각 layer 단계마다 동적으로 끼어들어, 같은 순서에 있는 토큰들을 그때그때 묶어 병렬로 처리하는 것입니다. 시퀀스 길이가 서로 달라도 빈 슬롯을 찾아 빡빡하게 채울 수 있어서, lock-step 방식의 낭비를 거의 없앱니다.
대표적인 출발점은 서울대 전병곤 교수님의 Orca 논문이고, 이 기술을 기반으로 설립된 회사가 Friendli AI입니다. 현재 Continuous Batching은 LLM 서빙에서 사실상 필수 기술이 되었습니다.
Speculative Decoding
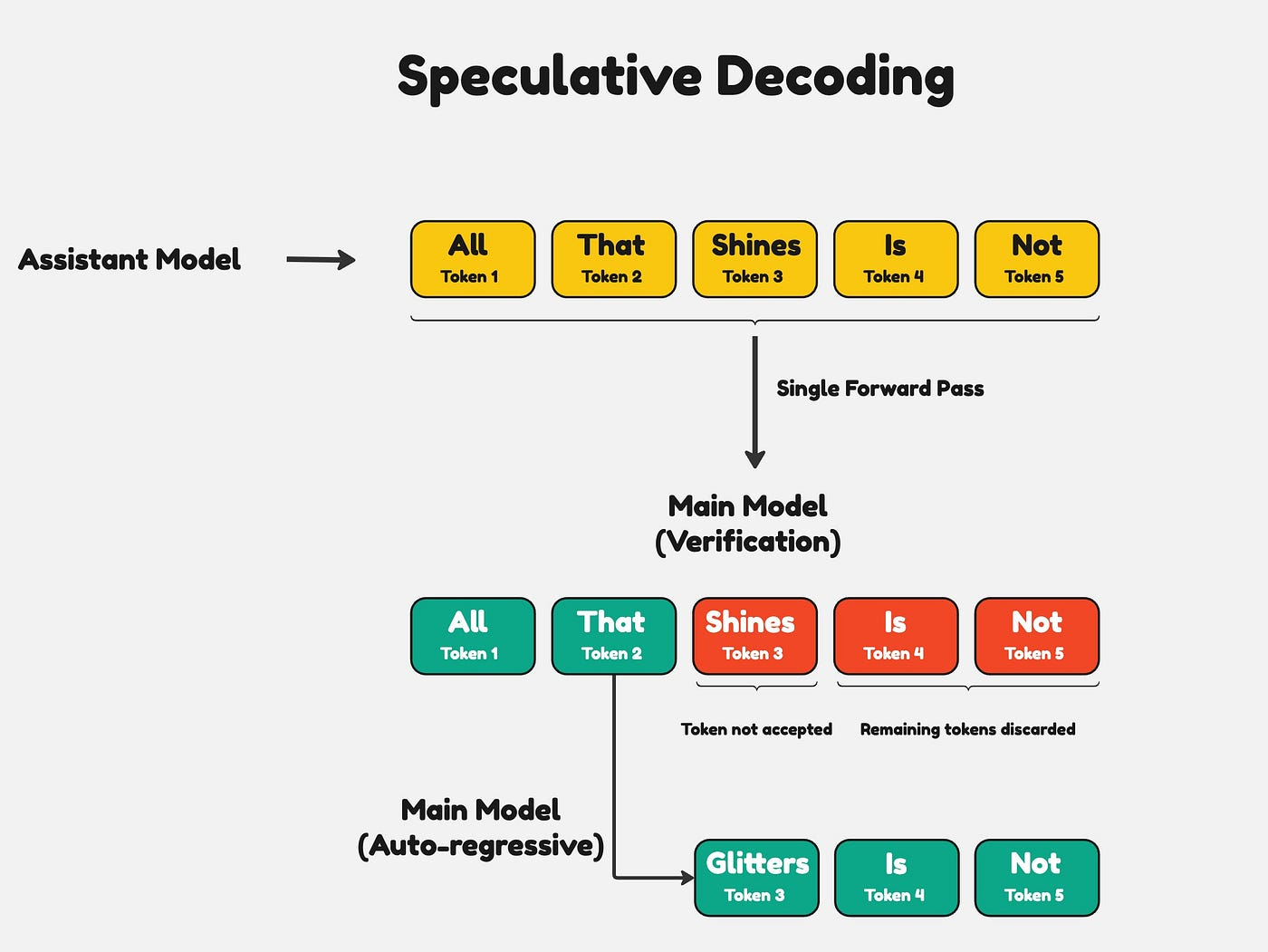
앞서 Decode는 “한 토큰이 끝나야 다음 토큰을 시작할 수 있다 → 병렬화 불가”라고 했습니다. Speculative Decoding은 이 제약을 우회하기 위해 등장한 기법입니다.
큰 모델과 작은 모델이 있다고 할 때, 작은 모델이 큰 모델만큼 정확하지는 않더라도 그렇게 크게 뒤떨어지지는 않는다고 가정해 봅시다. 그렇다면 다음과 같이 두 단계로 일을 나눌 수 있습니다.
- 작은 모델(Draft Model) 로 여러 토큰의 초안을 빠르게 생성한다.
- 큰 모델(Main Model) 로 그 초안이 맞는지 검증만 한다.
여기서 결정적인 포인트는 검증 단계가 본질적으로 Prefill과 똑같다는 점입니다. Prefill을 병렬로 처리할 수 있었던 이유는 “어떤 토큰들을 처리할지 이미 정해져 있는 상태에서 동시에 통과시킬 수 있기” 때문이었죠. 검증해야 할 토큰들도 draft가 미리 만들어 둔, 이미 정해진 토큰 시퀀스이기 때문에 큰 모델이 이를 한 번의 forward pass로 동시에 검증할 수 있습니다.
검증 결과는 두 갈래입니다.
- 모든 토큰이 큰 모델의 예측과 일치 → 전부 accept, 그만큼 한 번에 진척
- 중간 어딘가에서 불일치 → 그 지점 이전까지만 accept, 이후 토큰은 폐기하고 그 지점부터 다시 draft → 검증을 반복
작은 모델이 통계적으로 충분히 의미 있게 동작한다는 점이 받쳐주기 때문에, 실제 효율도 꽤 높다고 평가됩니다. 정리하면 Speculative Decoding은 batching과는 다른 결의 접근으로, 한 request 안에서 “검증”이라는 형태로 문제를 변환해 마치 Prefill처럼 여러 토큰을 동시에 처리할 수 있게 만들어 주는 기술입니다.
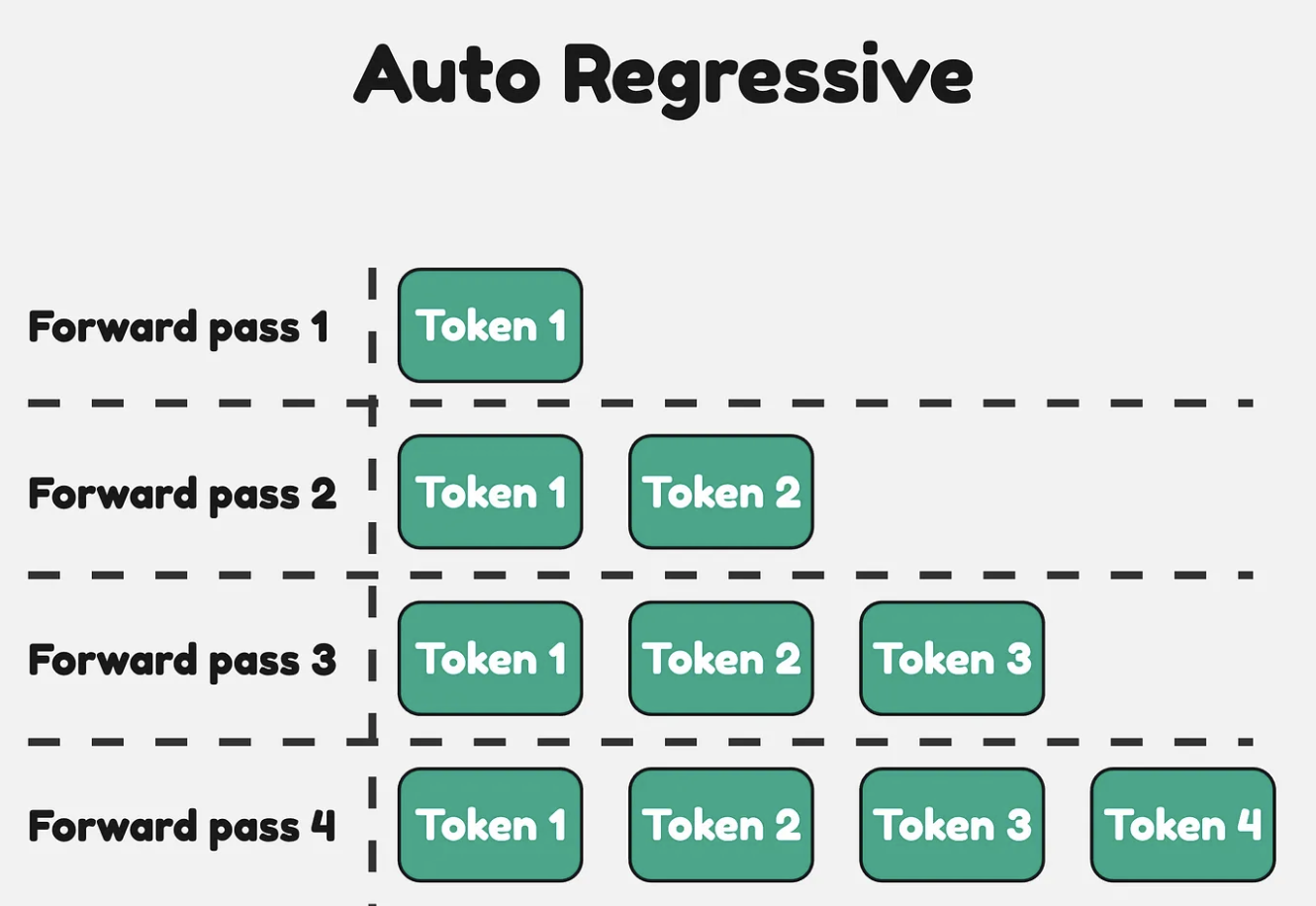
Attention의 비용 문제
여기까지가 “Decode를 어떻게 Prefill처럼 병렬 처리할 것인가” 라는 결의 기술들이었습니다 (Continuous Batching, Speculative Decoding). 그런데 그렇게 병렬화에 성공했다고 끝이 아닌 게, Attention 연산 자체가 본질적으로 꽤 비싼 연산이라는 점이 남습니다. 게다가 시퀀스가 길어질수록 그 비용이 빠르게 불어납니다.
마지막 토큰 하나를 처리하려면 그 전까지 생성된 모든 토큰으로부터 입력을 가져와 Attention을 다시 계산해야 합니다. 한 토큰당 비용이 이고, 그걸 번 반복하니 전체 복잡도는 . 즉 시퀀스 길이 이 두 배가 되면 Attention에 들어가는 메모리와 시간이 4배로 늘어나는 구조입니다. 컨텍스트가 길어지는 추세를 생각하면, 이 자승 항을 어떻게 다루느냐가 LLM 추론 효율의 또 다른 중요한 축이 됩니다.
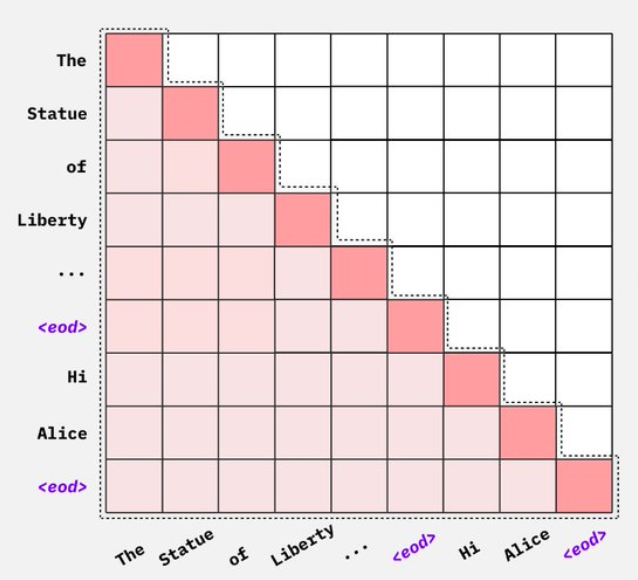
Flash Attention
이 비용 문제를 다루기 위한 대표적인 제안이 Flash Attention입니다. 먼저 분명히 해 둘 것이 있는데, Flash Attention은 Attention의 복잡도를 근본적으로 줄이는 기법은 아닙니다. 자승 항 자체는 그대로 남고, 다만 그것을 훨씬 더 효율적으로 처리할 수 있게 만들어 줍니다. 여기에 쓰이는 도구는 Tiling과 Fusion 두 가지입니다.
기존 Attention 구현의 가장 큰 비효율은 계산 도중에 외부 메모리(DRAM)로부터 데이터를 반복해서 들고 오고, 내보내고, 다시 들고 오는 과정에서 발생합니다. Attention은 여러 단계의 연산(QK 곱, softmax, V 곱, 합산)으로 이뤄져 있는데, 단계마다 중간 결과를 DRAM에 한 번 썼다가 다음 단계에서 다시 읽는 일이 반복되면 그 자체가 큰 오버헤드가 됩니다.
Flash Attention은 이를 타일 단위로 쪼개서(tiling), 한 타일을 처리하는 동안에는 데이터를 칩 안의 on-chip 메모리(shared memory/SRAM)에 한 번만 올려놓고 안에서 모든 단계를 끝까지 끌고 간 뒤(=fusion), 최종 결과만 한 번 DRAM에 내보냅니다. DRAM 왕복이 극단적으로 줄어들기 때문에 같은 연산이라도 실행 속도와 메모리 사용량이 크게 좋아집니다.
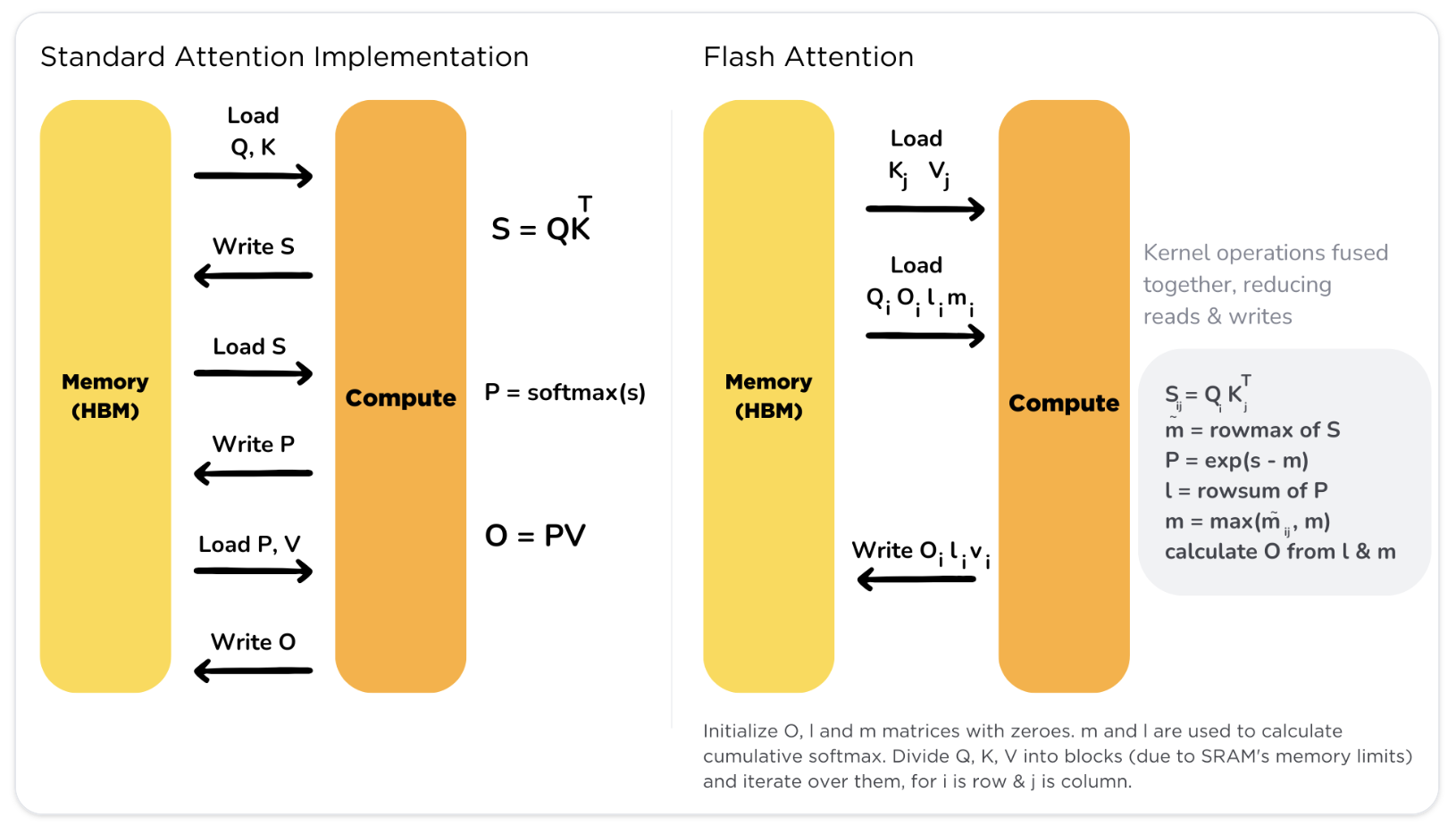
출처: Flash Attention
출처: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
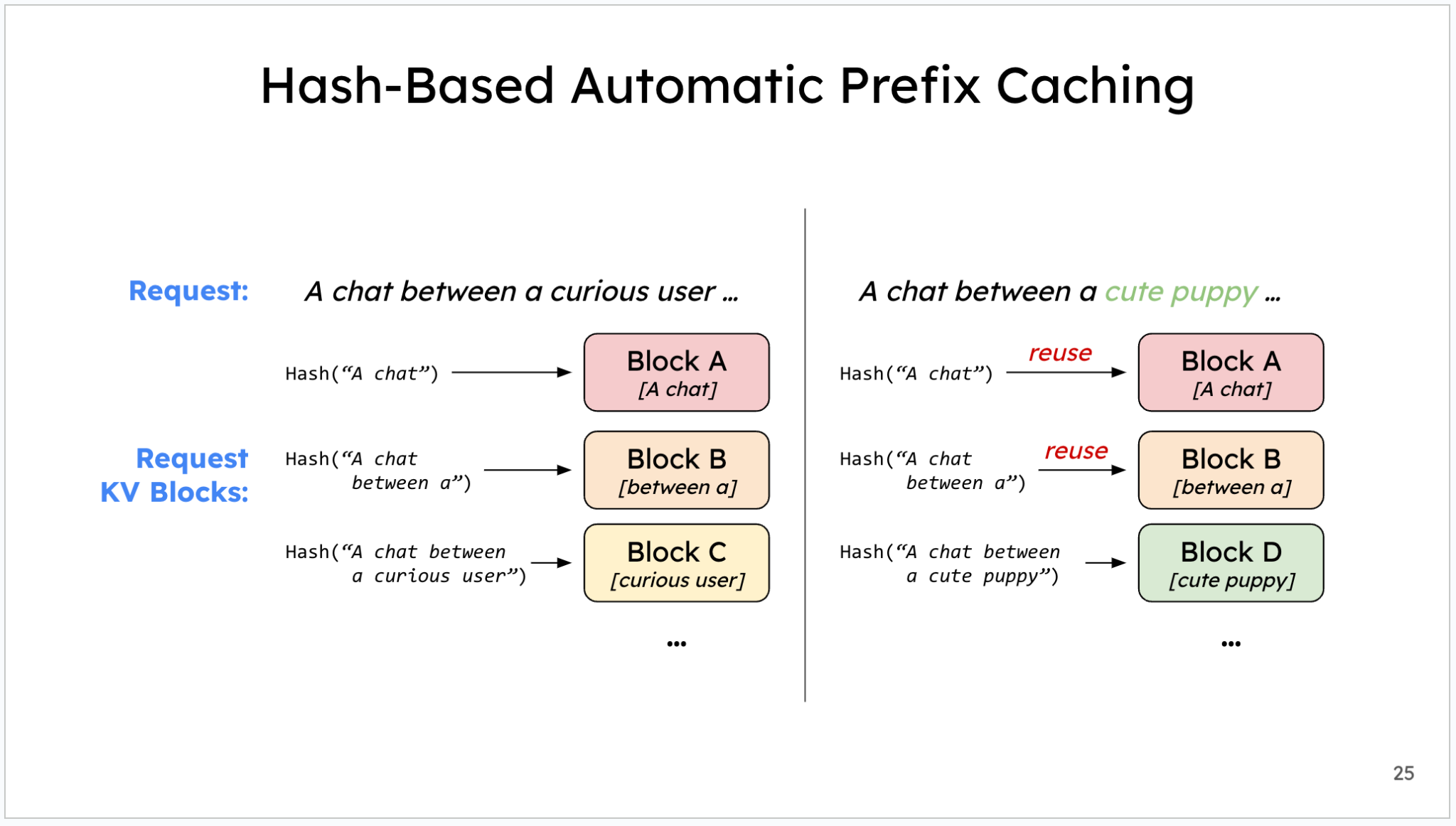
Paged Attention
Paged Attention도 비슷한 결의 문제(긴 시퀀스를 다룰 때의 비효율)를 다른 각도에서 풀어 줍니다. 이번에는 연산이 아니라 KV cache의 메모리 할당 자체가 문제의 출발점입니다.
KV cache를 그냥 잡아두려면 기본적으로 max sequence length 기준으로 한 번에 다 할당해 둬야 합니다. 그런데 실제 들어오는 request들은 시퀀스 길이가 제각각이어서, max에 한참 못 미치는 짧은 request들에서는 잡아만 놓고 안 쓰는 메모리 공간이 잔뜩 생깁니다. 이런 “낭비된 슬롯들” 때문에 같은 GPU 메모리(HBM)에서 동시에 처리할 수 있는 request 수가 줄어들어 처리량이 바운드됩니다.
Paged Attention은 OS의 virtual memory · paging과 거의 같은 발상으로 이 문제를 풉니다.
- Logical cache block - 충분히 많은 request × 충분히 긴 시퀀스를 다 담을 수 있다고 논리적으로만 가정한 큰 주소 공간
- Physical cache block - GPU DRAM(HBM) 위의 실제 한정된 메모리
둘을 decouple해두고, 실제로 채워진 만큼만 physical에 할당(on-demand allocation)합니다. 그 결과 max를 가정한 over-provisioning 없이도 긴 시퀀스를 안전하게 다룰 수 있고, 빈 슬롯 낭비가 사라져 동시에 처리할 수 있는 request 수도 늘어납니다. Flash Attention과 함께 긴 시퀀스의 attention을 효율적으로 처리하는 대표적인 기법으로 널리 쓰입니다.
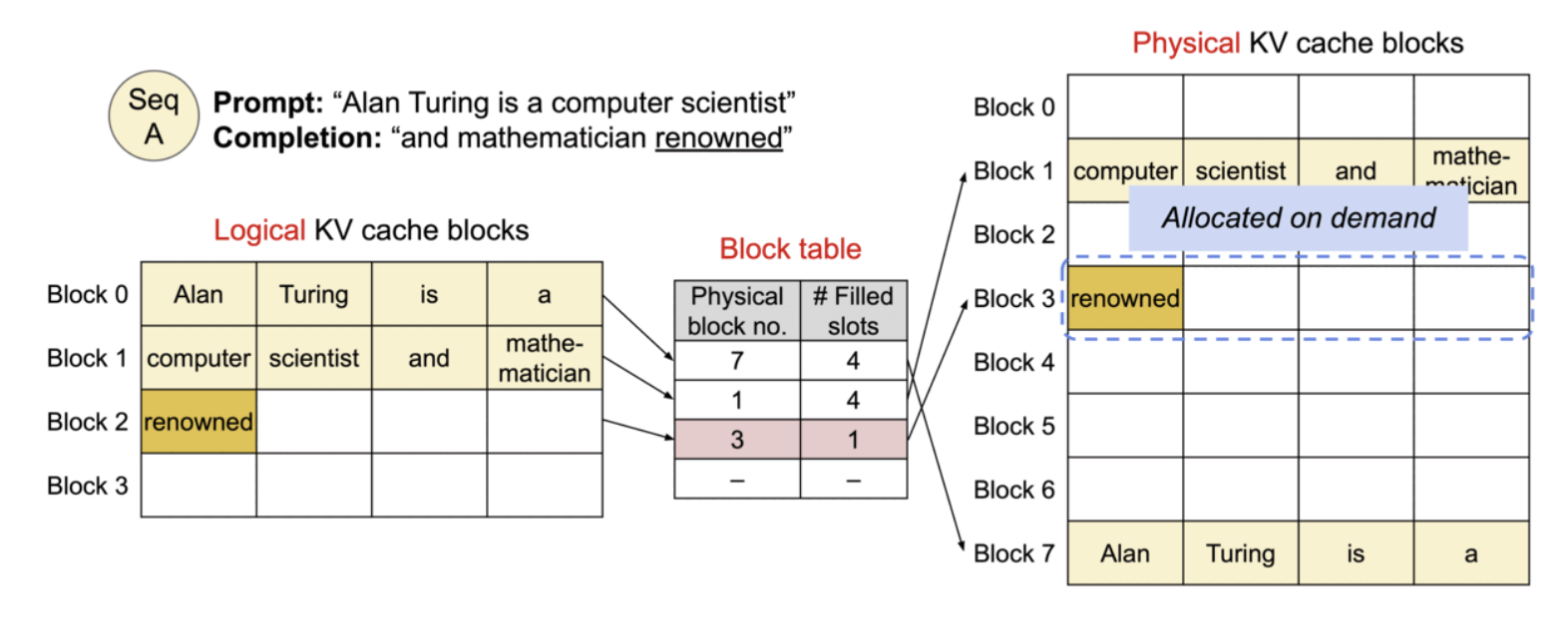
출처: Efficient Memory Management for Large Language Model Serving with PagedAttention
모델 경량화
이 외에도 Quantization(양자화) 이나 Sparsity(희소성) 같은 모델 압축 기술 역시 메모리 overhead를 줄이는 데 함께 활용됩니다. (이 강의에서 자세히 다루지는 않습니다.)
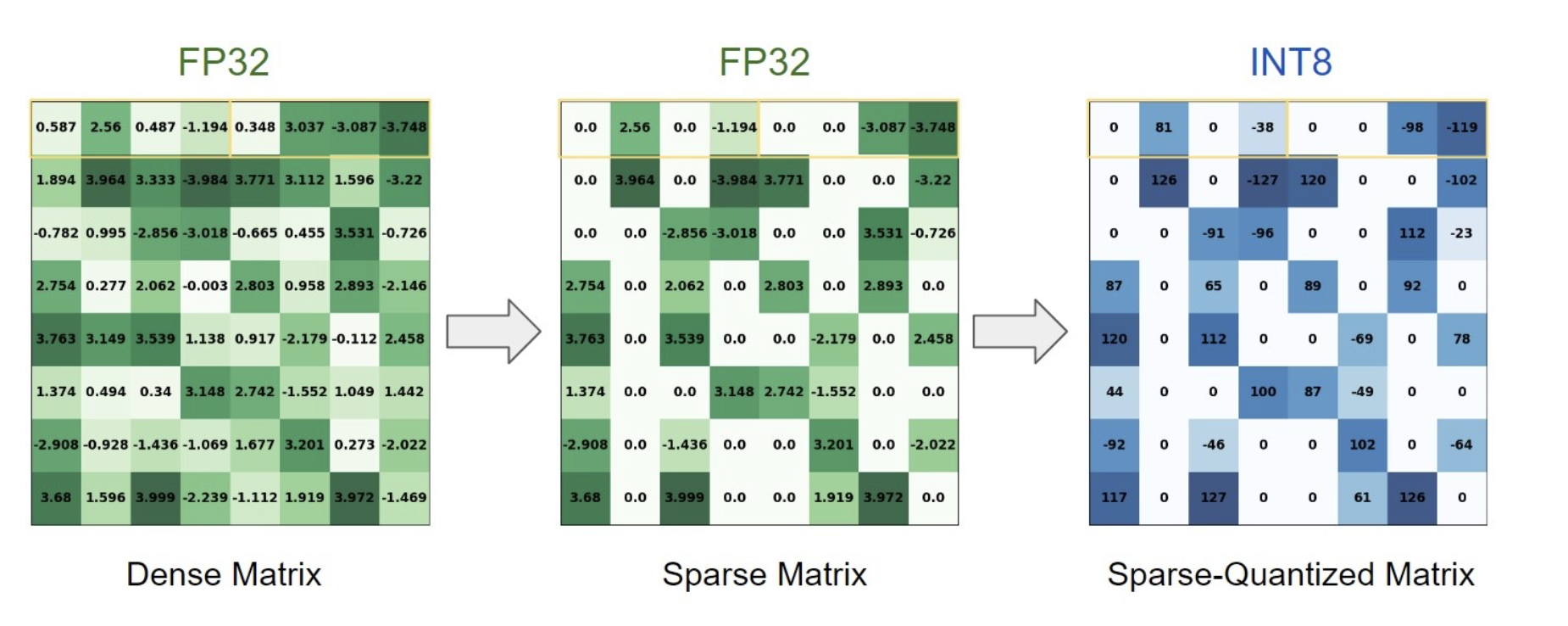
출처: Sparsity in INT8: Training Workflow and Best Practices for NVIDIA TensorRT Acceleration
Kernel Programming
Flash Attention과 GPU-Aware 알고리즘
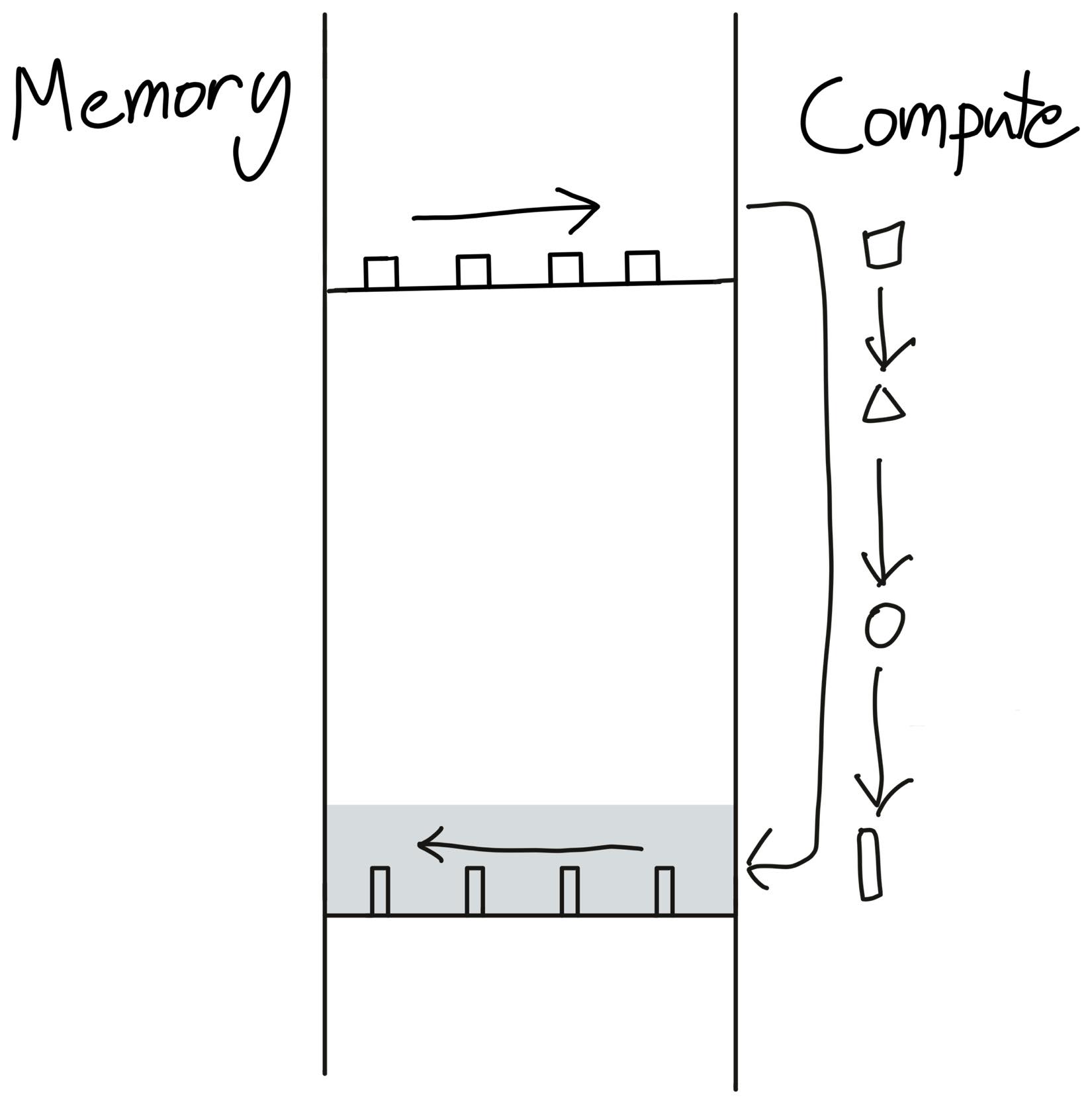
지금까지 본 메모리 오버헤드 감소 기법들의 공통점은 한 가지입니다. 하드웨어 특성을 적극적으로 활용해야 비로소 동작한다는 점이죠. 그런데 정확히 이 지점에서 PyTorch의 Op 추상화는 잘 맞지 않습니다. PyTorch가 우리에게 주는 추상화는 내부 계산을 직접 제어하는 것이 아니라, 이미 정해진 연산을 빌딩 블록으로 조합하는 형태입니다. 게다가 각 op이 (특히 eager 모드에서) 하나의 커널로 매핑되면, 그 커널의 I/O 모델은 사실상 “DRAM에서 읽어 → 계산 → DRAM에 다시 씀”으로 고정됩니다. Flash Attention의 동기였던 “DRAM 왕복을 줄이고 싶다”는 요구를 op 단위로는 표현할 수가 없는 것입니다.
이 한계를 넘으려면 결국 PyTorch op보다 한 단계 낮은 저수준 API로 커널을 직접 작성하고, 그것을 Custom Op으로 wrap해서 PyTorch 레벨에 다시 노출시켜야 합니다. 이게 바로 다음 절들에서 다룰 Kernel Programming의 출발점입니다.
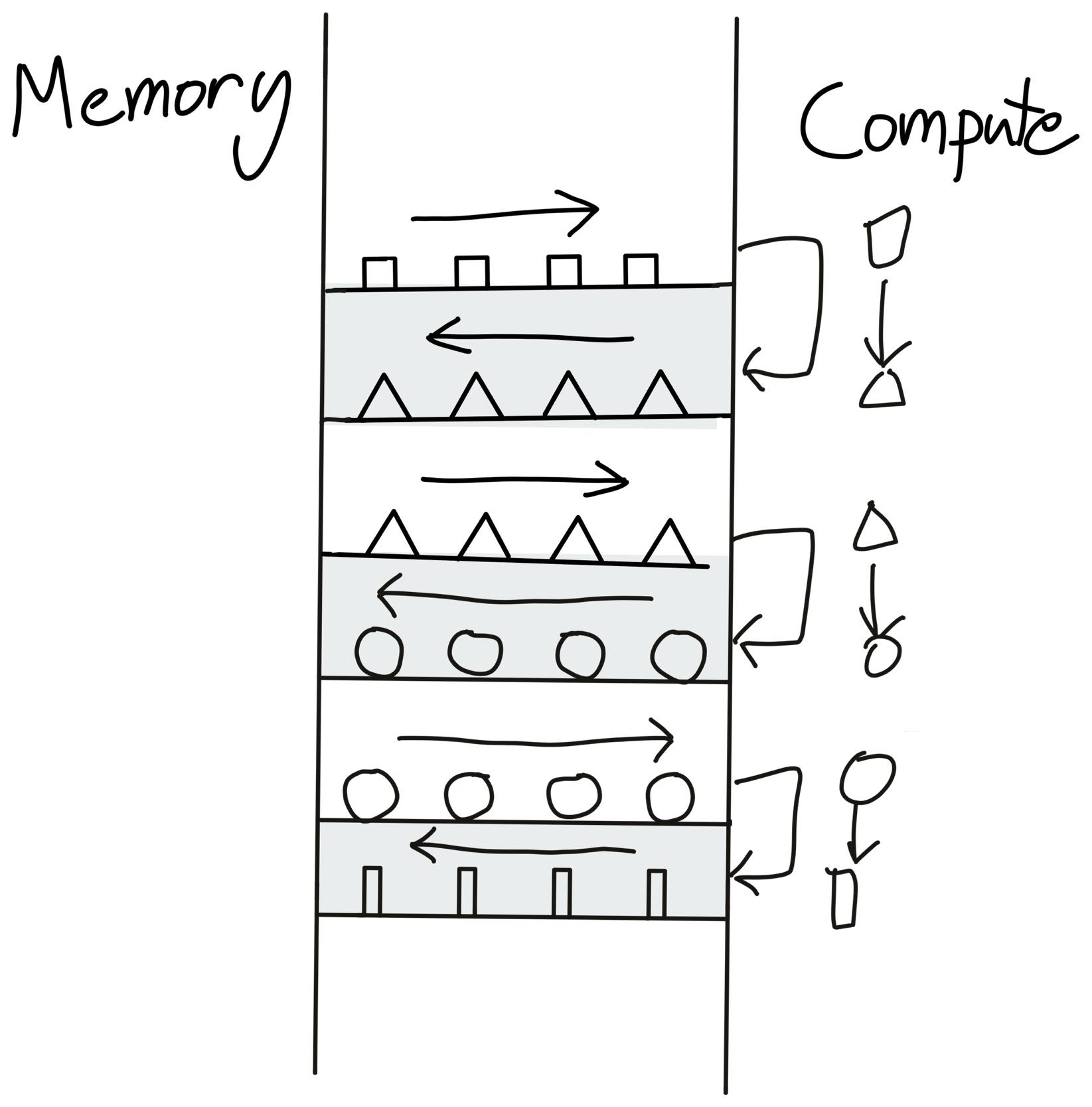
Flash Attention이 가정하는 GPU 모델은 세 가지 요소로 이루어져 있습니다.
- Grid - 대규모로 병렬 처리할 수 있는 연산기들의 집합
- DRAM - 외부 메모리. 용량은 크지만 대역폭이 상대적으로 낮음
- Shared Memory - 블록별로 할당되는 온칩 메모리. 용량은 작지만 대역폭이 훨씬 높음
요점은 같은 데이터라도 DRAM에 두고 계산하는 것보다, 한 번 Shared Memory에 올려놓고 그 안에서 계산하는 편이 훨씬 빠르다는 점입니다. Flash Attention은 입력과 유지해야 하는 데이터가 DRAM에 있더라도 그것을 타일 단위로 쪼개 Shared Memory에 올려놓고, 실제 곱·합 연산은 Shared Memory의 높은 대역폭으로 수행합니다. 결국 질문은 이렇게 정리됩니다. 이런 아키텍처적 특성을 어떻게 알고리즘과 코드에 직접 반영해 줄 것인가?

같은 맥락에서, sequence가 길어질수록 attention 자체가 얼마나 무거워지는지를 한 번에 보여주는 그림은 다음과 같습니다. → mask → softmax → 로 이어지는 전 과정에서 연산량과 메모리 접근량 모두 으로 커집니다.
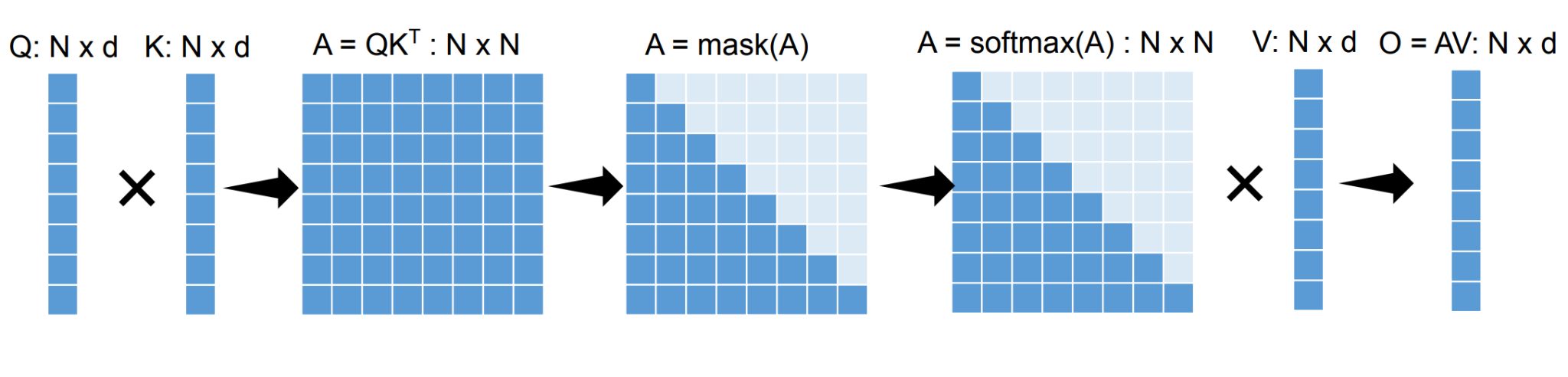
Flash Attention = (Chunked Prefill +) Tiling + Fusion for Attention
Flash Attention은 앞 절에서 본 비효율을 풀기 위해 두 가지 기법을 적용합니다.
- Tiling - 큰 계산을 작게 쪼개서, 그때그때 필요한 부분만 들고 와서 처리할 수 있게 만들어주는 방법
- Fusion - 한 계산에 필요한 모든 데이터를 한 번 메모리(Shared Memory)에 올려놓은 뒤, DRAM에 다시 접근하지 않은 채 가능한 한 많은 연산을 끝내고, 마지막에 결과만 한 번에 내보내는 방식
이 둘을 함께 적용해 attention을 다시 짜면, 같은 연산이라도 메모리를 훨씬 효율적으로 사용할 수 있게 됩니다.
Tiling
큰 행렬을 통째로 처리하는 대신, 결과 행렬을 작은 타일로 쪼개고 각 타일을 만드는 데 필요한 입력 조각만 한 번씩 Shared Memory에 올려 곱·누적합니다. 같은 데이터를 여러 번 DRAM에서 다시 읽지 않고 재사용할 수 있어, 메모리 트래픽이 크게 줄어듭니다.
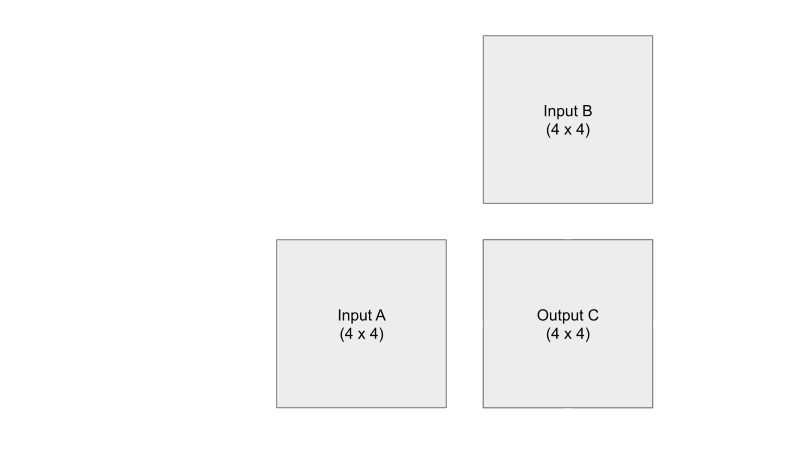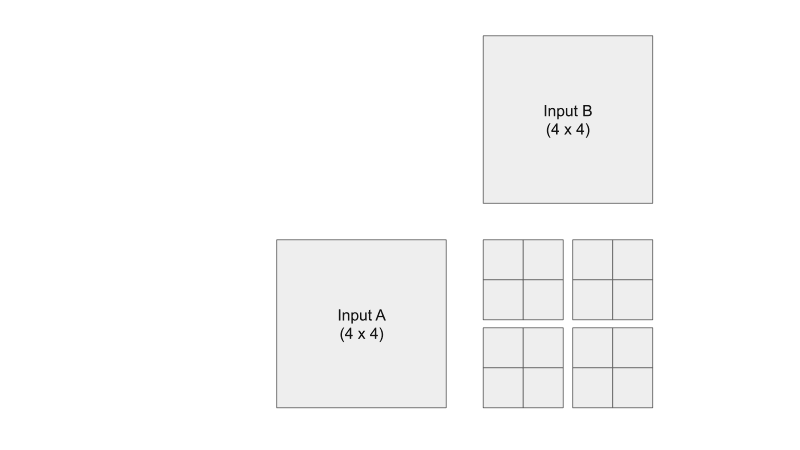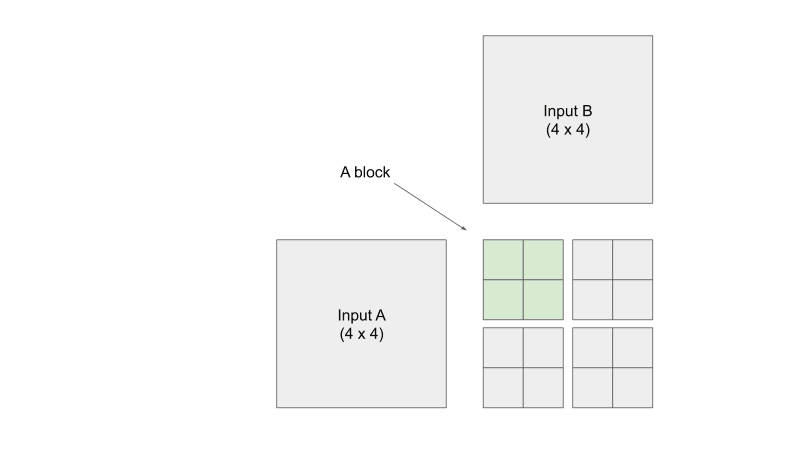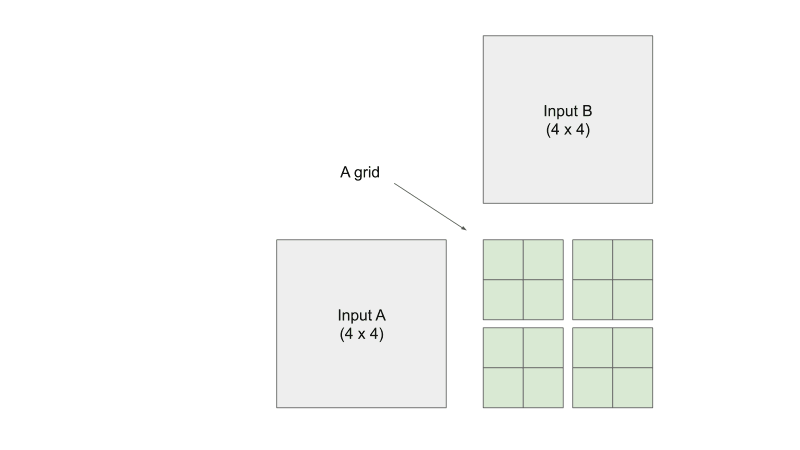
Fusion
여러 op이 한 줄로 이어진 연산 그래프(예: )를 그대로 실행하면, op마다 결과를 DRAM에 썼다가 다음 op이 다시 읽어가는 DRAM 왕복이 반복됩니다. 인접한 op들을 하나의 커널로 합치면(fusion), 중간 결과는 Shared Memory/레지스터 위에 머물고 최종 결과만 DRAM에 한 번 내보낼 수 있습니다.
Attention에 적용하기
이제 이 두 도구를 attention에 그대로 얹어 봅시다. Attention 연산 안에서 각 연산이 tiling과 어울리는 정도는 다릅니다.
- 곱셈 (QK, …V): 자연스럽게 tiling 적용 가능
- Masking: 마찬가지로 tiling 가능
- Softmax: 전체 분포를 봐야 하므로 tiling이 까다로움 - 기술적 챌린지
앞서 본 attention 그림에 이 통찰을 그대로 얹어 보면 다음과 같이 정리됩니다.
곱셈·masking 영역은 직관적으로 tiling이 들어가지만, 중간에 끼어 있는 softmax가 진짜 골치 아픈 부분입니다. softmax는 본질적으로 전체 N개 값을 다 보고 다시 rebalance하는 연산이라, “어떻게 잘 쪼개서 부분적으로 계산할 것인가”가 곧 Flash Attention의 핵심 기술적 챌린지입니다 (다음 절의 Online Softmax에서 다룹니다).
정리
모든 연산이 같은 방식으로 tiling된다면 자연스럽게 fusion까지 함께 적용할 수 있습니다. Flash Attention의 핵심도 결국 이 두 가지(tiling과 fusion)의 결합입니다. 다만 이런 tiling과 fusion은 PyTorch op 단위에서는 표현할 방법이 없어서, 더 저수준에서 알고리즘을 직접 구현하고 그것을 다시 PyTorch op으로 wrap해 노출시켜야 합니다. 다음 절의 Kernel Programming이 바로 그 도구입니다.
Softmax의 도전: Online Softmax
먼저 softmax가 무엇이었는지 다시 한 번 정리해 봅시다. 입력 이 주어지면, 각각을 지수 함수()로 변환하고 그 합으로 나눠 합이 1이 되도록 정규화하는 연산입니다.
Naive softmax (2-pass)
가장 직관적인 형태는 다음과 같습니다.
분모의 합을 먼저 구해야 하기 때문에 두 번의 pass가 필요합니다.
- Pass 1 - 메모리에서 를 한 번 읽어 계산 + 누적합 를 구함
- Pass 2 - (또는 )를 다시 읽어 합으로 나눠 최종 계산
즉 같은 데이터를 메모리에서 두 번 읽어야 끝나는 알고리즘입니다.
Safe softmax (3-pass, 수치 안정성 확보)
여기서 또 하나의 문제가 있습니다. 수치 안정성(numerical stability) 입니다. softmax는 가 들어가기 때문에 가 조금만 커져도 값이 폭발적으로 커집니다. float 표현에는 한계 구간이 있어서, 이 한계를 한 번 넘어 saturate되면 그 시점에서 정확도를 영구적으로 잃어버립니다.
회피하는 방법은 생각보다 간단합니다. 모든 입력에서 최댓값 를 빼주는 것입니다. 분자와 분모에 같은 항이 빠지므로 결과는 변하지 않으면서, 지수의 입력은 항상 으로 묶여 exp 결과가 범위에 머물게 됩니다.
이걸 safe softmax라고 부릅니다. 다만 이번에는 최댓값을 먼저 구하는 pass가 추가로 필요해서 총 3-pass가 됩니다.
- Pass 1 - 를 읽어 계산
- Pass 2 - 를 다시 읽어 의 합 계산
- Pass 3 - 를 다시 읽어 계산
수치 안정성은 보장되지만, 메모리를 세 번이나 읽어야 한다는 큰 오버헤드가 생깁니다. 앞서 본 “DRAM 왕복이 비싸다”는 문제와 정확히 충돌합니다.
일반적인 softmax (2-pass)
↑ Sum을 구하는 pass가 추가로 필요
Numerical stability를 고려한 safe softmax (3-pass)
↑ Max를 구하는 pass가 추가로 필요
FlashAttention의 single-pass 트릭
여기서 FlashAttention이 답하는 질문은 이렇게 정리됩니다. “safe softmax와 거의 같은 효과를, single pass로, 그리고 tiling·fusion된 형태로 구할 수 있을까?” 이를 풀어주는 도구가 online algorithm입니다.
Online algorithm이란 모든 데이터를 한 번에 보고 처리하는 게 아니라, 그때그때 들어오는 값만으로 점진적으로 계산을 보정해 나가는 알고리즘 패러다임을 말합니다. 아이디어는 다음 두 가지입니다.
- 진짜 를 미리 구하지 않는다. 대신 지금까지 본 값 중 최댓값 만 유지한다.
- 새 값이 들어와 가 업데이트되면, 이전 max로 스케일해 두었던 누적 분모를 새 max에 맞게 다시 보정한다.
이 보정 과정만 잘 정의해주면 single-pass로도 safe softmax와 동등한 결과를 얻을 수 있습니다. 이걸 safe softmax의 online 버전이라고 부르고, FlashAttention은 이 아이디어를 그대로 attention 전체로 확장합니다. tile 하나가 들어올 때마다 max를 update하고, 누적된 분모와 출력을 그에 맞춰 보정해 나가면, 단 한 번의 pass만으로 attention을 끝낼 수 있게 됩니다 (그리고 자연스럽게 tiling·fusion까지 함께 적용됩니다).
알고리즘을 의사코드로 적으면 다음과 같습니다. (설명을 위해 한 번에 key 하나, 즉 column 하나씩 처리하는 형태로 적었으며, 실제 FlashAttention은 같은 recurrence를 column들의 블록(tile) 단위로 수행합니다. 초기값은 , 입니다.)
Algorithm FlashAttention
for do
end
Q는 모든 step에 동일
, query는 한 row 고정
K는 번째 column만 읽어들임
, 순차 streaming load (실제 구현은 tile 단위)
매 step마다 max값 update
Update된 max값으로 보정
를 로 rescale
최종 결과를 DRAM에 저장
, single write
결과적으로 softmax의 수치 안정성을 유지하면서도 single-pass + tiled/fused한 알고리듬이 완성됩니다.
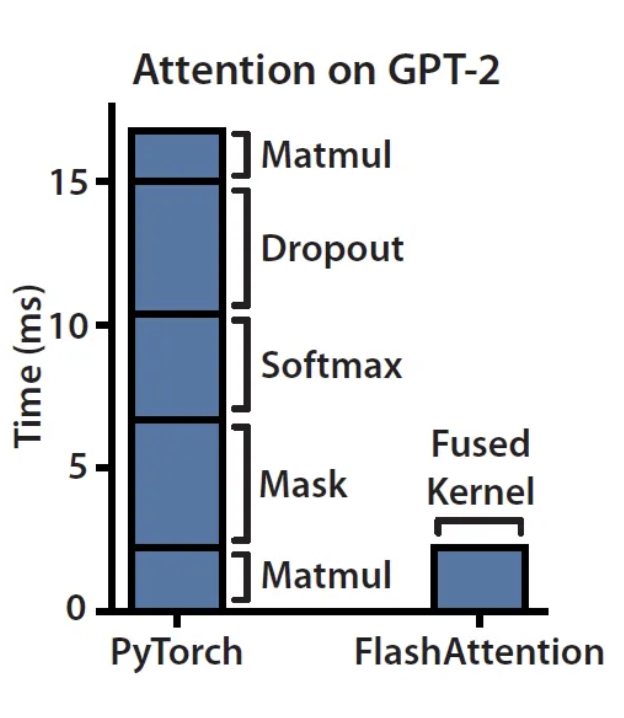
이 과정 전체를 한 줄로 요약하면, FlashAttention은 attention 계산 자체를 restructuring해서 메모리 read/write 횟수를 크게 줄인 알고리즘이고, 이를 처음 제안한 사람이 당시 Stanford PhD 학생이던 Tri Dao입니다. 비교를 위해 기존 방식을 보면, Standard Attention은 모든 단계를 PyTorch op으로 표현하고 그 안에서 cuBLAS 같은 가속 라이브러리를 호출합니다. PyTorch op 단위로는 앞서 본 tiling·fusion을 표현할 수 없기 때문에, 개별 GEMM은 빠르더라도 전체 GPU utilization은 낮은 상태로 남습니다. FlashAttention v1은 정확히 이 한계를 깨고 속도를 끌어올린 첫 버전입니다.
FlashAttention의 진화: v1 → v2 → v3
버전별 진화는 다음과 같이 정리할 수 있습니다.
Standard attention
Low utilization
FlashAttention v1
Tiling
Fusion
~25% utilization
FlashAttention v2
Removal of non-matmuls
Better warp partitioning
50–70% utilization
FlashAttention v3
Optimized for Hopper
(async copy · low-precision)
~75% utilization
v1: CUDA 기반의 첫 구현
FlashAttention v1은 NVIDIA의 CUDA로 직접 구현되었습니다. Standard Attention 대비 속도는 분명히 빨라졌지만, GPU utilization은 약 25% 수준에 그쳤습니다. 알고리즘적 재구성은 끝났는데, 정작 GPU의 자원을 다 끌어쓰지는 못한 셈입니다.
v2: CUTLASS로 warp 파티셔닝 개선
Tri Dao가 다음으로 주목한 것은 CUTLASS입니다. CUTLASS는 CUDA 위에 올라간 C++ template 라이브러리로, NVIDIA GPU의 하드웨어 구조(warp, MMA 등)를 템플릿 형태로 모델링해 두어 코드 자체를 GPU 파이프라인에 맞춰 짤 수 있게 해줍니다. FlashAttention v2부터는 생짜 CUDA 대신 CUTLASS를 활용해 warp 단위 분할(warp partitioning)을 훨씬 정교하게 설계했고, 그 결과 GPU utilization을 50–70%대까지 끌어올렸습니다.
v3: Hopper의 새 기능 활용
이후 NVIDIA Hopper 아키텍처가 등장하면서 새로운 기능들이 추가됐습니다. 저정밀(low-precision) 연산 지원 강화, 비동기 데이터 복사(TMA)와 비동기 Tensor Core 연산(WGMMA) 등이 그 예입니다. 그런데 v2를 그대로 Hopper에서 돌리면 이 새 기능들을 활용하지 못해 utilization이 오히려 30%대로 떨어집니다. 이를 다시 끌어올리려고 새로 짠 것이 FlashAttention v3이고, Hopper에서 utilization을 약 75%까지 회복했습니다.
Takeaway: “CUDA 직접 = 저수준 = 빠르다”는 더 이상 자명하지 않다
흔히 “NVIDIA가 제공하는 저수준 API”라고 하면 곧바로 CUDA를 떠올리지만, 요즘 NVIDIA 아키텍처는 옛날의 깔끔한 SIMT 아키텍처가 아니라서 CUDA만 직접 써서 풀 성능을 내는 일은 매우 어렵습니다. 결국 CUTLASS처럼 하드웨어를 잘 인지(hardware-aware)하는 라이브러리를 거쳐 프로그래밍해야 비로소 GPU의 실효 성능을 끌어낼 수 있는 시대입니다. 다음 절에서 이 부분을 좀 더 들여다봅니다.
GPU 아키텍처의 진화와 CUTLASS
GPU 아키텍처는 CUDA가 가정했던 깨끗한 SIMT 아키텍처에서, 다양한 최적화 기능이 추가되면서 현저히 복잡해졌습니다.
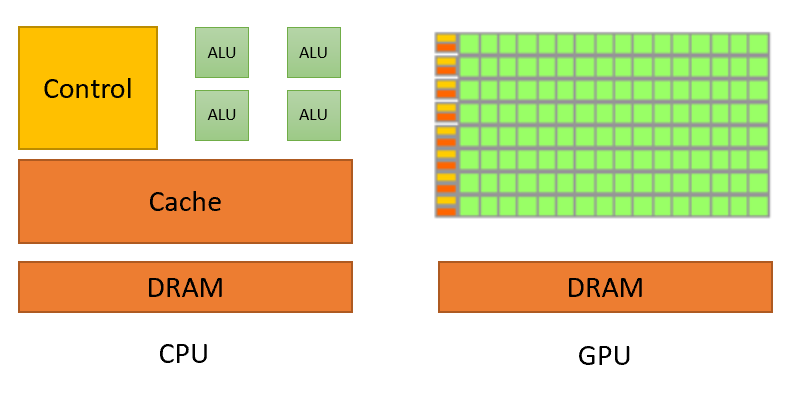
CUDA가 가정한, 깨끗한 SIMT 아키텍쳐

최적화 기능이 추가되면서 현저히 복잡해진 최근 GPU
CUTLASS는 이렇게 복잡해진 GPU의 계층적 병렬 수행을 개발자가 직접 control할 수 있도록 C++ template을 제공하는 라이브러리입니다.
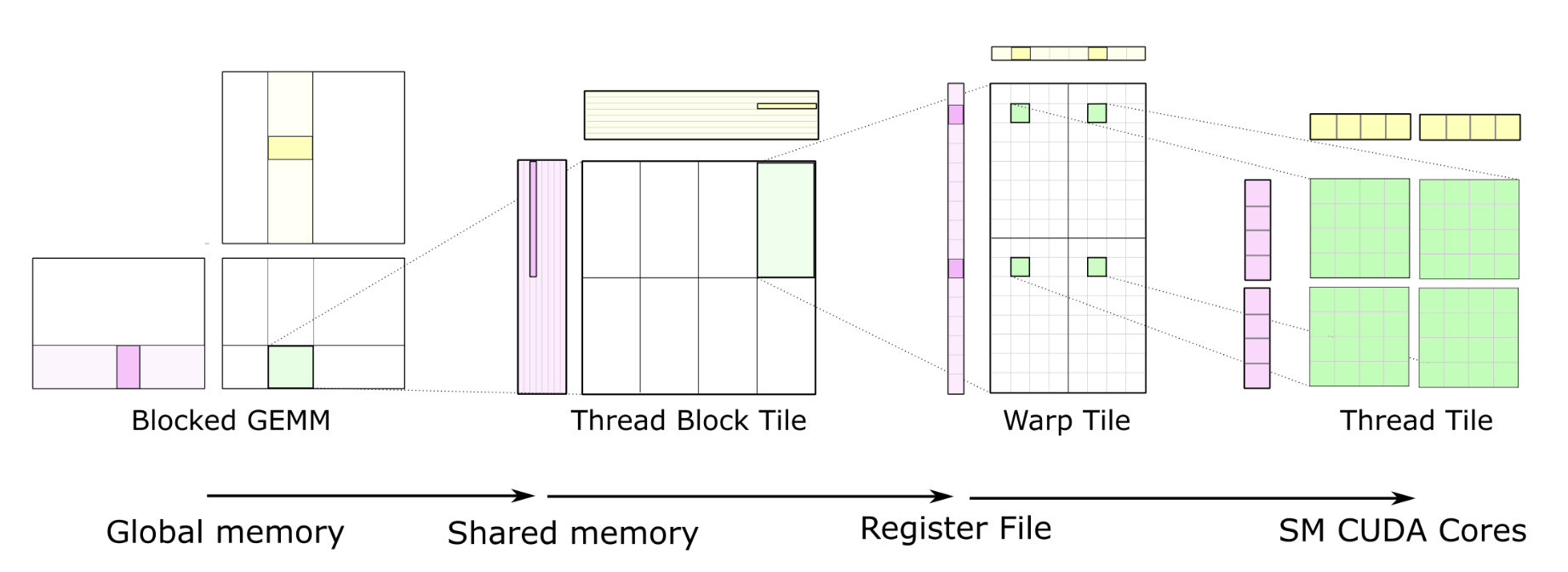
하지만 최적화된 CUDA Kernel을 작성하는 것은 여전히 만만치 않습니다. GEMM 커널 하나를 GPU peak 성능에 가깝게 끌어올리는 데 어떤 기법을 거쳐야 하는지가 다음 슬라이드 한 장에 잘 드러납니다.

정리하면 다음과 같습니다.
- 일반적인 프로그래머가 CUDA Programming Guide만 보고 짠 코드 - GPU 활용도 약 10% 수준
- CUTLASS 같은 가속화 템플릿을 잘 활용 - 이론 peak의 약 80–90% 까지 도달 가능
- 그래도 마지막 10%는 안 채워짐 - CUTLASS로도 표현되지 않는 세부 하드웨어 최적화가 존재하고, 이건 NVIDIA 내부 비공개 소스(cuBLAS)에만 반영되어 있는 것으로 보입니다. 그래서 진짜 100%에 가까운 성능을 내려면 NVIDIA만 쓸 수 있는 그 비공개 구현을 호출해야 합니다.
GPU 하드웨어는 겉보기엔 단순해 보이지만, 실제로 풀 성능을 끌어내려면 이렇게 여러 단계의 굉장히 복잡한 과정을 거쳐야 한다는 점이 잘 알려져 있습니다.
출처: Towards Agile Development of Efficient Deep Learning Operators
출처: Practical Performance Optimization for Deep Learning Applications
Triton: CUDA 대안 오픈소스
이런 흐름에서 많이 들어보셨을 기술이 Triton입니다. Triton은 Harvard PhD 학생이던 Philippe Tillet이 박사 과정 중에 만든 기술로, 이후 OpenAI의 지원을 받아 오픈소스 프로젝트로 강하게 밀고 있는 결과물입니다. 특히 PyTorch 2.0이 발표되면서 그래프 모드의 컴파일러인 Inductor가 GPU 커널을 생성할 때 사용하는 코드 생성 타깃 언어로 채택되어, 한순간에 훨씬 더 널리 쓰이기 시작했습니다.
많은 사람들이 Triton을 CUDA의 대안으로 보는데, 그 이유는 분명합니다. CUDA의 복잡성은 감추면서, 정작 중요한 tiling·fusion 같은 표현력은 그대로 살리는 식으로 설계되었기 때문입니다. 개발자에게 필요한 직관(어떻게 묶고 자르는가)은 손쉽게 표현하게 해주고, 그 외의 GPU-specific한 최적화 디테일은 컴파일러가 알아서 처리합니다. 이 덕분에 PyTorch 2.0 채택 이후 많은 회사들이 Triton에 큰 관심을 갖고 있고, 리벨리온도 마찬가지로 Triton을 비중 있게 보고 있습니다.
오늘 이 강의에서 Triton 자체의 디테일을 깊게 다루지는 않지만, CUDA 같은 proprietary 커널 프로그래밍 모델의 오픈소스 대안으로서 자리 잡아가고 있다는 점은 짚어둘 만합니다. (이번 절 전체에서도 마찬가지로, CUDA가 어떻게 생겼나 / CUTLASS가 어떻게 생겼나보다는 왜 커널 프로그래밍이 필요한가, 어떤 최적화를 하기 위해서인가를 중심으로 짚었습니다.)
“OpenAI’s Triton is very disruptive angle to Nvidia’s closed-source software moat for machine learning.”
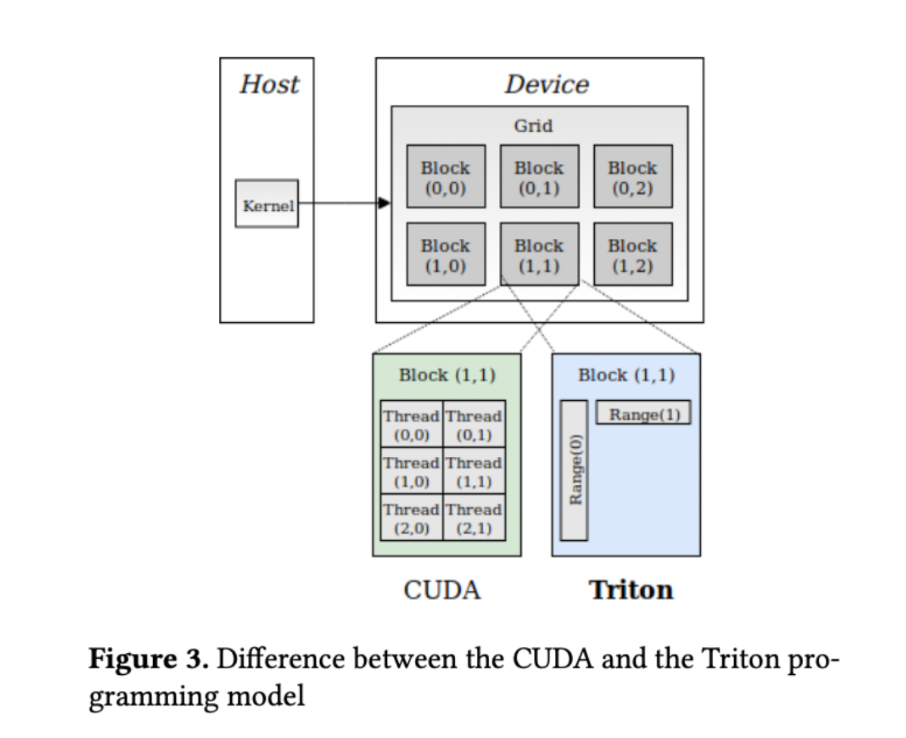
Triton의 핵심은 Block Programming Model입니다. CUDA와 Block Programming 간에는 Semantic Gap이 크지만, Triton은 개발자가 의도를 손쉽게 표현할 수 있는 block programming model을 제공하고, GPU 최적화를 위한 세부 사항은 컴파일러 기술로 해결합니다.
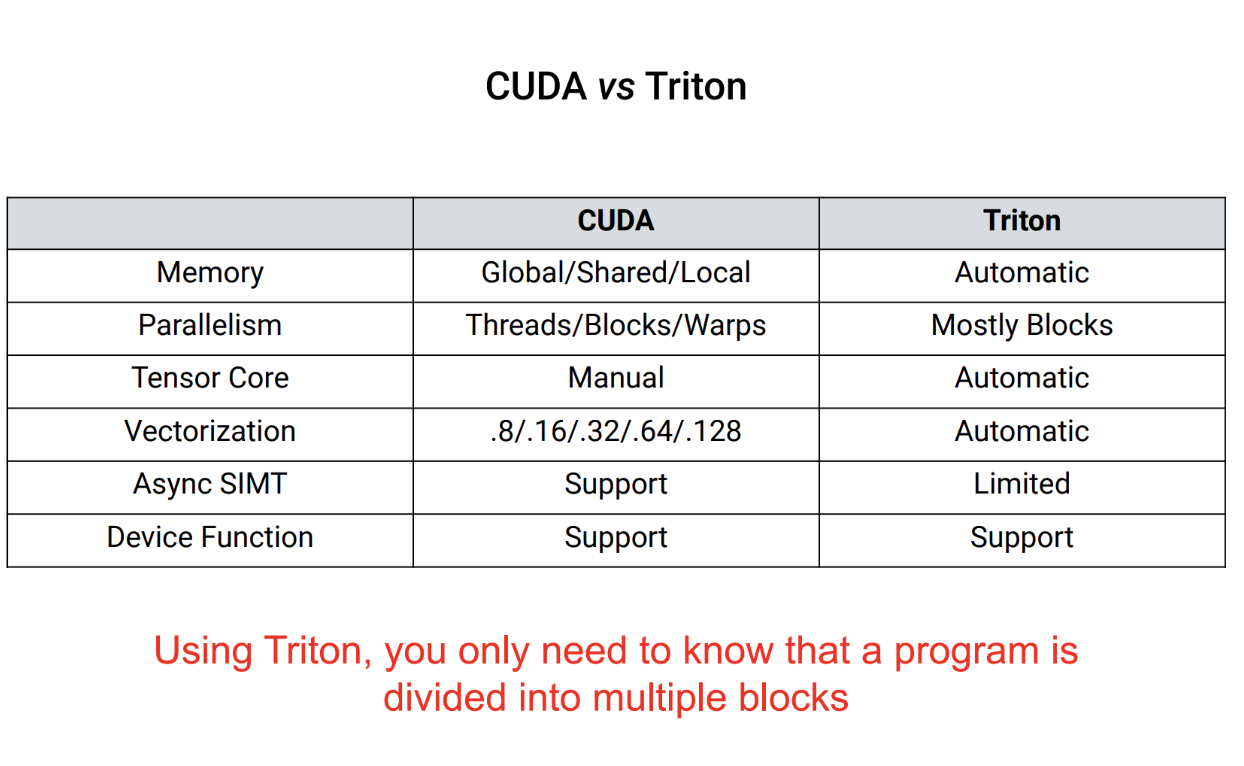
- CUDA와 Block Programming 간의 Semantic Gap이 큼
- Triton은 개발자가 의도를 손쉽게 표현할 수 있는 “block programming model”을 제공
- GPU 최적화를 위한 detail은 컴파일러 기술로 해결
또 한 가지 주목할 점은 Triton이 지원하는 백엔드의 폭입니다. NVIDIA GPU에 한정되지 않고, GPU부터 AI 가속기, CPU까지 사실상 주요 하드웨어 카테고리를 모두 커버합니다. Triton Conference 2024 기준으로 다음 백엔드들이 공식적으로 언급됩니다.
즉 같은 Triton 코드가 NVIDIA·AMD·Intel·AWS·Qualcomm·Azure·ARM·x86 위에서 모두 돌 수 있다는 뜻이고, 이는 Triton이 오픈소스 + 하드웨어 중립 커널 프로그래밍 모델을 지향하고 있음을 보여줍니다.
Serving 최적화 Framework
또 다른 축은 더 위쪽, 서빙(serving) 레이어입니다. 앞서 본 Continuous Batching, Speculative Decoding 같은 고수준 최적화 기법들이 점점 더 서빙 프레임워크 내부의 기본 기능으로 흡수되고 있습니다. 즉 오늘날 LLM 추론 스택을 보면, 모델·커널 위에 Inference Engine과 Inference Server가 한 층 더 얹혀 있고, 우리가 다룬 batching·decoding·KV cache 관리 같은 기법들이 이 층에서 기본으로 동작합니다.
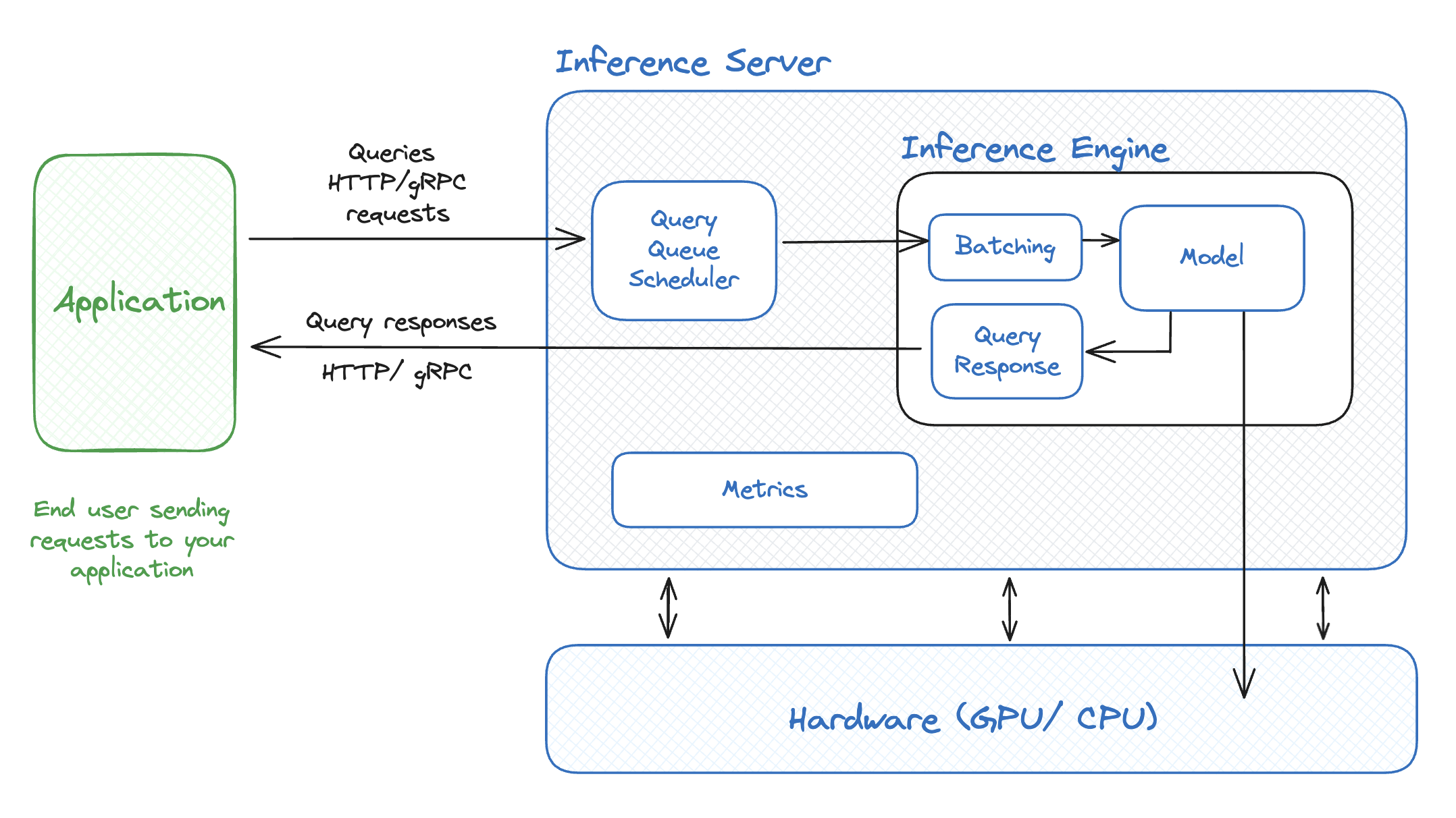
vLLM: LLM Serving의 업계 표준
이런 흐름의 대표 주자가 바로 vLLM입니다. vLLM은 앞서 다룬 PagedAttention을 만든 PhD 학생들이 시작한 프로젝트로 출발했고, 오픈소스 생태계에서 빠르게 성장하면서 지금은 거의 업계 표준(industry standard)처럼 쓰이고 있습니다.
vLLM에 반영된 주요 최적화 기법

앞서 다룬 중요한 최적화 기술들은 대부분 vLLM에 반영되어 있습니다.

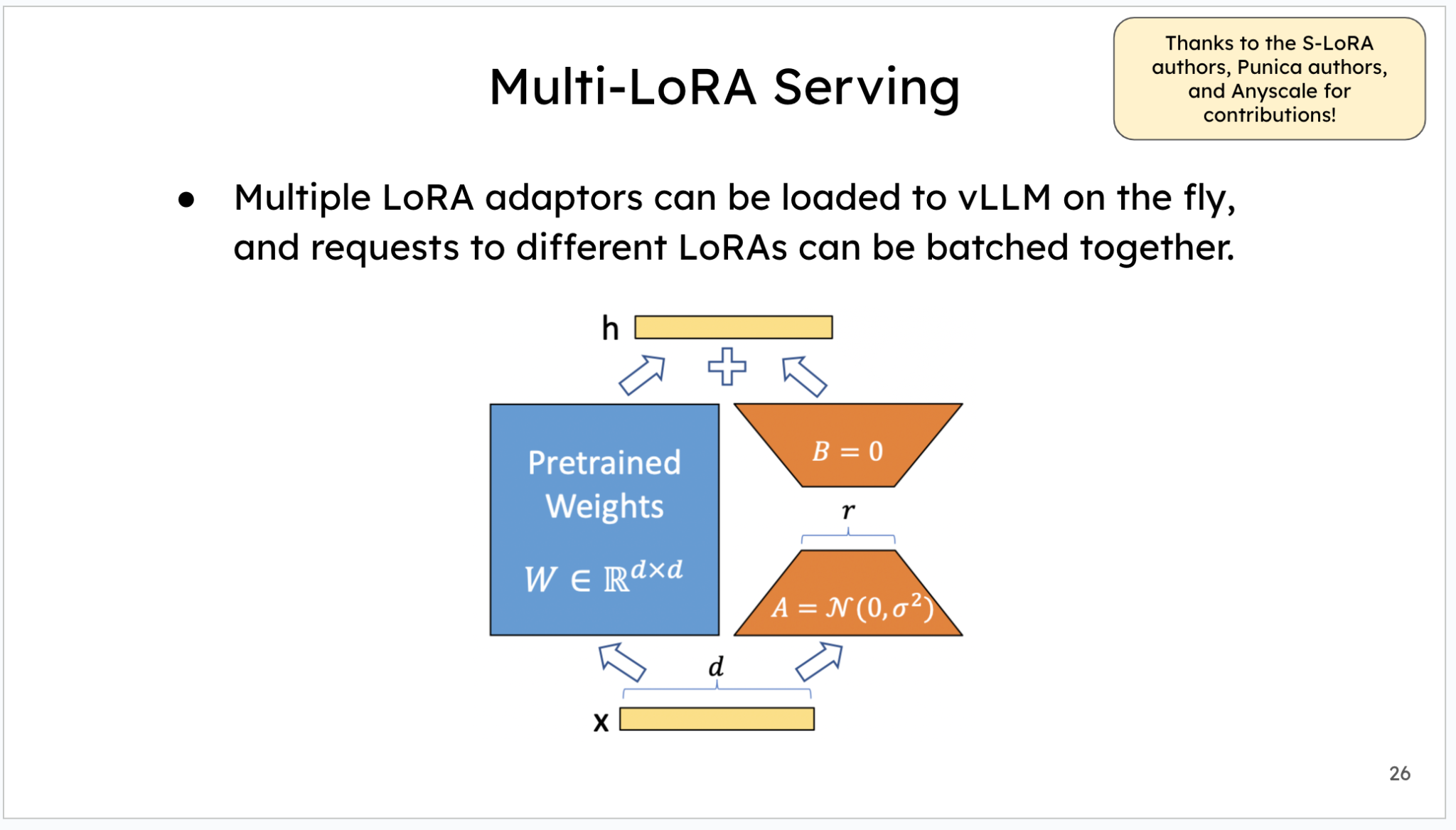
vLLM의 PyTorch 중심 전략
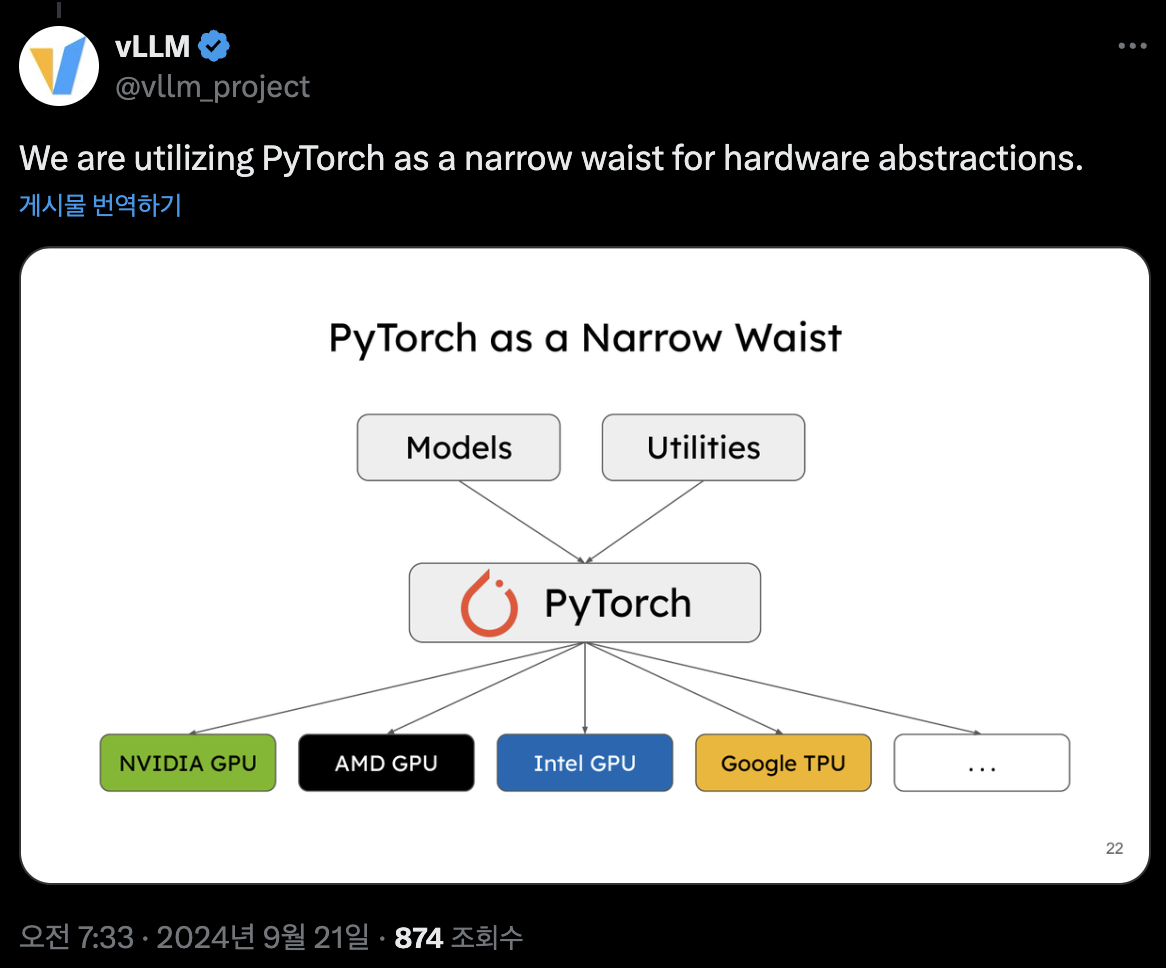
여기서 한 가지 재미있는 점은, vLLM이 PyTorch 기반으로 만들어져 있다는 사실 그 자체보다도, 다양한 하드웨어를 직접 붙이지 않겠다고 명시적으로 선언했다는 점입니다. vLLM 측의 입장은 “하드웨어는 일단 PyTorch에 잘 붙여 오기만 하면, 그 위에서 vLLM이 동작하도록 우리가 만들겠다” 에 가깝습니다.
구조적으로 보면 아래에 하드웨어가 있고, 그 위에 PyTorch가 추상화 레이어 역할을 하며, 그 위에 다시 vLLM이 올라갑니다. 즉 vLLM 입장에서 하드웨어 다양성에 대한 대응은 PyTorch 레이어를 통해 위임하는 셈입니다.
이 점은 AI 반도체 회사, 특히 추론에 최적화된 NPU를 만드는 입장에서 굉장히 중요합니다. PyTorch만 잘 지원해두면 vLLM에서도 자연스럽게 우리 하드웨어가 활용될 수 있다는 뜻이기 때문입니다. 결국 우리 같은 회사 관점에서는 PyTorch 지원 + vLLM 활용 가능성, 이 두 축을 모두 잘 갖춰두는 것이 중요합니다.
기타 상용 프레임워크
서빙 프레임워크 풍경을 좀 더 넓게 보면 이렇습니다.
- 오픈소스 - 앞서 본 vLLM이 사실상 보편적으로 쓰이는 표준
- 상용(proprietary) - Fireworks AI, Together AI, Friendli AI처럼 자체 최적화 기술을 가진 서빙 프레임워크 회사들이 존재하며, 활발히 펀딩을 받고 사업화를 진행하고 있습니다
즉 이 영역은 오픈소스 + 상용 솔루션이 함께 빠르게 성장 중인 시장이고, 어느 쪽이든 모두 앞서 다룬 batching·decoding·attention 최적화를 자기 방식으로 구현해두고 있습니다.
정리
여기까지가 오늘 준비한 내용입니다. 흐름을 다시 한 번 짚어 보면, 먼저 Prefill과 Decode가 계산 측면에서 어떻게 다른가를 봤습니다. Prefill은 utilization이 높은 반면 Decode는 낮고, 이 비대칭을 메우기 위해 사람들이 어떤 최적화 기법들을 만들어 왔는지 차례로 살펴봤습니다.
먼저 batching: 여러 request를 묶어 처리하는 기본 발상에서 출발해, 시퀀스 길이가 들쭉날쭉해도 높은 utilization을 유지하기 위한 continuous batching이 등장했습니다. 시퀀스가 길어지면서 attention 자체가 dominant한 비용이 되는 문제는 Flash Attention, Paged Attention 같은 기법으로 풀고, 한 request 안 Decode 단계의 sequential dependency는 speculative decoding으로 검증 문제로 전환해 풀어냅니다.
Flash Attention을 깊이 들여다보면서 왜 이런 알고리듬을 PyTorch op으로는 표현할 수 없고 kernel programming이 필요한지를 짚었고, 마지막으로는 요즘 보편적으로 쓰이는 서빙 프레임워크(vLLM 등)를 깊이 들어가지는 않고 broad하게 훑어봤습니다.
결국 오늘 강조하고 싶었던 한 가지는, LLM이 등장하면서 모델 최적화에 대한 needs가 점점 더 커졌고, 이 needs를 PyTorch가 분명히 핵심에 자리하지만 PyTorch만으로는 다 해결할 수 없어, PyTorch를 보완하는 커널 프로그래밍과 고수준 서빙 프레임워크 두 가지가 함께 개발자들에 의해 만들어지고 있는 상황이라는 점입니다.
도입에서 본 그림으로 다시 돌아가면, 결국 LLM 추론 스택은 Open Pretrained LLM → Hugging Face 배포 → PyTorch → 커널 프로그래밍 + 서빙 최적화라는 구성으로 정리되고, 추론 특화 AI 반도체를 만드는 입장에서는 이 전체 스택을 빠짐없이 잘 받쳐주는 것이 결국 성능의 관건입니다.