Week 5: Distributed Programming in PyTorch
PyTorch + NPU 온라인 모임 #5 | 2025-01-15
소개
이번 강의에서는 PyTorch의 분산 프로그래밍(Distributed Programming)에 대해 다룹니다. Week 1에서 PyTorch 2.0의 핵심 특징 중 하나로 MPI-like distributed programming model을 언급한 바 있는데, 이번 주에 그 내용을 본격적으로 파고듭니다. 대규모 모델 학습이 일반화되면서 실무에서 분산 학습을 접할 일도 그만큼 많아졌습니다.
강의는 크게 네 부분으로 구성됩니다:
- Overview - MPI와 OpenMP의 차이, PyTorch 분산 프로그래밍의 기본 개념과 아키텍처
- torchrun을 활용한 distribute matmul 예제 - 실제 분산 행렬 곱셈을 수행하는 전체 과정
- Device와 연결: CUDA 예제 - CUDA Device 선택, 동기화, Process Group 관리의 내부 동작
- PyTorch가 제공하는 모델 병렬화 패키지들 - DDP, FSDP, TP 등 고수준 병렬화 도구
MPI vs. OpenMP
병렬 프로그래밍 모델 중 가장 대표적인 것은 MPI(Message Passing Interface)와 OpenMP(Open Multi-Processing) 두 가지입니다. 이 두 모델이 가장 크게 다른 점은, 가정하고 있는 밑에 있는 메모리 시스템이 다르다는 것입니다.
MPI
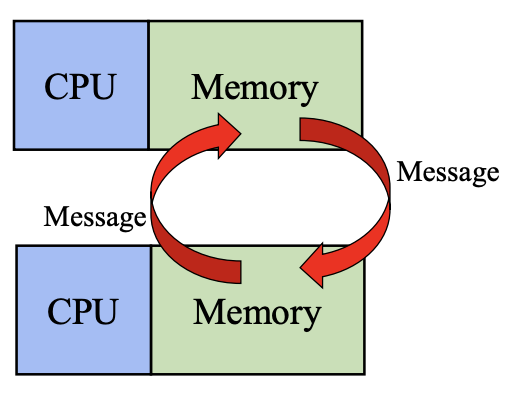
Distributed Memory
OpenMP
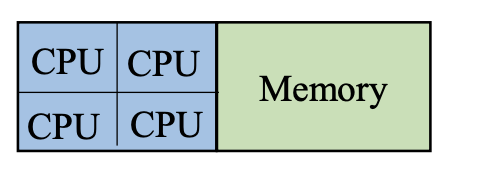
Shared Memory
OpenMP는 CPU들이 약간 tight하게 couple되어 있다고 생각하고, Shared Memory 모델을 가정합니다. 즉, 모든 프로세서들이 모든 메모리에 다 접근이 가능하다고 가정하는 것입니다. 반면 MPI는 Distributed Memory 모델 기반으로, 메모리들이 직접적으로 접근되지 않고 프로세서 간에 explicit하게 메시지를 주고받는 형태로 커뮤니케이션이 이루어진다고 가정합니다.
이렇게 MPI와 OpenMP가 구분되는데, PyTorch는 이 둘 중에서 MPI 스타일을 따르고 있다고 생각하시면 됩니다. GPU마다 독립적인 메모리를 가지고 있기 때문에, 분산 메모리 모델이 GPU 기반 학습 환경에 자연스럽게 맞아떨어지는 것입니다.
Task 구성 방식의 차이
MPI와 OpenMP는 밑에 있는 메모리 시스템에 대한 가정뿐만 아니라, 실제 Task들이 어떻게 구성되어 있는가에 있어서도 차이가 있습니다. 이 차이가 메모리 시스템에 대한 가정 차이에서 기인하는 것인지는 확실하지 않지만, 두 모델이 병렬 작업을 조직하는 방식 자체가 근본적으로 다릅니다.
MPI
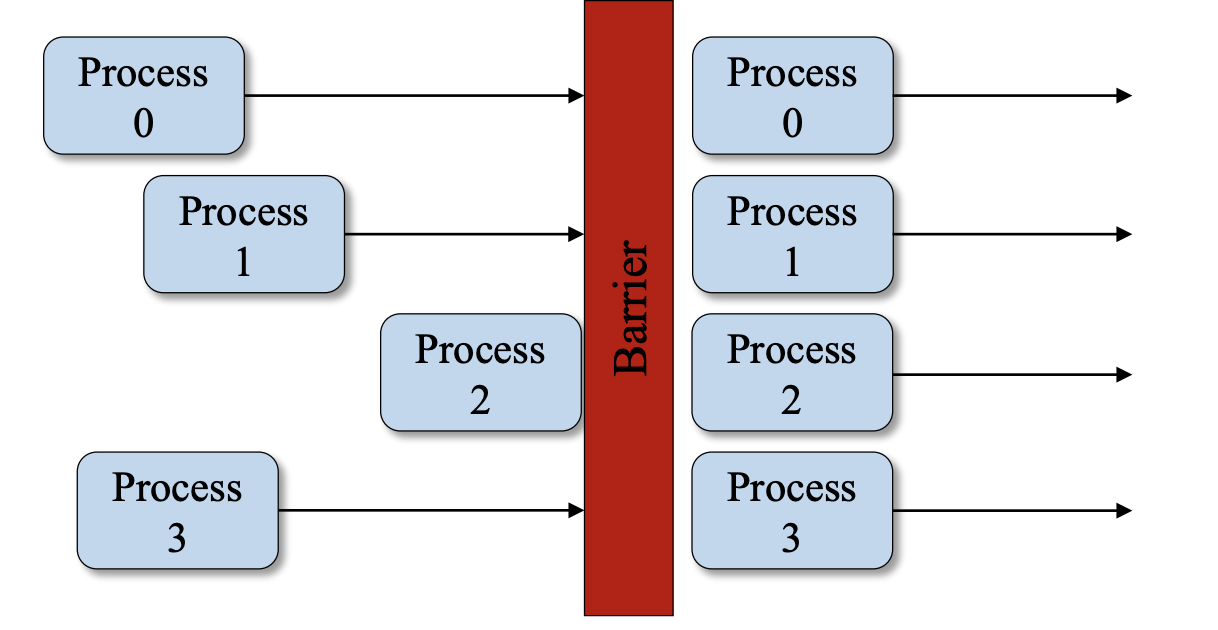
독립적인 프로세스들의 묶음
OpenMP
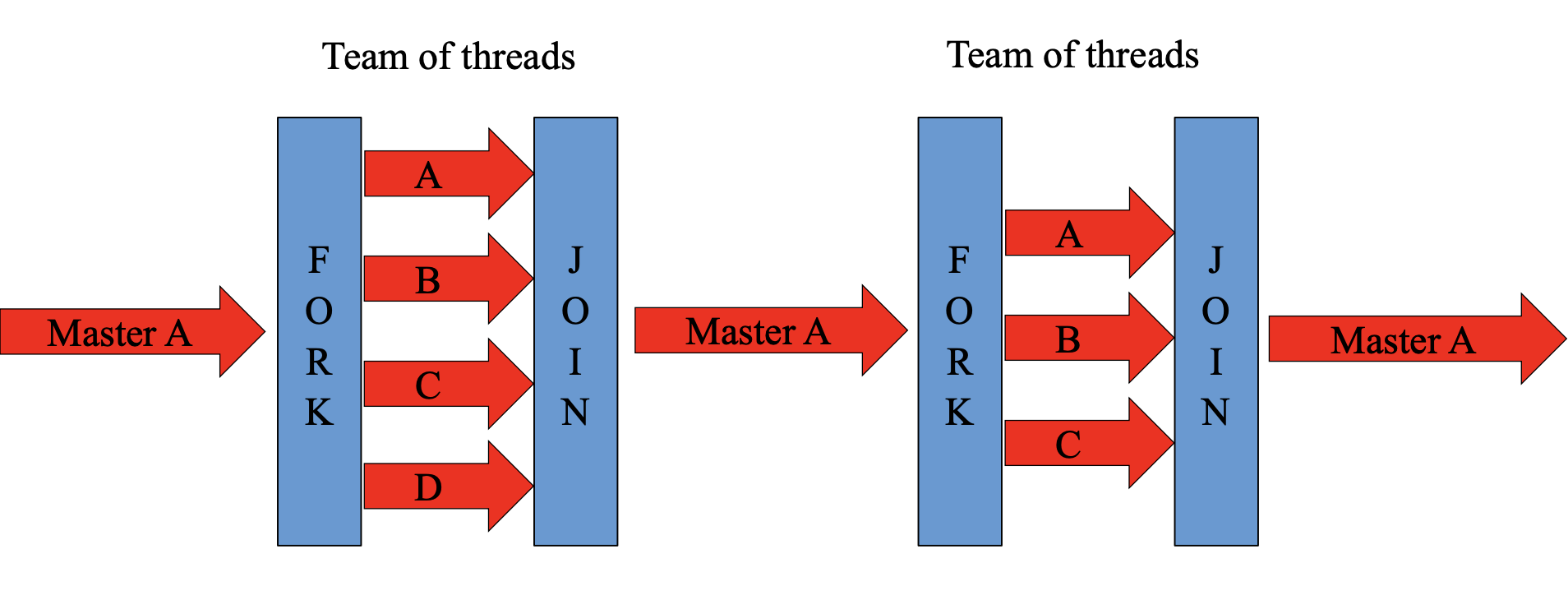
Master-Worker (Fork-Join) 모델
MPI는 정말 단독적으로 동작하는 프로세스들의 묶음이라고 생각하면 됩니다. 모든 프로세스들은 사실 다른 프로세스들과 상관없이 각자 시작하게 되고, 메시지 패싱을 하는 것 말고는 각자 자기가 할 일을 하면 됩니다. 예를 들어 reduction 같은 연산을 수행하기 위해 모든 프로세스가 끝날 때까지 기다려야 한다면 Barrier를 만들 수 있는데, 모든 프로세스가 이 Barrier를 만날 때까지 기다리고 있다가 다 모이면 다시 시작하는 방식으로 동작합니다. 이런 Barrier나 메시지 패싱에 의한 통신 외에는 프로세스 간에 별다른 관계가 없습니다.
OpenMP는 비슷하다고 할 수 있긴 하지만, 일단 Master에 해당하는 Task가 먼저 시작합니다. 그 Master로부터 병렬로 돌 수 있는 일들이 Fork되고, 끝나면 Join되어 다시 Master가 제어권을 가집니다. 이후 필요하면 다시 Fork하고 Join하는 식으로 병렬 태스크를 구성하도록 되어 있습니다.
PyTorch의 분산 학습에서 각 GPU 프로세스가 독립적으로 동일한 학습 스크립트를 실행하고, 필요한 시점에 gradient를 동기화하는 패턴은 MPI의 이러한 구조에서 비롯된 것입니다.
MPI 프로그램 구조
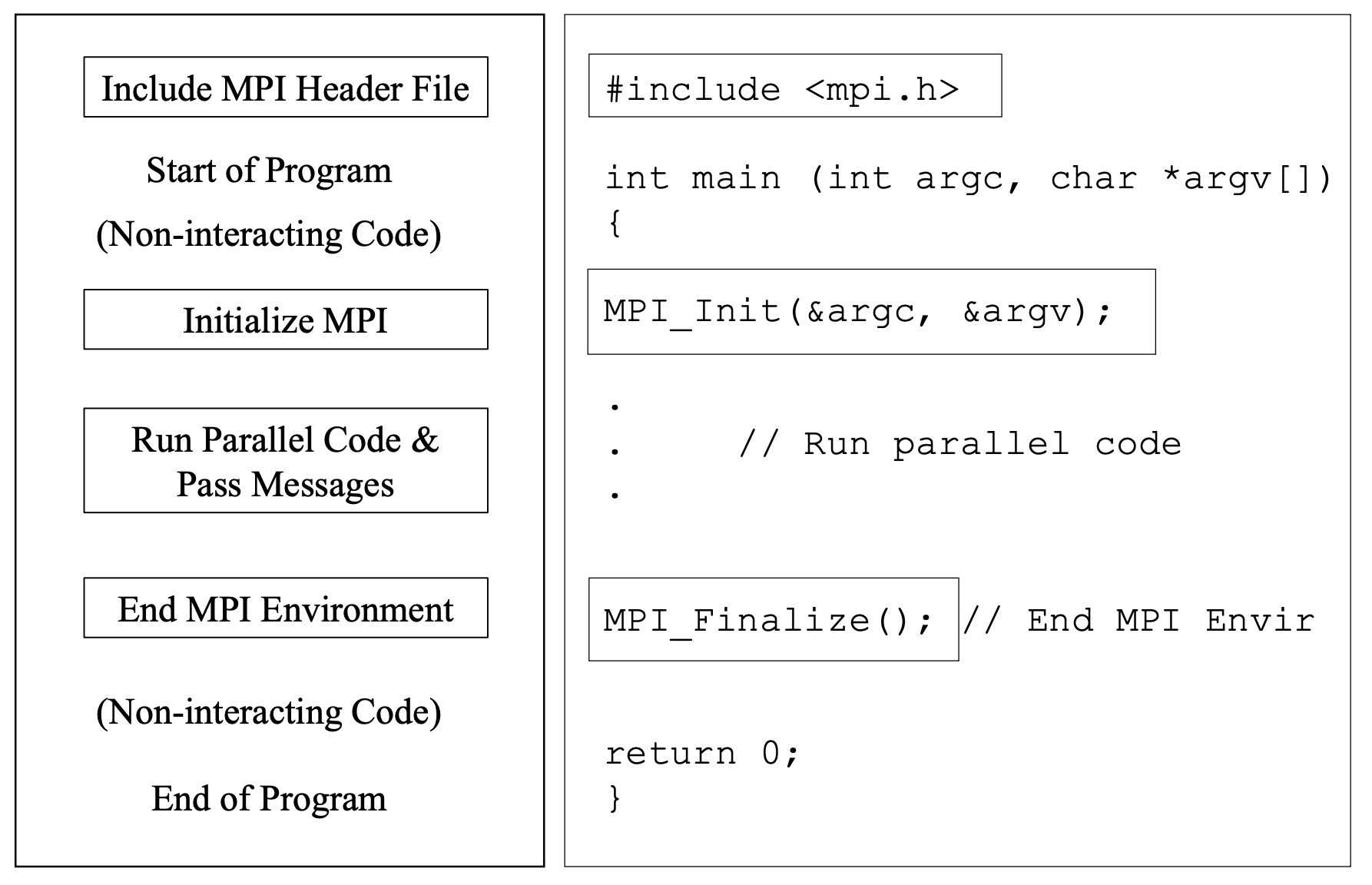
MPI 프로그램은 대체로 위와 같이 구성됩니다. MPI를 사용할 때 많은 경우 여러 프로세스에서 동일한 프로그램(single program)을 돌리는 방식이 일반적이며, 특히 PyTorch로 작성된 근사 모델의 경우 대부분 이런 방식을 따릅니다. 실제로는 동일한 코드가 각각의 다른 프로세스에서 실행된다고 생각하면 됩니다.
각 프로세스는 일단 initialization(초기화)를 수행한 후, 실제로 병렬로 job을 수행합니다. 이 job에는 해당 task/process가 처리해야 할 부분에 대한 기술이 포함되어 있습니다. Single program 방식이라면 같은 job을 실행하되 rank에 따라 다르게 동작하도록 코드를 작성하게 됩니다. 예를 들어 if 문을 활용해 자신의 rank에 따라 실제로는 다른 일을 하도록 분기할 수도 있습니다. 모든 작업이 끝나면 finalize 단계를 거쳐 전체적으로 종료합니다.
PyTorch도 거의 비슷한 구조를 따르고 있으며, 뒤에서 살펴볼 torchrun 예제에서 이를 직접 확인할 수 있습니다.
PyTorch Distributed Programming: 기본 개념
PyTorch 분산 프로그래밍 모델은 MPI의 프로세스 개념과 구조가 거의 같습니다. 핵심 용어들을 먼저 정리합니다.
Node는 물리적인 인스턴스로, GPU가 하나 또는 여러 개 장착되어 있으며, 하나의 Node 안에서 여러 개의 Process가 돌 수 있습니다. Process는 각 Node에서 생성되며, 일반적으로 1 process : 1 GPU 관계를 맺습니다. World는 이런 Node들과 Process들이 전부 모여서 이루는 전체 계산의 범위로, 해당 job에 참여하는 모든 process의 집합을 말합니다.
Rank는 프로세스의 고유 식별자인데, 두 가지 종류가 있습니다. Global rank는 World 전체에서의 순서이고, local rank는 하나의 Node 내에서 다른 프로세스들을 구분하는 순서입니다. 아래 다이어그램에서 보듯이, 2개의 Node에 각각 3개의 프로세스가 있다면 global rank는 0~5, local rank는 각 Node 내에서 0~2가 됩니다.
Rendezvous는 학습 job에 참여하는 node들을 한데 모으는(gathering participants) 과정으로, 어떤 머신들이 이 task에 참여하는지를 판별하고 구성하는 단계입니다. 프로그램이 시작되자마자 일단 Rendezvous를 만들어 이 job에 참여할 모든 머신들을 파악한 뒤, 그 위에서 job을 각 노드에 뿌려 실행하는 방식입니다. 동적으로 관리(dynamically manageable)할 수 있어 노드가 추가되거나 빠지는 상황에서도 유연하게 대응할 수 있는 메커니즘입니다.
Overall Architecture
PyTorch의 분산 프로그래밍 모델을 구성하는 주요 개념을 조금 더 자세히 살펴봅니다. 크게 Node와 Rendezvous 과정, 그리고 각 프로세스 내부에서 PyTorch가 동작하는 구조 두 관점으로 나누어 볼 수 있습니다.


1. Node와 Rendezvous 과정
Rendezvous는 여러 Node를 묶어서 하나의 분산 환경을 구성합니다. 각 Node 안에는 여러 개의 Process가 실행될 수 있고, 각 Process에는 Global rank(전체 환경에서의 프로세스 순서)와 Local rank(특정 Node 내에서의 프로세스 구분)가 부여됩니다. PyTorch는 실행 초기에 Rendezvous 과정에서 참여할 머신들을 확인하고 작업을 배분합니다.
2. 각 프로세스 내부의 PyTorch 분산 처리 구조
하나의 Process를 확대해서 보면 그 안에서 PyTorch가 돌고 있고, 아래에서 위로 다음과 같은 세 개의 레이어로 구성됩니다.
- Backend
- 가장 맨 아래단에서 실제 통신을 담당합니다.
- NCCL, MPI, Gloo 등 다른 라이브러리를 활용하여 CPU 또는 GPU 간의 프로세스 통신을 관장합니다.
- c10d (PyTorch Distributed Core Layer)
- PyTorch 분산 처리의 핵심(core) 레이어입니다.
- 실제 Backend들이 이 레이어에 붙으며,
all-reduce,broadcast같은 Collective API의 인터페이스도 여기에 정리되어 있습니다.
- High-level 패키지
- c10d 위에 올라가는 DDP, FSDP, TP, SP, PP 등의 모델 병렬화 패키지입니다.
- 사용자는 복잡한 분산 통신 로직을 직접 작성하지 않고도 이 패키지들을 활용해 여러 머신에서 PyTorch 모델을 병렬로 돌릴 수 있습니다.
Process Group
Process Group은 서로 통신하는 프로세스들의 집합입니다. 기본(default) process group으로 모든 프로세스를 하나로 묶을 수도 있고, 필요에 따라 여러 개의 subgroup으로 나눌 수도 있습니다. 예를 들어, 서로 다른 종류의 병렬화를 동시에 적용하려면 프로세스들을 여러 subgroup으로 나누어 각각 독립적으로 통신하도록 구성합니다.
Default process_group
process_group with 2 subgroups
Distributed Communication Layer (c10d)
c10d는 각 process 내부에서 PyTorch가 동작하는 구조의 가운데에 위치한 backbone으로, 분산 통신을 위한 distributed communication API가 정의된 핵심 계층입니다. 크게 두 가지 통신 방식을 제공합니다.
Collective communication은 group 내에 있는 모든 process들이 협력하여 data를 공유하고 처리하는 방식입니다. DDP의 gradient 동기화, FSDP의 parameter sharding 등 PyTorch 분산 패키지의 대부분이 이 방식을 사용합니다. P2P communication은 하나의 process에서 다른 process로 data를 직접 전송하는 방식으로, 개별 프로세스 간 직접적인 데이터 교환이 필요할 때 사용됩니다. Pipeline Parallel 같은 경우가 대표적이지만, high-level 패키지가 P2P를 실제로 얼마나 활용하는지는 명확하지 않습니다.
Collective Communication 연산들
c10d에는 보편적으로 쓰이는 collective communication API들이 폭넓게 정의되어 있습니다. 여기서는 그중 가장 자주 등장하는 연산들만 정리합니다.
참고: https://pytorch.org/tutorials/intermediate/dist_tuto.html
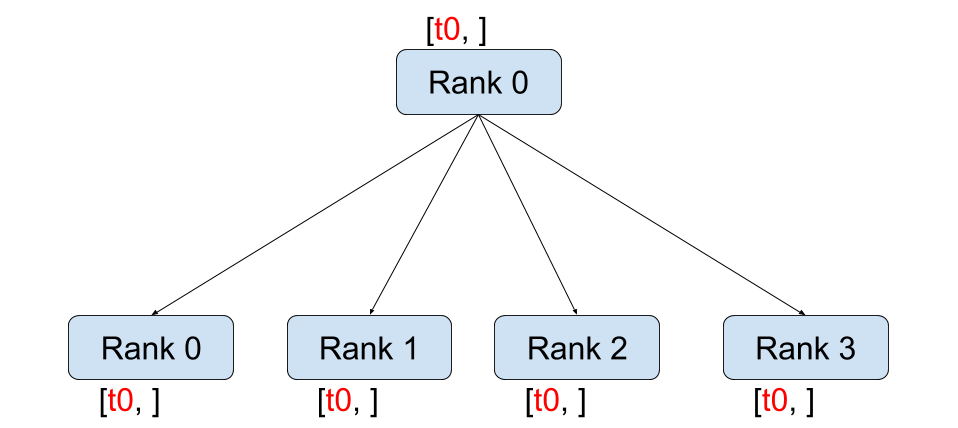
Scatter / Gather: 데이터를 쪼개서 나눠주고 다시 모으는 가장 기본적인 패턴
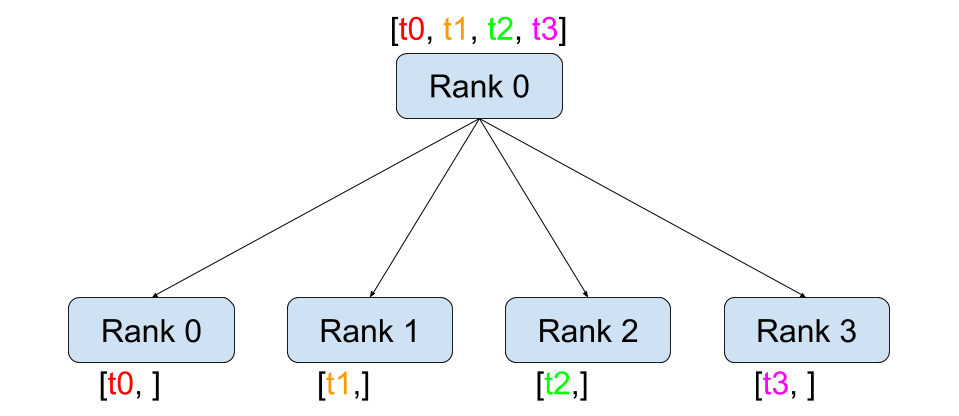
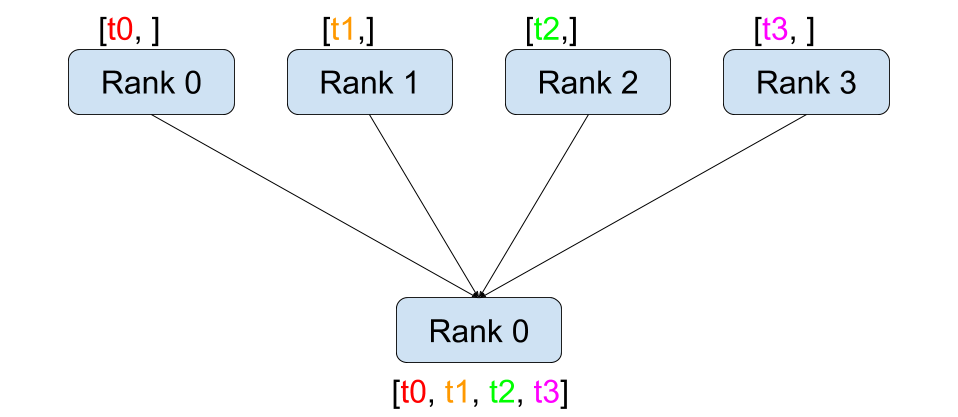
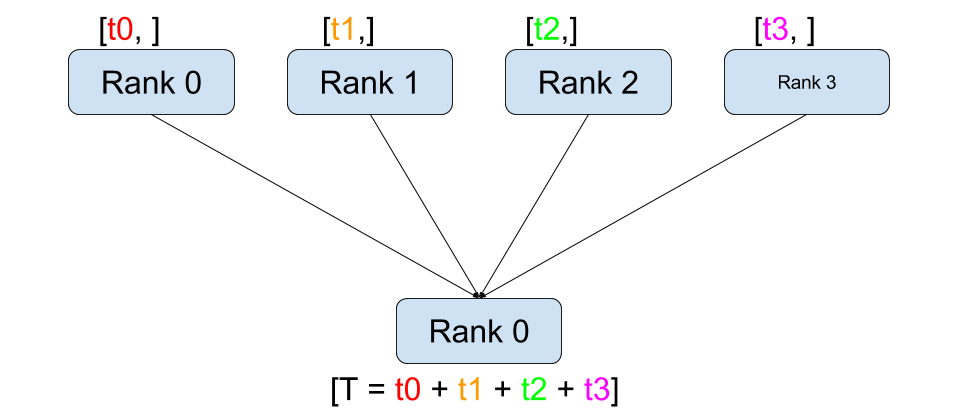
Reduce / All-Reduce: 여러 프로세스의 데이터를 하나로 합치는 연산. 분산 학습에서 gradient를 합산할 때 All-Reduce가 핵심적으로 사용됨
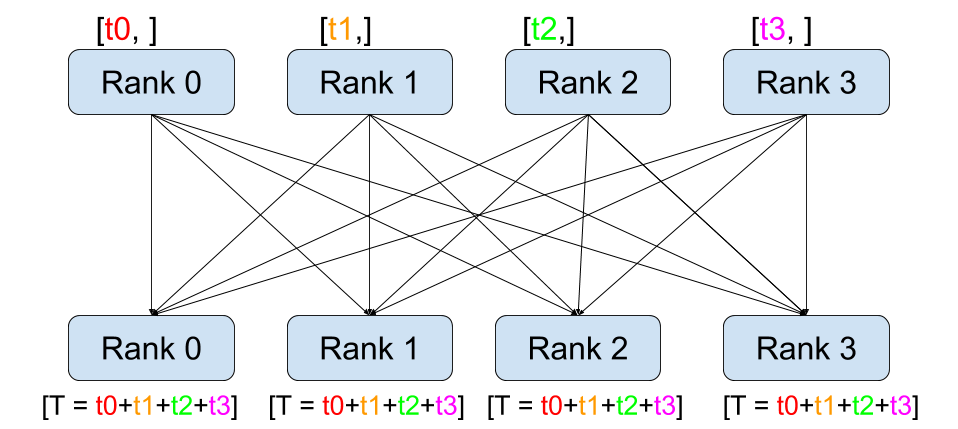
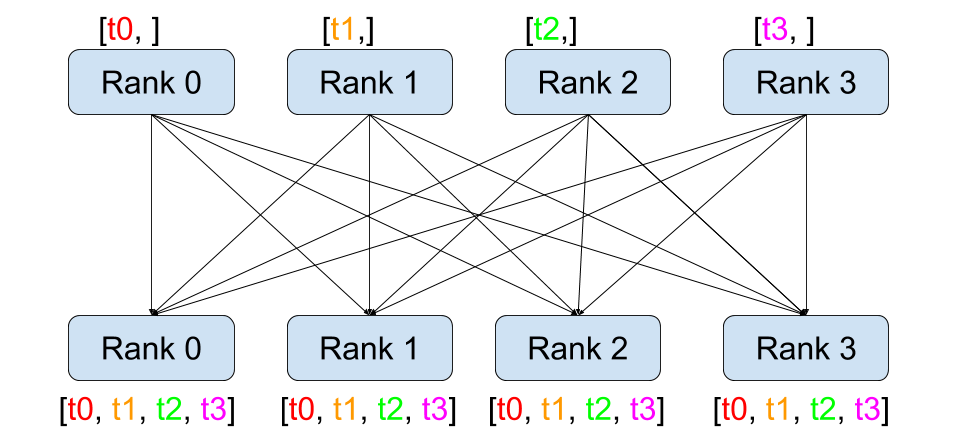
Broadcast / All-Gather: 한쪽의 데이터를 모든 프로세스로 퍼뜨리거나 모으는 연산
Communication Backends
c10d는 interface만 제공하고, 실제 통신 동작은 개별 하드웨어에 대한 communication backend에서 구현됩니다. PyTorch가 기본으로 제공하는 backend는 다음과 같습니다:
| Backend | 지원 Device | 비고 |
|---|---|---|
| Gloo | CPU / GPU | CPU 분산 학습에 주로 사용 |
| NCCL | GPU | NVIDIA GPU 전용, GPU 간 통신 최적화 |
| MPI | CPU / GPU (CUDA-aware MPI 빌드 시) | 일반적인 클러스터 분산 환경 |
이러한 구조 덕분에 third-party backend를 추가하는 것도 가능합니다. c10d/Backend.hpp를 구현하면 되는데, broadcast, allreduce, reduce, allgather 등 21개 virtual function으로 구성되어 있습니다. 리벨리온 NPU와 같은 새로운 하드웨어도 이 인터페이스를 구현함으로써 PyTorch의 분산 프로그래밍 생태계에 통합될 수 있습니다.
torchrun을 활용한 분산 행렬 곱셈 예제
개념 정리는 이 정도로 하고, 이제 실제로 분산 행렬 곱셈을 수행하는 예제로 전체 과정을 따라가 봅니다.
torchrun이란
torchrun은 PyTorch가 기본 제공하는 분산 프로그램 실행을 위한 top-level script입니다. 반드시 사용해야 하는 것은 아니며, c10d 등 안에 들어 있는 재료들을 직접 조합해서 비슷한 실행기를 만드는 것도 충분히 가능합니다. 다만 표준 진입점으로 쓰면 각 node에서 torchrun을 띄우는 것만으로 함께 물고 들어간 task들을 노드들이 모여 함께 수행하는 형태가 됩니다.
torchrun --nnodes=2 --nproc_per_node=8 \
--rdzv_id=job1 --rdzv_backend=c10d \
--rdzv_endpoint=node1:29500 \
dist_matmul_allreduce.py각 node에서 실행할 때 torchrun에 넘겨야 하는 핵심 파라미터들은 다음과 같습니다.
- 전체 world 구성 - 몇 개 node가 참여하고 node당 몇 개 process를 띄울지
- 현재 프로세스의 인덱스(task 번호) - 이 torchrun이 world 안에서 몇 번째 task에 해당하는지
- 사용할 backend - NCCL, Gloo 등 실제 통신 라이브러리
- Rendezvous endpoint - 어떤 머신을 랑데부 host로 쓸지
- 실행할 task - 각 process가 실제로 돌릴 PyTorch 스크립트
| 파라미터 | 설명 |
|---|---|
nnodes | 참여하는 node의 개수 |
nproc_per_node | node당 process의 개수 |
node_rank | node ID |
--rdzv-backend | rendezvous backend |
--rdzv-endpoint | rendezvous host:port |
test.py | 각 process가 실행할 pytorch 코드 |
torchrun이 위 파라미터로 모든 프로세스를 띄우면 각 프로세스는 initialization 단계를 거친 뒤, PyTorch가 그 프로세스에 할당된 모델 부분을 수행하기 시작합니다.
클러스터 준비
torchrun을 시작하기 전에 클러스터 설정이 필요합니다. 가장 단순한 방법은 SSH 기반 설정으로, /etc/hosts에 클러스터의 모든 노드의 IP와 hostname을 등록하고, 모든 노드들 사이에 암호 없이 로그인이 가능하도록 세팅하는 것입니다. 이 외에도 Ray cluster, Kubernetes, Slurm workload manager, Horovod 등 다양한 클러스터 관리 도구를 사용할 수 있습니다.
이 강의에서 사용할 예제 클러스터는 GPU가 8개씩 달려 있는 두 개의 노드입니다:
192.168.0.2(node_rank 0)192.168.0.3(node_rank 1)
torchrun 실행
각 노드에서 다음과 같이 실행합니다. 두 노드 모두 동일한 스크립트(dist_matmul_allreduce.py)를 실행하지만, node_rank만 다르게 지정합니다. 이것이 바로 앞서 설명한 MPI 스타일의 “동일한 프로그램을 여러 프로세스에서 실행”하는 패턴입니다.
@ node_rank: 0
$ torchrun --nnodes=2 --nproc_per_node=8 --node_rank=0 \
--rdzv_id=job1 --rdzv_backend=c10d \
--rdzv_endpoint="192.168.0.2:29500" \
dist_matmul_allreduce.py@ node_rank: 1
$ torchrun --nnodes=2 --nproc_per_node=8 --node_rank=1 \
--rdzv_id=job1 --rdzv_backend=c10d \
--rdzv_endpoint="192.168.0.2:29500" \
dist_matmul_allreduce.pytorchrun 수행 과정
torchrun을 실행하면 내부적으로 다음과 같은 단계를 거칩니다:
- torchrun 명령어 인자 parsing 및 초기화 - 위에서 지정한 파라미터들을 읽어들입니다.
- 프로세스 생성 - 각 노드에서
nproc_per_node만큼의 Python process를 생성합니다. 이 예제에서는 노드당 8개, 총 16개의 프로세스가 만들어집니다. - 랑데뷰 (rendezvous) - 모든 프로세스가 서로를 발견하고 동기화합니다. 각 프로세스에 global rank가 할당됩니다.
- Process별로 PyTorch 스크립트 실행 - 프로세스 그룹을 생성하면서 communication backend를 선택(nccl 혹은 gloo)하고, 데이터를 로딩 및 sharding한 뒤, 계산을 수행하고,
torch.distributed.all_reduce를 이용해 동기화한 후, 프로세스 그룹을 제거합니다. - 부가 기능 - fault tolerance를 위해 checkpointing과 logging을 지원합니다.
--max-restarts=N옵션으로 실패 시 N번까지 재시작을 시도할 수 있습니다.
랑데뷰 (Rendezvous) 상세
랑데뷰는 하나의 분산 계산에 참여할 머신들의 집합을 구성하고 그 정보를 서로 알리는 과정입니다. PyTorch 스크립트가 실제로 시작되기 전에 torchrun이 수행하는 준비 단계로, 각 프로세스가 자신의 task를 시작하기 전에 전체 분산 환경 측면에서 필요한 작업이 여기서 모두 세팅됩니다.
1. 랑데뷰의 역할
- 분산 학습에 참여할 머신들의 집합을 결정하고 그 정보를 공유
- 모든 프로세스가 참여 준비를 마칠 때까지 대기
- 각 프로세스에 고유한 rank를 할당하고 일관된 distributed environment를 세팅
2. 실행 과정
- c10d backend 초기화 - IPC에 사용할 c10d backend를 먼저 띄웁니다. PyTorch의
DynamicRendezvousHandlerclass가 사용되며,rdzv-endpoint로 지정된 노드에서 rendezvous backend가 host됩니다. - Rendezvous endpoint에 연결 - 각 프로세스가 endpoint로 접속합니다.
- 모든 프로세스의 join을 대기 - 참여하기로 한 프로세스가 전부 모일 때까지 block합니다.
- rank 할당 및 실행 준비 완료 - 각 프로세스에 고유 rank가 부여되고 distributed environment 세팅이 마무리됩니다.
이 과정이 끝나면 비로소 PyTorch script가 시작되고, 각 프로세스는 자신에게 할당된 학습 task를 수행합니다.
Fault tolerance 측면에서도 랑데뷰는 중요한 역할을 합니다. 한 노드가 실패하면 남아 있는 노드들로 랑데뷰를 다시 시도하여 학습을 이어갈 수 있습니다.
Task 수행 코드
랑데뷰가 끝나면 torchrun은 지정된 PyTorch 스크립트를 열어 본격적인 작업을 수행합니다. 여기서는 간단한 행렬 곱셈(matmul)을 분산으로 수행하는 예제를 통해 그 흐름을 따라가 봅니다. 먼저 top-level 진입 코드입니다.
if __name__ == "__main__":
n = 16000
rank = int(os.environ.get("RANK"))
if rank == 0:
A, B = torch.ones(n, n), torch.ones(n, n)
else:
A, B = torch.empty(n, n), torch.empty(n, n)
result = dist_matmul_allreduce(
A, B,
int(os.environ.get("LOCAL_RANK")),
int(os.environ.get("WORLD_SIZE")))
if rank == 0:
print(result)이 코드에서 MPI 스타일의 역할 분담이 그대로 드러납니다.
- Rank 0: 전체 initial data를 실제로 로드(
torch.ones)해서 다른 프로세스에 뿌릴 준비 - 그 외 rank: 같은 모양의 빈 텐서(
torch.empty)만 미리 만들어 두고 broadcast 받을 준비 - 공통 (모든 rank):
dist_matmul_allreduce를 호출해 실제 분산 연산 수행 - Rank 0: 모인 최종 결과를 출력
여기서 가장 중요한 일은 dist_matmul_allreduce 함수 안에서 일어납니다.
def dist_matmul_allreduce(
A, B, local_rank, world_size):
torch.cuda.set_device(local_rank)
dist.init_process_group(backend="nccl")
# NCCL은 CUDA tensor만 지원하므로 먼저 GPU로 이동
device = torch.device(f"cuda:{local_rank}")
A, B = A.to(device), B.to(device)
dist.broadcast(A, 0)
dist.broadcast(B, 0)
local_A, local_B = distributed_data(
A, B, local_rank, world_size)
local_result = local_matmul(
local_A, local_B)
dist.all_reduce(
local_result, op=dist.ReduceOp.SUM)
dist.destroy_process_group()
return local_result함수는 MPI 프로그램의 init → job → finalize 구조를 그대로 따릅니다.
- 초기 설정
torch.cuda.set_device(local_rank)- 한 노드에 여러 프로세스가 떠 있을 수 있으므로, local rank를 기반으로 이 프로세스가 사용할 디바이스를 명시적으로 지정합니다.dist.init_process_group(backend="nccl")- 어떤 backend(NCCL / Gloo / MPI 등)로 통신할지 결정합니다.
- 데이터 로딩 및 분산 - 먼저 tensor를 GPU로 옮기고(NCCL backend는 CUDA tensor만 지원),
dist.broadcast로 rank 0이 가진 A, B를 모든 프로세스에 전달한 뒤,distributed_data에서 각 rank가 담당할 부분만 잘라내 local A, local B를 준비합니다. (실제로는scatter로 각 rank에 필요한 조각만 보내면 메모리를 더 아낄 수 있지만, 여기서는 단순화를 위해 broadcast를 사용합니다.) - 분산 행렬 연산 -
local_matmul로 각 프로세스가 자신의 부분 곱을 계산하고,dist.all_reduce로 모든 rank의 결과를 합산해 최종 결과를 만듭니다. - 연산 종료 및 정리 -
dist.destroy_process_group()을 호출해 사용한 통신 자원을 반환하고, 결과를 리턴하면서 함수가 종료됩니다.
distributed_data와 local_matmul이 실제 일을 하는 부분입니다.
def distributed_data(A, B, lrank, world_size):
n = A.shape[0]
k = n // world_size
device = torch.device(f"cuda:{lrank}")
# split A and B
local_A = A[:, lrank*k:(lrank+1)*k].to(
device)
local_B = B[lrank*k:(lrank+1)*k, :].to(
device)
return local_A, local_B
def local_matmul(local_A, local_B):
return torch.matmul(local_A, local_B)distributed_data 함수는 broadcast로 받은 A, B에서 자신의 rank에 해당하는 부분만 골라 local A, local B로 준비합니다. 행렬 A는 열(column) 방향으로, 행렬 B는 행(row) 방향으로 분할하여 각각의 GPU에 올리며, 이렇게 분할된 부분 행렬끼리의 곱셈 결과를 all_reduce로 합산하면 전체 행렬 곱셈의 결과가 나옵니다.
Q. NCCL 같은 backend는 결국 CPU를 쓸지 GPU를 쓸지를 정하는 셋팅인가요? 그렇습니다.
nccl을 쓰면 GPU 연산을 한다는 뜻이고, 연결된 노드들도 NVIDIA 머신으로 구성된다고 보면 됩니다.Q. 한 랑데뷰 안의 노드들이 서로 다른 backend로 동작할 수 있나요? 확실하진 않지만 실험상으로는 모두 같은 backend여야 동작했고, 다르게 섞으면 에러가 났던 사례가 있습니다.
Device와 연결: CUDA 예제
dist_matmul_allreduce는 PyTorch가 실행된 이후에 호출되는 함수이고, 그 컨텍스트 안에서 device와 backend가 실제 연결됩니다. 큰 그림으로 보면 PyTorch의 분산 연산은 c10d 뒤에 붙어 있는 NCCL backend를 통해 CUDA와 직접 연결되며, 다음과 같은 지점들이 그 접점입니다.
- GPU 선택 -
torch.cuda.set_device(local_rank)로 어느 GPU를 쓸지 결정 - Backend 선택 -
dist.init_process_group(backend="nccl")로 어떤 통신 backend를 쓸지 결정 - Collective communication -
dist.broadcast,dist.all_reduce등이 NCCL backend를 거쳐 CUDA interface 위에서 수행 - 종료 처리 - 모든 작업이 끝난 뒤 process group을 정리하는 과정도 CUDA와 맞물려 동작
즉, NCCL을 backend로 쓰면 GPU 간 통신이 최적화되고, 대부분의 collective 연산은 CUDA interface와 직접 연결되어 병렬로 실행됩니다. 아래에서는 dist_matmul_allreduce의 CUDA 접점 네 군데를 하나씩 살펴봅니다.
def dist_matmul_allreduce(A, B, local_rank, world_size):
# 1. CUDA Device 선택
torch.cuda.set_device(local_rank)
# 3. Process Group 생성 및 통신 채널 설정
dist.init_process_group(backend="nccl")
dist.broadcast(A, 0)
dist.broadcast(B, 0)
local_A, local_B = distributed_data(A, B, local_rank, world_size)
local_result = local_matmul(local_A, local_B)
# 2. 동기화 (CUDA Runtime)
dist.all_reduce(local_result, op=dist.ReduceOp.SUM)
# 4. Process Group 제거
dist.destroy_process_group()
return local_result1: CUDA Device 선택
torch.cuda.set_device()로 각 프로세스가 사용할 GPU를 명시적으로 선택합니다. 여기서 Rendezvous가 지정해 준 LOCAL_RANK 환경변수를 사용하는데, 이는 하나의 node 내에서만 unique한 rank입니다 (전체 World에서 unique한 것은 RANK 환경변수). 이렇게 해서 node 내에서 process : device == 1 : 1 관계를 만듭니다.
이 호출은 torch.distributed.init_process_group()보다 먼저 수행되어야 합니다. 명시적으로 device를 지정하지 않으면 모든 프로세스가 0번 device를 사용하게 되어 GPU 자원이 낭비됩니다. 한 가지 알아둘 점은, torch.cuda.set_device()를 호출하는 것만으로는 CUDA 초기화가 발생하지 않는다는 것입니다. PyTorch는 lazy 초기화 방식을 사용하여, 실제로 Tensor를 최초로 GPU에 만들 때 비로소 CUDA 초기화가 일어납니다.
아래 표는 2개 노드, 노드당 8개 GPU 환경에서 RANK와 LOCAL_RANK의 관계를 보여줍니다:
| 0 | 1 | … | 7 | 8 | 9 | … | 15 | ||
|---|---|---|---|---|---|---|---|---|---|
| RANK | 0 | 1 | … | 7 | 8 | 9 | … | 15 | |
| LOCAL_RANK | 0 | 1 | … | 7 | 0 | 1 | … | 7 |
2: 동기화 (CUDA Runtime)
torch.distributed.all_reduce()가 호출되면 내부적으로 두 단계를 거칩니다. 먼저 PyTorch의 ProcessGroup C++ binding으로 전달되어 초기화된 ProcessGroup을 확인하고, NCCL backend를 사용하는지 확인합니다. 그 다음 ProcessGroupNCCL에서 NCCLComm 객체를 사용하여 NCCL 통신을 준비하고, NCCL library의 ncclAllReduce() 함수를 호출합니다.
all_reduce는 기본적으로 blocking 연산이지만, async_op=True를 지정하면 non-blocking으로 실행할 수 있어 통신과 계산을 겹칠 수 있습니다:
# non-blocking all_reduce() 예시
work = dist.all_reduce(
local_result,
op=dist.ReduceOp.SUM,
async_op=True
)
do_something() # 통신이 진행되는 동안 다른 작업 수행
work.wait() # 통신 완료를 기다림실제 PyTorch 내부 구현을 보면 이 동작이 명확히 드러납니다:
# torch/distributed/distributed_c10d.py
def all_reduce(tensor, op=ReduceOp.SUM,
group=None, async_op=False):
...
work = group.allreduce([tensor], opts)
if async_op:
return work
else:
work.wait()3: Process Group 생성 및 통신 채널 설정
torch.distributed.init_process_group()은 프로세스들 간의 통신 채널을 생성하는 함수입니다. NCCL(GPU), GLOO(GPU/CPU), MPI(CPU, CUDA-aware 빌드 시 GPU) 등의 backend를 지정할 수 있으며, 초기화 방법(init_method), timeout, world size, rank 등의 metadata도 여기서 설정합니다.
초기화 방법은 두 가지가 있습니다. TCP 주소를 직접 명시하는 방법과 공유 filesystem을 사용하는 방법입니다:
# 주소를 직접 명시한 초기화
dist.init_process_group(
backend="nccl",
init_method='tcp://127.0.0.1:23456',
world_size=world_size,
rank=rank
)# 공유 filesystem을 통한 초기화
dist.init_process_group(
backend="nccl",
init_method='file:///mnt/nfs/sharedfile',
world_size=world_size,
rank=rank
)내부적으로는 torch.distributed가 Rendezvous를 통해 server/client 정보를 수집합니다. MASTER_ADDR, MASTER_PORT, WORLD_SIZE, RANK 등의 환경변수를 참고해 정보를 수집하고, 이를 바탕으로 TCPStore를 생성함으로써 UNIX process 간 통신 환경을 준비합니다. 이때 rank == 0인 프로세스만 daemon을 생성하고, 나머지 프로세스들은 이 daemon에 connect하는 구조입니다.
# torch/distributed/rendezvous.py
if "rank" in query_dict:
rank = int(query_dict["rank"])
else:
rank = int(_get_env_or_raise("RANK"))
if "world_size" in query_dict:
world_size = int(query_dict["world_size"])
else:
world_size = int(_get_env_or_raise("WORLD_SIZE"))
master_addr = _get_env_or_raise("MASTER_ADDR")
master_port = int(_get_env_or_raise("MASTER_PORT"))
use_libuv = _get_use_libuv_from_query_dict(query_dict)
store = _create_c10d_store(
master_addr, master_port, rank, world_size, timeout, use_libuv
)4: Process Group 제거
torch.distributed.destroy_process_group()은 통신 자원을 해제하고 memory 등의 resource를 정리하는 함수입니다. 중요한 점은, group에 참여했던 모든 process들이 이를 호출해야 비로소 종료될 수 있다는 것입니다. Collective operation처럼 동작하므로, 일부 프로세스만 호출하면 나머지 프로세스들이 영원히 기다리게 됩니다.
NCCL backend의 경우, 내부적으로 NCCLComm 객체가 소멸되면서 ncclCommDestroy()를 호출하여 GPU 간 통신에 사용된 resource를 정리합니다.
PyTorch가 제공하는 모델 병렬화 패키지들
TODO: FSDP2로 업데이트 필요
여기까지가 c10d 레벨의 저수준 분산 통신입니다. 실제 모델 학습에서는 이런 저수준 API를 직접 사용하기보다, PyTorch가 제공하는 고수준 병렬화 패키지를 사용하는 경우가 대부분입니다. 각 패키지는 서로 다른 병렬화 전략을 구현하고 있습니다.
Distributed Data Parallel(DDP)은 모델을 잘게 나누는 게 아니라 동일한 모델을 여러 GPU에 복제해 두고 데이터를 GPU별로 분배하는 Data Parallel 방식입니다. 각 GPU가 서로 다른 데이터 배치를 처리해서 throughput을 끌어올리고, 매 step마다 gradient를 all_reduce로 모아 평균한 뒤 모든 GPU의 모델 파라미터를 동일하게 업데이트합니다.
Fully Sharded Data Parallel(FSDP)은 모델이 너무 커서 한 머신에 통째로 올릴 수 없을 때 사용합니다. parameter(weight, bias)를 world_size로 나누어 각 GPU에 sharding해 두고, 어떤 op을 실행하기 직전에 그 op에 필요한 weight 조각을 다른 GPU들로부터 모아 완전한 weight를 구성한 뒤 계산합니다. 계산이 끝나면 받아 온 조각들은 다시 버리고, 다음 op에서 필요한 다른 조각을 또 모으는 식입니다. FSDP는 parameter뿐 아니라 gradient와 optimizer state까지 sharding하여 메모리를 절약하며, 계산 자체는 각 GPU가 자신의 데이터 배치에 대해 온전히 수행합니다.
Tensor Parallel(TP)은 한 layer의 연산조차 한 머신에서 처리하지 못할 만큼 클 때 사용하는, FSDP보다 더 복잡한 병렬화입니다. weight뿐 아니라 연산 자체를 여러 GPU로 쪼개서 row parallel 또는 column parallel 방식으로 분할 계획(plan)을 따라 처리한 뒤, 결과를 다시 합쳐 최종 output을 만듭니다.
이 외에도 Sequence Parallel(SP)과 Pipeline Parallel(PP)이 있으며, 실제 대규모 모델 학습에서는 이러한 기법들을 조합하여 사용합니다.
컴파일러처럼 보이지만 컴파일러는 아닙니다. FSDP나 TP는 모델을 재구성하는 방식이라는 점에서 어떻게 보면 컴파일러가 하는 일과 비슷합니다. 다만 실제 컴파일 과정 같은 건 구현되어 있지 않고, 입력도 출력도
nn.Module입니다. Python의 동적 클래스 생성 능력을 활용해 FSDP/TP가 해야 할 일을 함수로 정의하고 그것을 새로운 클래스로 wrap한 뒤 리턴하는 방식으로 “컴파일된 듯한 효과”만 만들어 냅니다.
Q. GPU 여러 대로 분산해서 학습하면 결과값이 어떻게 한 곳으로 정확히 모이나요? 이 부분이
torch.distributed의 핵심 기능입니다. 랑데뷰 단계에서 world 구성과 각 프로세스 정보를 모두 파악해 두고, 노드들의 접근 정보는 TCPStore(원격 접근 가능한 key-value store)에 캐싱합니다. 이를 바탕으로 collective communication API가 sharding된 weight 조각을 누구에게 받을지, 결과를 어떻게 모을지를 처리합니다. Tensor Parallel은 마지막에 reduction으로 결과를 합치고, FSDP는 forward 결과(activation)를 각 GPU가 자신의 데이터에 대해 로컬로 계산하므로 output을 모으는 단계는 없지만, backward에서는reduce_scatter로 gradient를 rank 간에 동기화합니다.Q. 랑데뷰 역할을 하는 머신이 따로 있나요? 랑데뷰 host는
--rdzv_endpoint로 사용자가 지정한 노드가 맡습니다 (앞의 예제에서는192.168.0.2). 별도의 전용 머신일 필요는 없고, 연산 노드 중 하나가 겸하는 것이 일반적입니다. 랑데뷰는 프로세스들이 서로를 찾고 world를 구성하기 위한 과정일 뿐이므로, 특정 물리 머신에 본질적으로 묶여 있는 것은 아닙니다.
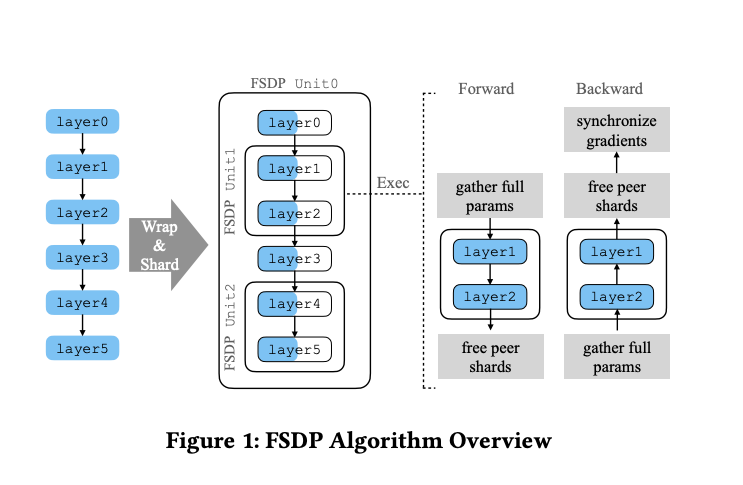
FSDP 예제 코드
FSDP는 사용법 자체는 간단합니다. 일반적인 PyTorch 모델을 정의한 뒤, FSDP()로 감싸기만 하면 됩니다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
return F.log_softmax(x, dim=1)모델 자체는 일반적인 CNN과 동일합니다. FSDP를 적용하려면 다음 두 줄이면 충분합니다:
def fsdp_main(rank, world_size, args):
setup(rank, world_size)
……
model = Net().to(rank)
model = FSDP(model)
……
(PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel)
https://pytorch.org/tutorials/intermediate/FSDP_tutorial.html
FSDP 내부 동작
FSDP의 내부 동작은 initialization, forward, backward 세 단계로 나눌 수 있습니다.
Initialization 단계에서는 먼저 FlatParameter를 설정합니다. 이 과정에서 개별 process의 sharding 정보를 결정하고, sharded memory를 할당하며, 불필요한 unsharded memory를 해제합니다. 그리고 forward/backward 실행 시 자동으로 호출될 hook들을 등록합니다. pre hook에서는 all_gather(unsharding)를, post hook에서는 resharding(모아 온 전체 parameter를 해제)을 수행하도록 설정합니다.
Forward 단계에서는 각 layer마다 all_gather로 sharded parameter를 복원(unsharding)하고, computation을 수행한 뒤, 다시 resharding하는 과정을 반복합니다. 한 layer의 계산이 끝나면 해당 layer의 전체 parameter를 다시 버려서 메모리를 절약합니다.
Backward 단계에서는 forward와 유사하게 각 layer에서 all_gather → computation → resharding 과정을 거치지만, 추가로 gradient를 동기화하기 위한 reduce_scatter 연산이 수행됩니다. 이 hook은 _register_post_backward_hook을 통해 등록됩니다.
Tensor Parallel 예제 코드
Tensor Parallel은 FSDP와 달리 계산 자체를 쪼개기 때문에 자동화가 어려워, 개발자가 모델의 어떤 layer를 어떻게 자를지 분할 계획(plan)을 직접 설계해야 합니다. 어떤 parameter를 column 방향으로, 어떤 것을 row 방향으로 쪼갤지를 명시적으로 지정한 뒤 plan을 함께 넘기면, PyTorch 패키지가 그 plan대로 모델까지 같이 잘라줍니다. 이 추상화는 Megatron-LM 등에서 제안된 분할 기법을 손쉽게 적용할 수 있게 한 것이라고 볼 수 있습니다.
from torch.distributed.device_mesh \
import init_device_mesh
from torch.distributed.tensor.parallel \
import ColwiseParallel, \
RowwiseParallel, \
parallelize_module
tp_mesh = init_device_mesh("cuda", (8,))
layer_tp_plan = {
"feed_forward.w1": ColwiseParallel(),
"feed_forward.w2": RowwiseParallel(),
"feed_forward.w3": ColwiseParallel(),
}
for transformer_block in model.layers:
parallelize_module(
module=transformer_block,
device_mesh=tp_mesh,
parallelize_plan=layer_tp_plan,
)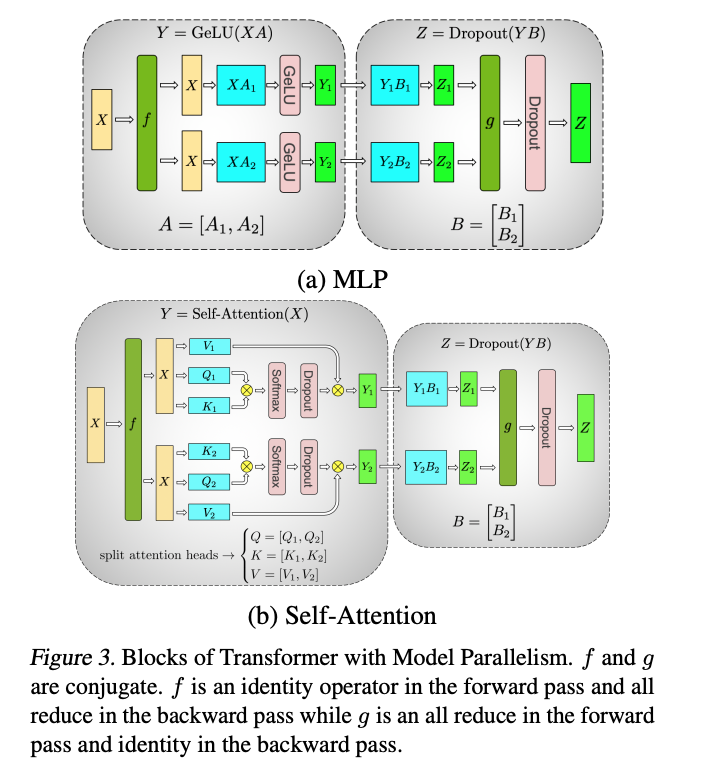
(Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism)
위 코드에서 볼 수 있듯이, feed_forward의 w1은 column 방향으로, w2는 row 방향으로 분할하는 식의 계획을 세웁니다. 이러한 분할 전략은 Megatron-LM 등의 연구에서 제안된 기법을 활용하여 추상화한 것으로, PyTorch의 parallelize_module API를 통해 비교적 간결하게 적용할 수 있습니다.
분산 프로그래밍 정리 Q&A
지금까지 살펴본 분산 패키지들과 관련해 강의 중 나온 질문들을 정리합니다.
Q. DP / TP / PP를 함께 쓸 때 적용 순서가 중요한가요? 순서라기보다는 레이어 개념으로 보면 됩니다. DP는 모델을 자르지 않으므로 가장 위쪽 레이어에서 적용한다고 생각하면 자연스럽고, TP·PP가 먼저 모델을 잘라 분산된 모델 인스턴스를 만들면 그 위에서 DP가 그것을 데이터 병렬로 복제하는 그림입니다. TP와 PP는 자르는 dimension 자체가 다르기 때문에 어느 쪽을 먼저 적용해도 크게 다르지 않을 가능성이 높지만, 보통 두 가지를 모두 쓸 만큼 모델이 크지 않다면 둘 중 하나만으로도 충분합니다.
Q. 노드 = GPU 인가요? Rank가 GPU에 부여되는 subjob인가요? 노드는 GPU가 아니라 서버(호스트 머신)입니다. 한 노드에 GPU가 여러 개 꽂혀 있을 수 있고, 보통 NVIDIA GPU 환경에서는 GPU 1개 = process 1개 = rank 1개로 매핑합니다. 따라서 GPU가 4개인 노드라면 rank 4개·프로세스 4개가 생기고, 각 rank는 특정 GPU에 할당된 하나의 분산 작업이라고 보면 됩니다.
Q. 데이터 dimension이 큰 모델에선 디바이스 간 데이터 전송 overhead가 더 중요한 이슈 아닌가요? 맞습니다. TP나 PP처럼 op 자체를 병렬화하면 분산 이득과 함께 통신 overhead도 같이 늘어나서, 오히려 느려지는 경우도 생깁니다. 그래서 FSDP vs TP 같은 trade-off를 봐야 합니다. 한 디바이스에서 계산이 도저히 안 들어갈 정도로 layer 자체가 크다면 TP를 쓸 가치가 있고, 그렇지 않다면 계산을 한 머신에서 온전히 끝내는 FSDP가 통신 비용 면에서 더 유리한 경우가 많습니다.
Q. FSDP는 어차피 연산 직전에 unsharding을 하는데 왜 sharding을 하나요? GPU 메모리 한계 때문입니다. 예를 들어 GPU HBM이 10GB인데 모델 weight가 40GB라면 한 GPU에 다 못 올립니다. 호스트가 weight 전체를 들고 있다가 필요한 조각을 GPU로 넘겨주는 방식도 가능하지만, GPU↔GPU 통신이 host↔GPU보다 빠른 환경에서는 GPU들에 weight를 분산시켜 놓고 필요할 때 GPU 간에 직접 모으는 편이 훨씬 빠릅니다. FSDP의 unsharding은 이 더 빠른 경로를 활용해 weight를 op 직전에 모으는 방식입니다.
Q. Gloo, NCCL, MPI는 노드 안 통신만 다루나요, 노드 간 통신도 다루나요? 둘 다 다룹니다. Collective communication API를 호출하는 입장에서는 통신해야 한다는 사실만 알 뿐 상대 프로세스가 같은 노드인지 다른 노드인지는 모릅니다. 그 판별은 backend가 내부에서 처리하며, 같은 노드 안이면 NVLink/SHM 같은 빠른 경로를, 다른 노드면 네트워크 프로토콜을 사용해 통신을 수행합니다.
Q.
torch.compile과torch.distributed는 어떤 순서로 적용되나요? 통합되지 않아 놓치는 최적화가 있나요?torch.distributed가 먼저 적용된 후torch.compile이 수행됩니다. 즉 torchrun으로 분산 환경을 세팅하고 모델을 분산 형태로 변환한 뒤에야 그 분산 모델을 컴파일합니다. 컴파일러 입장에서 collective communication op은 처리해야 할 op 중 하나일 뿐인데, graph break를 일으키지 않으면 FX graph 안으로 들어가 backend 컴파일러로 함께 넘어가고, graph break를 일으키면 그 op만 eager로 떨어지고 graph가 그 지점에서 끊깁니다. 두 시스템을 하나로 묶었다면 더 끌어낼 수 있는 최적화가 분명히 있겠지만, 문제 자체가 너무 커서 현실적으로는 따로 푸는 편이 자연스럽습니다.
Q. 대용량 분산 처리는 보통 Hadoop/MapReduce를 쓰는데, PyTorch는 왜 MPI 형태를 골랐나요? Hadoop/MapReduce도 본질적으로는 shared memory를 가정하지 않는 분산 모델이라 MPI와 크게 다르지 않습니다. 다만 MapReduce는 storage 위 데이터 처리에 가깝고 collective의 종류가 제한적인 반면, MPI는 다양한 collective를 표준적으로 정의해 둬서 분산 학습에서 필요한 통신 패턴을 표현하기에 더 자연스러운 모델입니다.
Next Week Preview: Beyond PyTorch
지금까지 5주에 걸쳐 PyTorch 안에 기본으로 들어 있는 주요 기능들을 살펴봤습니다. 다음 주에는 PyTorch만으로 해결되지 않는 영역을 한 시간 정도 다룹니다.
Custom kernel: 두 가지 경우에 필요합니다.
- 기존 op으로 cover되지 않는 새로운 op이 필요한 경우
- op 인터페이스는 그대로 두되 PyTorch가 제공하는 op의 성능이 부족해 자체 구현으로 갈아끼우고 싶은 경우
NVIDIA GPU 환경을 가정한다면 CUDA(또는 cuBLAS, cuTLASS) 같은 NVIDIA 제공 도구로 작성할 수 있고, Triton처럼 custom kernel 작성에 특화된 언어를 활용하는 방법도 다룹니다.
vLLM: PyTorch보다 한 단계 위 레벨에 있는 LLM inference / serving 프레임워크로, 현재 사실상 표준에 가까운 위치를 차지하고 있습니다. vLLM의 전체 구조, vLLM이 제공하는 최적화 기능, 그리고 그런 최적화를 PyTorch 기본 op만으로는 표현할 수 없기 때문에 vLLM이 정의해 둔 custom op 셋이 어떤 모양인지를 함께 살펴볼 예정입니다.
Q&A
Q. NVCC 같은 컴파일러는 distributed를 고려해서 설계됐나요? 아닙니다. NVCC는 단일 GPU에서 실행되는 커널 하나를 컴파일하는 도구이고, PyTorch 입장에서 그 커널은 그저 op 하나입니다. 분산 처리는 NVCC가 아니라 c10d 레이어가 담당합니다. collective communication op들이 데이터 분배·수집을 책임지고, 그 op이 GPU에서 실행될 때 또 다른 커널로 내려가는 구조라고 보면 됩니다. 즉 컴파일과 분산은 분리된 레이어입니다.
Q. AMD나 리벨리온 같은 NPU/GPU 컴파일러도 distributed를 고려하지 않을까요? 리벨리온 컴파일러는 sharding 기능을 갖고 있습니다. 다만 이 sharding을 다른 노드로 넘어가는 계산까지 활용할지에 대해서는 아직 그렇게 가지는 않을 가능성이 높습니다. AMD가 어떻게 처리하고 있는지는 확인이 필요합니다.
Q. Hadoop/MapReduce와 MPI는 어떻게 다른가요? Hadoop은 디스크에 있는 데이터를 긁어와 처리하는 디스크 기반 분산이고, MPI는 메모리에 데이터가 이미 로딩된 상황에서 동작합니다. 그런 의미에서 Hadoop도 shared memory를 가정하지는 않으므로 OpenMP보다는 MPI 쪽에 가깝고, MapReduce의 reduce 단계는 MPI의
allreduce와 모델적으로 크게 다르지 않습니다.
Q. Transformer가 사실상 표준이 됐는데 custom kernel 수요는 계속 있나요? 네. 특히 Attention은 context length가 길어질수록 가장 비싸지는 부분이고, 이를 가속하는 기법만도 계속 새로 나오고 있습니다. DRAM access를 줄이는 최적화도 있고, NVIDIA가 새 GPU에 공격적으로 추가하는 hardware feature를 활용하려면 같은 기능의 커널도 GPU 세대마다 다시 작성해야 합니다. Flash Attention v1 → v2 → v3가 GPU 발전에 맞춰 진화한 것이 대표 사례입니다.