Week 4: Automatic Differentiation in PyTorch
PyTorch + NPU 온라인 모임 #4 | 2025-01-08
Agenda
- Background - Supervised Learning, Backprop
- Automatic Differentiation - PyTorch에서의 구현: Autograd (1.0), AOTAutograd (2.0)
Background: Supervised Learning
머신러닝에서 지도학습(Supervised Learning)은 주어진 데이터로부터 최적의 함수를 찾아가는 과정입니다. 가장 간단한 예로 라는 모델이 있을 때, 훈련 데이터 쌍이 주어지면, 기울기()를 조금 조정하고 bias()를 조금 이동시키면서 데이터를 가장 잘 표현하는 weight 값을 찾아갑니다. 이처럼 training data가 주어졌을 때 loss를 최소화하는 weight 값으로 조금씩 변해가는 과정이 바로 학습(training)입니다.
Forward & Backward


네트워크의 가중치(예: )는 랜덤하게 초기화되거나 학습 중간 체크포인트에서 시작됩니다. 현재 가중치를 기준으로, 훈련 데이터에 대한 성능을 평가하고 개선하는 과정이 학습의 핵심입니다.
- Forward Propagation (순전파): 입력 데이터를 네트워크에 통과시켜 각 층의 가중치를 사용한 연산을 거쳐 출력값을 계산합니다.
- Loss 계산: 기대 출력(ground truth)과 네트워크 예측값의 차이를 loss function을 통해 계산합니다.
- Backward Propagation (역전파): 손실을 줄이기 위해 loss에서 출발하여 입력층까지 역방향으로 gradient를 계산합니다. 중간층의 모든 가중치에 대한 보정값을 구하는 이 과정을 backpropagation이라 하며, 이것이 자동화된 것이 Automatic Differentiation입니다.
- Optimizer: 계산된 gradient를 기반으로 optimizer가 가중치를 조정합니다. 이때 모델 아키텍처 자체는 변하지 않고, 가중치만 업데이트됩니다.
이 과정을 반복하면 손실이 점차 줄어들며, 목표 성능에 수렴하면 학습이 종료됩니다. 이것이 Supervised Learning(지도 학습)의 일반적인 흐름입니다.
(Reverse-Mode) Automatic Differentiation
Reverse-mode automatic differentiation은 역전파(backpropagation)를 구현하는 알고리즘으로, 다음 세 가지로 구성됩니다:
- Computation graph의 구성
- Computation graph 각 노드에서의 gradient function 도출
- Gradient를 전파하기 위한 graph의 backward walking
이 과정의 수학적 기반은 Chain Rule입니다.
(i) 일 때:
(ii) 이고 일 때 (parametric form):
예제: Autodiff 계산
다음 함수를 예로 들어보겠습니다:
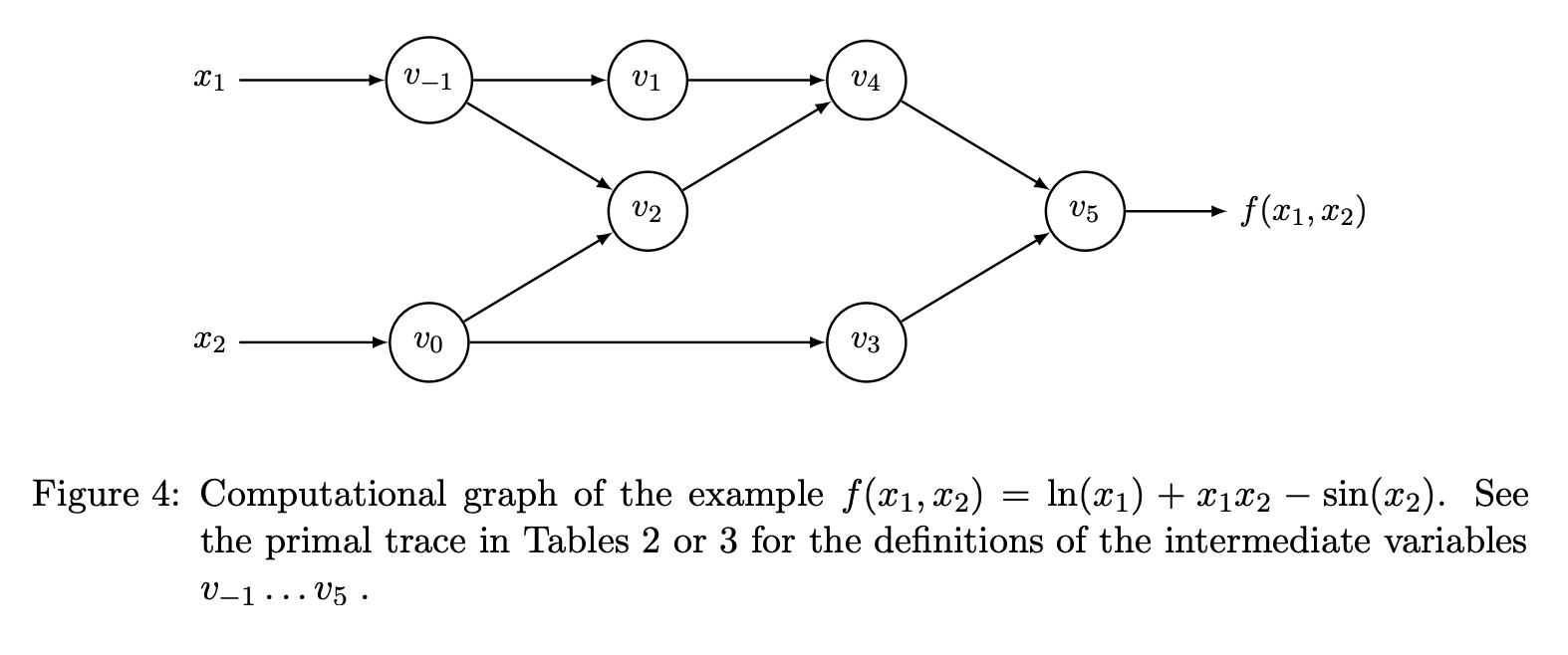

이 함수의 computation graph를 구성하면, 각 중간 연산 노드에서의 gradient를 chain rule을 통해 역방향으로 전파할 수 있습니다. 자세한 내용은 Baydin et al. (2018)을 참고하세요.
예제: Forward & Backward 계산
PyTorch 1.0: Autograd
PyTorch에서 reverse-mode automatic differentiation을 구현한 것이 바로 Autograd입니다. “Autograd”라는 이름은 하버드 대학에서 NumPy 기반의 automatic differentiation을 연구하던 팀이 먼저 사용했으며, 해당 팀의 핵심 멤버들은 이후 Google에 입사하여 JAX 팀에 합류했습니다. PyTorch도 같은 이름을 사용하면서 초기에 이름 충돌에 대한 논의가 있었습니다.
PyTorch의 Autograd는 텐서 연산의 미분 계산을 자동화하여, 개발자가 복잡한 계산 그래프를 수동으로 정의하지 않고도 backpropagation을 수행할 수 있게 합니다. 핵심 특징은 다음 세 가지입니다:
1. Eager Mode를 위한 Autograd
PyTorch는 Eager Mode를 기본으로 동작하며, 각 연산이 실행될 때마다 computation graph를 incremental하게 구축합니다 (반대 개념인 graph mode에서는 먼저 그래프를 모두 생성한 뒤 연산을 진행합니다).
이를 위해 PyTorch는 Dispatcher와 operator overloading을 활용합니다:
- Dispatcher는 연산 요청이 들어오면 해당 연산을 어떤 방식으로 처리할지 결정하고, 적합한 구현(Autograd dispatch key 등)을 호출합니다.
- Operator overloading을 통해 Python의 기본 연산자(예:
+,*,@)를 PyTorch 텐서 객체에서 사용할 때, Autograd와 함께 처리되도록 수정된 함수가 실행됩니다.
이를 통해 직관적이고 명령형 프로그래밍 스타일로 모델을 만들 수 있습니다.
2. Tensor별 Gradient 선택
각 텐서별로 gradient 계산 여부를 선택할 수 있습니다. 딥러닝 모델에서 모든 텐서에 대해 gradient가 필요한 것은 아닙니다. 예를 들어 입력 데이터(input)는 값이 변하지 않으므로 backprop이 필요 없지만, 학습 대상인 weight는 backprop이 필요합니다.
텐서에는 requires_grad라는 flag가 있어서, 이 flag가 켜져 있는 텐서들만 computation graph에 연산 기록을 남기게 됩니다. Backpropagation을 실행하기 전에 gradient가 필요한 텐서를 transitive하게 선별하여 연산 비용을 줄이고 불필요한 리소스 낭비를 방지합니다. 이 기능은 학습 중 특정 텐서를 freeze하거나 모델의 일부만 미세 조정(fine-tuning)할 때 유용합니다.
3. Custom Differentiable Function
PyTorch는 기본 제공되는 연산자(log, sin, polynomial 등) 외에도, 개발자가 직접 custom differentiable function을 정의할 수 있는 유연성을 제공합니다. 잘 알려진 수학 함수의 미분 형태는 PyTorch 내부에 이미 구현되어 있지만, 사용자가 custom op을 만든 경우 Autograd는 그 미분 방법을 알 수 없습니다. 이때 custom op을 추가한 개발자가 미분 규칙을 함께 기술하여 등록할 수 있도록 장치가 마련되어 있습니다.
Autograd 동작 예제
머신러닝 모델이라고 보기는 어렵지만, Autograd의 동작 원리를 단계별로 이해하기에 충분한 단순 수학 연산 예제입니다.
- 변수: 는 상수이지만 gradient가 필요하도록 마킹, ,
- 목표: 에 대한 의 gradient 를 구하기
x = torch.tensor(2.0)
x.requires_grad = True
y = x * 2
z = y ** 2
z.backward()
print(x) # tensor(2., requires_grad=True)
print(y) # tensor(4., grad_fn=<MulBackward0>)
print(z) # tensor(16., grad_fn=<PowBackward0>)
print(x.grad) # tensor(16.)각 값을 확인하면: 이고 requires_grad flag가 True, , 입니다. 실제로 뒤에서부터 미분을 수행하면 이 됩니다. 이 원리를 기반으로 신경망에서는 수많은 연산의 미분을 체계적으로 계산하여 학습이 진행됩니다.
Step 1: Tensor 생성
x = torch.tensor(2.0)
x.requires_grad = True로 초기화하고 requires_grad = True로 gradient 필요 여부를 마킹합니다. 이 시점의 computation graph에는 x:2 노드만 존재합니다.
Step 2: Forward 연산 (y = x * 2)
y = x * 2먼저 forward 계산으로 가 저장됩니다. 여기서 끝나는 것이 아니라, 가 미분이 필요하다고 마킹되어 있으므로 그 output인 도 gradient가 필요하게 됩니다. 이때 MulBackward0라는 grad function이 에 연결되어, multiplication에 의한 backward 과정이 필요하다는 것이 등록됩니다. Computation graph 상태는 다음과 같습니다:
[참고] Forward에서 수행되는 AutoGrad kernel 예제: add
PyTorch v1.13.1 기준으로 torch/csrc/autograd/generated/VariableType_2.cpp에는 다음과 같은 add_Tensor forward 커널이 생성되어 있습니다. (디버그 전용 #ifndef NDEBUG 블록의 storage alias 검증 코드는 핵심 흐름 이해에 지장이 없어 생략했습니다.)
// torch/csrc/autograd/generated/VariableType_2.cpp
at::Tensor add_Tensor(c10::DispatchKeySet ks, const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha) {
auto& self_ = unpack(self, "self", 0);
auto& other_ = unpack(other, "other", 1);
auto _any_requires_grad = compute_requires_grad( self, other );
(void)_any_requires_grad;
std::shared_ptr<AddBackward0> grad_fn;
if (_any_requires_grad) {
grad_fn = std::shared_ptr<AddBackward0>(new AddBackward0(), deleteNode);
grad_fn->set_next_edges(collect_next_edges( self, other ));
grad_fn->other_scalar_type = other.scalar_type();
grad_fn->alpha = alpha;
grad_fn->self_scalar_type = self.scalar_type();
}
auto _tmp = ([&]() {
at::AutoDispatchBelowADInplaceOrView guard;
return at::redispatch::add(ks & c10::after_autograd_keyset, self_, other_, alpha);
})();
auto result = std::move(_tmp);
if (grad_fn) {
set_history(flatten_tensor_args( result ), grad_fn);
}
return result;
}이 코드는 사람이 직접 작성한 것이 아니라, Autograd 라이브러리가 자동으로 생성(codegen)한 커널입니다. Eager mode에서의 dispatch 개념을 떠올리면, PyTorch에는 dispatch key가 있어서 텐서의 상태에 따라 어떤 함수를 dispatch할지 결정합니다. Forward용 커널과 backward용 커널이 각각 존재하고, 하드웨어(CPU, GPU 등)에 따라 다른 함수를 dispatch할 수 있도록 설계되어 있습니다.
requires_grad가 켜진 텐서가 관여하는 연산에서는 Autograd dispatch key를 사용하여 dispatch가 이루어집니다. 이 커널은 backward에서 호출되는 함수가 아니라, forward에서 add를 처리하는 함수입니다. Forward를 수행하면서 나중에 backward가 될 때 어떻게 처리할지를 미리 기록해 두는 것입니다:
compute_requires_grad로 현재 계산이 나중에 gradient를 구해야 하는 계산인지 판별합니다.- 필요하다면 해당 연산의
grad_fn(예:AddBackward0)을 찾아 등록합니다.add라는 함수가 정해져 있으므로 PyTorch는 대응하는grad_fn이 무엇인지 알고 있습니다. next_edges를 통해 backward graph를 구성합니다. 마치 computation graph를 만드는 것처럼 역전파 경로를 기록해 둡니다.- 이 모든 기록이 끝난 후에 실제 forward 계산을 수행합니다.
또한 특정 텐서에 requires_grad=True가 설정되어 있으면, 그 텐서로부터 영향을 받는 모든 output 텐서들도 자동으로 requires_grad=True가 됩니다. PyTorch가 forward 과정에서 이를 추적하며 자동으로 설정합니다.
[참고] Grad Functions
Grad function들(예: AddBackward0)도 결국 PyTorch Op입니다. 이 미분 함수들은 derivatives.yaml에 정의된 Op들의 미분 규칙으로부터 자동으로 코드 생성(codegen)됩니다. PyTorch에는 Op을 정의하는 YAML 파일이 여러 개 있으며, 그 중 derivatives.yaml에 기본 Op들에 대한 미분 규칙이 정리되어 있고, PyTorch가 이를 읽어서 backward 함수들을 자동으로 생성합니다.
1단계: derivatives.yaml의 미분 규칙 선언
예를 들어 add, mul, pow 연산은 tools/autograd/derivatives.yaml에 아래처럼 입력별 미분식이 선언되어 있습니다. (PyTorch 1.13.1 기준)
- name: add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor
self: handle_r_to_c(self.scalar_type(), grad)
other: handle_r_to_c(other.scalar_type(), maybe_multiply(grad, alpha.conj()))
result: self_t + maybe_multiply(other_t, alpha)
- name: mul.Tensor(Tensor self, Tensor other) -> Tensor
self: mul_tensor_backward(grad, other, self.scalar_type())
other: mul_tensor_backward(grad, self, other.scalar_type())
result: other_t * self_p + self_t * other_p
- name: pow.Tensor_Scalar(Tensor self, Scalar exponent) -> Tensor
self: pow_backward(grad, self, exponent)
result: auto_element_wise각 입력(self, other, …)마다 “이 입력에 대한 gradient는 어떻게 계산하는가”를 수식으로 적어 두는 구조입니다.
2단계: Codegen이 만들어주는 backward 클래스
빌드 시 tools/autograd/gen_autograd_functions.py가 위 YAML을 읽어서 torch/csrc/autograd/generated/Functions.h와 Functions.cpp를 생성합니다. AddBackward0의 경우 다음과 같은 코드가 만들어집니다:
// Functions.h
struct TORCH_API AddBackward0 : public TraceableFunction {
using TraceableFunction::TraceableFunction;
variable_list apply(variable_list&& grads) override;
std::string name() const override { return "AddBackward0"; }
void release_variables() override {
}
at::ScalarType other_scalar_type;
at::Scalar alpha;
at::ScalarType self_scalar_type;
};// Functions.cpp
variable_list AddBackward0::apply(variable_list&& grads) {
IndexRangeGenerator gen;
auto self_ix = gen.range(1);
auto other_ix = gen.range(1);
variable_list grad_inputs(gen.size());
const auto& grad = grads[0];
bool any_grad_defined = any_variable_defined(grads);
if (task_should_compute_output({ other_ix })) {
auto grad_result = any_grad_defined ? (handle_r_to_c(other_scalar_type, maybe_multiply(grad, alpha.conj()))) : Tensor();
copy_range(grad_inputs, other_ix, grad_result);
}
if (task_should_compute_output({ self_ix })) {
auto grad_result = any_grad_defined ? (handle_r_to_c(self_scalar_type, grad)) : Tensor();
copy_range(grad_inputs, self_ix, grad_result);
}
return grad_inputs;
}YAML의 self: / other: 표현식이 그대로 apply() 내부의 handle_r_to_c(...) / maybe_multiply(grad, alpha.conj())로 옮겨진 것을 볼 수 있습니다. 클래스 멤버(alpha, self_scalar_type, other_scalar_type)에는 forward 시점에 필요한 값을 저장해 두고, backward에서 그 값을 사용하도록 되어 있습니다.
같은 방식으로 MulBackward0, PowBackward0도 생성됩니다. 예를 들어 앞의 계산 그래프 예제에서 사용된 MulBackward0::apply는 다음과 같습니다:
variable_list MulBackward0::apply(variable_list&& grads) {
std::lock_guard<std::mutex> lock(mutex_);
IndexRangeGenerator gen;
auto self_ix = gen.range(1);
auto other_ix = gen.range(1);
variable_list grad_inputs(gen.size());
const auto& grad = grads[0];
auto self = self_.unpack();
auto other = other_.unpack();
bool any_grad_defined = any_variable_defined(grads);
if (task_should_compute_output({ other_ix })) {
auto grad_result = any_grad_defined ? (mul_tensor_backward(grad, self, other_scalar_type)) : Tensor();
copy_range(grad_inputs, other_ix, grad_result);
}
if (task_should_compute_output({ self_ix })) {
auto grad_result = any_grad_defined ? (mul_tensor_backward(grad, other, self_scalar_type)) : Tensor();
copy_range(grad_inputs, self_ix, grad_result);
}
return grad_inputs;
}self_.unpack(), other_.unpack()에서 볼 수 있듯 곱셈은 backward에서 원래 입력값이 필요하므로 SavedVariable 멤버로 저장해 두었다가 꺼내 쓰는 구조입니다. (add는 입력값이 필요 없으니 저장하지 않았던 것과 대비됩니다.) 결과적으로 derivatives.yaml 한 줄이 곧 하나의 backward 클래스로 변환되며, 개발자는 미분식만 선언하면 실제 grad_fn 클래스와 dispatch 코드는 codegen이 만들어주는 구조입니다.
Step 3: Forward 연산 (z = y ** 2)
z = y ** 2Step 2와 동일한 과정이 반복됩니다. 이 계산되면서, Autograd는 와 도 gradient가 필요하다는 것을 인지합니다. 앞서 설명한 compute_requires_grad의 if문 안으로 들어가 PowBackward0 grad function을 bookkeeping해 둡니다. PowBackward0에 들어가는 입력은 이며, 미분식 를 반환합니다. 이 스텝까지 완료되면 forward 계산이 모두 끝나고 backward graph 준비가 완료된 상태입니다:
Step 4: Backward
z.backward()Step 4.1 - Backward 시작: Forward에서 기록해 둔 과정을 거꾸로 복귀합니다. 출력 자신에 대한 편미분은 항상 1이므로, 상수 부터 시작합니다. 이 값이 PowBackward0로 전달되면, 의 미분 함수인 가 적용됩니다. 이때 는 위에서 들어오는 입력과는 상관없이 값에만 의존하며, 이므로 이 됩니다.
Step 4.2 - Gradient 전파: 다음 단계에서 에 대한 의 편미분 는 입니다. 위에서 온 민감도(gradient)가 계속 누적되면서 곱해지는 과정이므로, 이전 단계에서 내려온 민감도 에 편미분 를 곱하면 이 됩니다. 이 이 최종적으로 x.grad에 저장됩니다.
따라서 입니다. 실제 신경망에서는 이보다 훨씬 복잡하지만, 근본적으로 이 과정이 반복적으로 일어난다고 생각하면 됩니다.
전체 backward 흐름을 정리하면 다음과 같습니다:
검증: 이므로,
[참고] backward(): Python → C++
Python에서 backward()를 호출하면 C++ 레벨의 run_backward()로 연결되고, 이것이 Autograd Engine의 Engine::execute()를 호출합니다. execute()는 내부적으로 graph_task를 생성하고, 그래프에 등록된 함수들을 확인하며 역전파 계산에 필요한 함수들을 준비(init_to_execute())합니다. 이후 evaluate_function()에서 실제 backward 연산이 수행되고 최종적으로 gradient가 계산됩니다.
backward()
└→ run_backward()
└→ Engine::execute()
└→ graph_task->init_to_execute()
execute_with_graph_task()
└→ Engine::evaluate_function()
└→ call_function() ← 실제 grad function이 불리는 곳Python 레벨에서는 wrapper만 존재하고, 실제 구현은 대부분 C++로 작성되어 있습니다. GPU 환경에서는 CUDA 코드가 실행되지만, 전체 실행 흐름을 관리하는 큰 틀은 C++ 코드입니다. 각 단계에서 grad_fn을 찾아 실행하며, dispatch key를 통해 CPU 커널 또는 CUDA 커널을 선택합니다.
Eager mode에서는 매번 backward() 호출 시 이 준비 과정이 반복 수행되지만, gradient 함수를 찾아 등록하는 과정에 불과하므로 큰 오버헤드를 유발하지는 않습니다. 반면 graph mode에서는 gradient 계산을 포함한 전체 그래프를 미리 생성하여 최적화된 방식으로 실행합니다.
PyTorch 1.0에서 eager mode 기반 Autograd가 핵심 기능으로 도입된 이후, 기본적인 큰 틀은 현재 최신 PyTorch에서도 변하지 않고 유지되고 있습니다. 내부 구현이 조금씩 업데이트되었을 가능성은 있지만, 전반적인 메커니즘은 크게 달라지지 않았습니다.
PyTorch 2.0: AOTAutograd
PyTorch 1.0과 2.0의 가장 큰 차이는 실행 모델(execution model) 자체에 있습니다. PyTorch 1.0은 Eager Mode를 기본으로, 연산을 즉시 실행하면서 Autograd가 backward graph를 동시에 구축합니다. PyTorch 2.0은 torch.compile()을 통한 Graph Mode를 도입하여, 연산을 먼저 FX Graph로 캡처한 뒤 backend compiler(예: Inductor)로 최적화된 코드를 생성합니다. 이러한 실행 모델 변화는 automatic differentiation에도 재설계를 요구했고, 그 결과가 AOTAutograd입니다.
| 항목 | PyTorch 1.0 (Eager) | PyTorch 2.0 (Graph) |
|---|---|---|
| 실행 방식 | 연산 즉시 실행 | FX Graph 캡처 후 실행 |
| Forward 추적 | 실제 tensor | Fake tensor로 emulation |
| Backward graph 생성 | Forward 중 incremental 생성 | Forward FX Graph 완성 후 AOT 생성 |
| 미분 엔진 | Autograd | AOTAutograd |
| 최적화 단위 | 단일 op | Forward + backward joint graph |
Graph mode에서는 fake tensor를 이용하여 forward를 빠르게 에뮬레이션(trace)하면서 계산이 어떻게 이루어질지 전체적인 스케치를 먼저 합니다. 이 스케치가 FX Graph로 캡처되고, FX Graph를 backend compiler에 전달하면 컴파일 후 실제 계산이 이루어집니다. 그렇다면 이러한 graph mode에서는 backward graph를 어떻게 생성해야 할까요? 두 가지 접근을 생각해 볼 수 있습니다:
-
Dynamo trace 중에 Autograd를 실행하여 backward graph 생성: Fake tensor를 이용한 tracing 과정에서 기존 eager mode의 Autograd를 함께 돌리는 방법입니다. 그러나 Autograd는 실제 tensor 값을 기반으로 동작하도록 설계되었기 때문에, fake tensor를 사용하는 tracing 과정에서 그대로 동작할지 확신하기 어렵습니다. 또한 Dynamo trace는 전체 계산을 하나의 trace로 만드는 것이 아니라, eager mode와 graph mode가 번갈아가면서 실행되므로 backward graph 생성이 복잡해질 수 있습니다.
-
FX Graph를 먼저 만든 후 backward graph를 생성: FX Graph로 변환되고 나면 복잡한 부분들은 정리된 상태이므로, 이 시점에서 backward graph를 만드는 것이 더 깔끔합니다. FX Graph로 묶인 부분을 eager mode 관점에서 하나의 거대한 합성 연산(composite Op)으로 보면, 그 Op에 대한 미분 함수만 알고 있으면 eager mode에서 자연스럽게 backward가 수행될 수 있습니다.
이 두 번째 아이디어를 바탕으로 AOTAutograd(Ahead-of-Time Autograd)가 개발되었습니다.
What Happens When Training with torch.compile()?
먼저 왼쪽의 Python 코드를 예로 들어보겠습니다. model이 어떤 input을 받아 output을 만들고, 이 output을 기대하는 reference와 비교하여 cross entropy로 loss를 계산한 후, loss.backward()를 호출하는 전형적인 학습 루프입니다. 이 코드를 eager mode로 실행할 때와 graph mode(torch.compile() 적용)로 실행할 때 내부에서 어떤 일이 일어나는지 비교해보겠습니다.
| 단계 | Eager Mode | Graph Mode (torch.compile()) |
|---|---|---|
| 사용자 코드 | | |
| 모델 준비 | 별도 준비 없음. model을 그대로 사용 | torch.compile(model)로 compiled 모델 생성. 이 시점의 “compile”은 backend compile이 아니라, Dynamo 등이 tracing할 수 있도록 준비된 모델을 만드는 것 |
| Forward 실행 | model(input) 호출 시 각 연산이 즉시 실행됨. requires_grad=True가 켜진 텐서에 대해 Autograd가 연산 시점마다 incremental하게 backward graph를 등록 | compiled_model(input) 호출 시 Dynamo가 tracing을 수행하며 가속 가능한 부분을 FX Graph로 캡처. 그 후 캡처된 그래프를 실행하여 output 계산 |
| Backward graph 구성 | Forward를 진행하는 동안 각 Op의 grad_fn이 출력 텐서에 붙으며 backward graph가 점진적으로 만들어짐 | FX Graph가 완성된 시점에 AOTAutograd가 개입하여 forward/backward joint graph를 ahead-of-time으로 생성 |
| Loss 계산 | F.cross_entropy(outputs, labels) - Autograd가 loss의 grad_fn을 이어 붙임 | 동일하게 수행. Compiled forward의 grad_fn이 loss의 backward chain에 연결됨 |
| Backward 실행 | loss.backward() 호출 시 Autograd engine이 미리 등록된 backward graph를 따라가며 gradient를 계산. 호출할 때마다 준비 과정이 반복됨 | loss.backward() 호출 시 compiled backward가 하나의 큰 Op으로서 실행됨. Backend compiler로 이미 최적화된 코드가 수행됨 |
| 사용자 코드 차이 | 기존 방식 그대로 | torch.compile(model) 한 줄 추가 정도 |
겉에서 볼 때는 두 코드의 차이가 거의 없습니다. 오른쪽 코드만 봐서는 위 표의 복잡한 과정들이 일어난다는 것이 obvious하지 않지만, torch.compile()이 모델을 컴파일해 두었기 때문에 그냥 model을 쓰는 대신 compiled_model을 쓰는 것만으로 내부에서 알아서 최적화된 방식으로 forward와 backward가 처리됩니다. 그 “알아서 잘 되도록 하기 위해서 일어나는 과정”이 바로 AOTAutograd입니다.
아래는 torch.compile()을 적용한 학습 코드의 각 라인에서 실제로 어떤 일이 일어나는지를 번호로 표시한 것입니다. 왼쪽은 사용자가 작성하는 코드, 오른쪽은 AOTAutograd에 의해 생성되어 torch.autograd.Function으로 감싸진 compiled forward/backward의 예시입니다.
사용자 코드
compiled_model = torch.compile(model)
# [1]
outputs = compiled_model(images)
# [2]
loss = F.cross_entropy(outputs, labels)
# [3]
loss.backward()AOTAutograd가 생성한 torch.autograd.Function (예시)
def forward(self, primals_1):
_tensor_constant0 = self._tensor_constant0
maximum_default = torch.ops.aten.maximum.default(
primals_1, _tensor_constant0)
mul_tensor = torch.ops.aten.mul.Tensor(maximum_default, 3)
ge_scalar = torch.ops.aten.ge.Scalar(primals_1, 0)
return [mul_tensor, ge_scalar]
# ↑ Partitioner moved backward compute to forwards!
def backward(self, ge_scalar, tangents_1):
mul_tensor_1 = torch.ops.aten.mul.Tensor(tangents_1, 3)
scalar_tensor = torch.ops.aten.scalar_tensor.default(
0.0, dtype=torch.float32, layout=torch.strided,
device=device(type='cuda', index=0))
where_self = torch.ops.aten.where.self(
ge_scalar, mul_tensor_1, scalar_tensor)
return [where_self]오른쪽 코드에서 forward()와 backward()가 한 torch.autograd.Function 객체 안에 함께 들어 있다는 점에 주목하세요. 이것이 PyTorch 1.0 Autograd에서 언급했던 custom differentiable function 기능을 그대로 활용한 결과이며, compiled model은 “forward와 backward를 모두 가진 하나의 custom Op”처럼 동작합니다. 참고로 forward가 ge_scalar를 추가로 반환하는 것은 partitioner가 backward 계산의 일부(ge 비교)를 forward 쪽으로 옮겼기 때문이며, backward는 이 값을 받아 재계산 없이 그대로 사용합니다.
이제 [1] → [2] → [3] 순서대로 어떤 일이 일어나는지 하나씩 짚어 봅니다.
[1] outputs = compiled_model(images)
compiled_model(images)를 처음 호출하는 시점에 Dynamo가 모델을 tracing하여 FX Graph를 생성하고, 이 FX Graph가 AOTAutograd에 의해 compiled forward와 compiled backward를 모두 포함하는 torch.autograd.Function 객체로 변환됩니다 (torch.compile(model) 자체는 앞의 표에서 본 것처럼 준비 단계일 뿐입니다). 이후 이 객체의 forward 부분만 실제로 실행되어 outputs가 계산됩니다. 이와 동시에 outputs의 grad_fn으로 compiled backward가 등록되며, backward 부분 자체는 이 시점에서는 호출되지 않고 나중을 위해 보관됩니다.
[2] loss = F.cross_entropy(outputs, labels)
outputs에는 실제 계산된 값이 들어 있으므로 cross entropy 등의 loss를 계산할 수 있습니다. 이 계산은 requires_grad가 켜진 상태의 eager mode로 수행되며, 그 과정에서 loss function의 grad_fn이 새로 만들어집니다. 그리고 outputs에 이미 붙어 있던 grad_fn(compiled backward)이 이 loss function의 grad_fn에 자연스럽게 이어 붙습니다.
[3] loss.backward()
loss.backward()를 호출하면 [2]에서 만들어진 loss function의 backward가 먼저 실행되고, 이어서 그 입력이었던 outputs의 grad_fn, 즉 [1]에서 등록된 compiled backward가 하나의 큰 Op으로서 호출됩니다. 이 둘이 역방향으로 concatenate되어 순차적으로 실행되면서 model weight의 gradient가 최종적으로 계산됩니다.
즉, 사용자 입장에서는 torch.compile(model) 한 줄을 추가했을 뿐이지만, 내부적으로는 “compiled forward+backward를 가진 torch.autograd.Function을 만들어 두고, forward만 실행한 뒤 backward를 grad_fn으로 달아두었다가, loss.backward() 시점에 그것을 호출”하는 구조로 바뀌어 있습니다.
AOTAutograd Does the Magic
지금까지 설명한 과정을 조금 더 쪼개서 살펴보면, training mode에서 torch.compile()이 모델을 돌릴 때 내부적으로는 AOTAutograd라고 하는 큰 엔진이 모든 일을 담당하고 있다는 것을 알 수 있습니다. AOTAutograd는 PyTorch 2.0에서 새로 추가된 기능으로, Autograd의 forward 및 backward 과정을 한꺼번에 처리해 주는 핵심 엔진입니다.
전체 흐름을 다이어그램으로 정리하면 다음과 같습니다:
이 그림에서 주목해야 할 핵심은, training mode에서는 Dynamo가 만들어낸 FX Graph가 backend compiler로 곧바로 전달되지 않는다는 점입니다. 중간에 AOTAutograd가 반드시 끼어들어야 합니다. 왜냐하면 FX Graph에는 forward 부분만 담겨 있고, training을 하려면 그에 대응하는 backward 부분이 추가로 필요하기 때문입니다. AOTAutograd는 이 “빠진 backward”를 만들어 주고, forward와 backward를 함께 묶어 한 덩어리로 컴파일할 수 있도록 다리를 놓아 주는 역할을 합니다.
단계별로 일어나는 일:
nn.Module→ Dynamo → FX Graph: 입력된nn.Module을 Dynamo가 tracing하여 가속 가능한 부분을 FX Graph로 캡처합니다. (graph mode에서 이미 다뤘던 내용과 동일한 부분입니다.)- FX Graph → AOTAutograd 개입: Training mode에서는 FX Graph가 backend compiler로 바로 넘어가지 않고, AOTAutograd가 먼저 개입합니다. AOTAutograd는 FX Graph를 가지고 forward와 backward 연산을 함께 포함하는 joint graph를 만든 뒤, 이를 forward와 backward로 다시 분리합니다.
- 각각 따로 Backend Compile: 분리된 forward graph와 backward graph를 각각 별도로 backend compiler(예: Inductor)에 넘겨 최적화된 형태로 컴파일합니다. Forward와 backward가 서로 다른 최적화를 받을 수 있다는 점이 중요합니다.
torch.autograd.Function으로 wrap: 최적화된 forward와 backward 연산을 모두 포함하는 하나의torch.autograd.Function객체로 묶어 반환합니다.
torch.compile 실행 시 동작 흐름: Autograd가 활성화된 상태(즉 requires_grad=True인 tensor가 포함된 상태)에서 torch.compile을 호출하면 위의 1~4번 과정이 순차적으로 일어나 최종적으로 compiled forward와 compiled backward를 모두 가진 torch.autograd.Function이 반환됩니다. 이후 training loop에서 이 객체를 호출하면, 이미 컴파일된 형태의 forward와 backward가 그대로 실행되므로 가속된 training이 가능해집니다.
사용자에게 torch.compile()은 모델을 빠르게 만들어 주는 한 줄로 보이지만, 그 뒤에서 AOTAutograd가 FX Graph를 받아 joint graph 생성 → forward/backward 분리 → 각각 컴파일 → torch.autograd.Function으로 포장하는 일련의 “magic”을 수행하고 있는 것입니다. 다음 절부터 이 magic 안에서 구체적으로 어떤 일들이 일어나는지 하나씩 들여다봅니다.
Graph Mode Backward의 도전 과제
그렇다면 왜 graph mode에서 backward를 만드는 일이 어려울까요? 여기에는 두 가지 큰 도전 과제가 있으며, AOTAutograd는 각각에 대한 해결책을 제시합니다. 먼저 두 문제와 해결책의 요약을 표로 정리하고, 이어서 각각을 조금 더 풀어서 설명하겠습니다.
| Graph mode backward의 challenges | AOT Autograd의 해결책 |
|---|---|
문제 1. Autograd engine은 C++로 구현되어 있음
| → 해결 1. Backward를 C++ dispatcher 수준에서 tracing
|
문제 2. Dynamo가 생성한 FX Graph의 op들이 꽤 복잡
| → 해결 2. FX Graph를 먼저 normalization한 이후에 tracing
|
정리하면, AOTAutograd는 (1) backward tracing을 Python이 아닌 C++ dispatcher 수준에서 수행하여 “Autograd engine은 C++, Dynamo는 Python”이라는 층위 차이를 극복하고, (2) FX Graph normalization(functionalization + decomposition)을 적용하여 eager mode의 dispatcher가 암묵적으로 해 주던 복잡성 처리를 graph mode에서도 명시적으로 수행합니다. 이 두 축을 통해 graph mode에서도 eager mode와 본질적으로 같은 방식의 backward 구성을 가능하게 합니다.

AOTAutograd Architecture
AOTAutograd 전체 구조를 한눈에 보여주는 그림입니다.
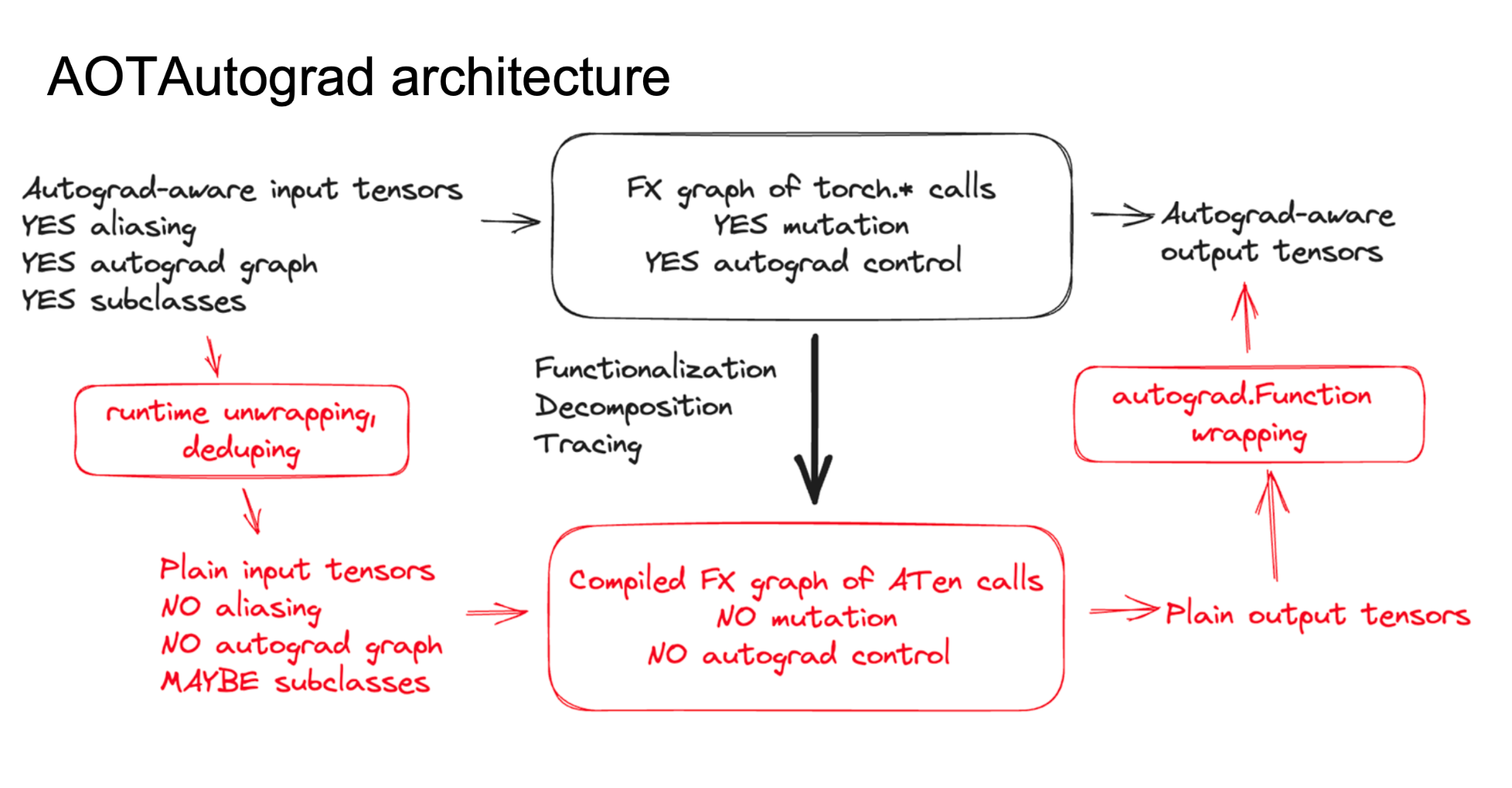
위 그림은 AOTAutograd의 전체 흐름을 보여줍니다. requires_grad가 켜져 있는 input tensor들이 딱 들어오는 시점부터 시작해서, 최종적으로 torch.autograd.Function 객체가 리턴되기까지의 과정을 한 장에 압축해 놓은 것입니다.
큰 흐름은 다음과 같습니다:
- Input → Dynamo → FX Graph:
requires_grad=True인 input tensor들이 포함된nn.Module이 들어오면, Dynamo에 의해 tracing되어 FX Graph로 변환됩니다. - Normalization (Functionalization + Decomposition): FX Graph에 Functionalization(상태 변화/aliasing 제거)과 Decomposition(고수준 op을 저수준 op으로 분해)을 적용하여 더 간단한 그래프로 정규화합니다. 이것이 앞 섹션 “Graph Mode Backward의 도전 과제”에서 이야기한 문제 2(FX Graph op의 복잡성)에 대한 해결에 해당합니다.
- C++ 수준 Tracing → Forward/Backward 그래프 동시 생성: 정규화된 그래프를 C++ dispatcher 수준에서 trace하면, 이 과정에서 forward 그래프와 backward 그래프가 동시에 만들어집니다. 이것이 문제 1(Python 수준 tracing의 한계)에 대한 해결이며, fake tensor를 활용하여 실제 값 계산 없이 trace가 수행됩니다.
- Backend Compile (각각): 동시에 얻어진 forward 그래프와 backward 그래프를 각각 별도로 backend compiler(예: Inductor)로 컴파일합니다.
torch.autograd.Function으로 매핑 & return: 컴파일된 forward/backward를 하나의torch.autograd.Function객체로 묶어 리턴합니다. 이 객체가 바로 앞서 계속 이야기했던 “compiled forward와 compiled backward를 모두 가진 custom differentiable function”입니다.
다만 이 한 장의 그림만으로는 각 단계에서 정확히 어떤 일이 일어나는지 파악하기 어렵기 때문에, 다음 절부터는 이 흐름을 수행 순서(A~I), 코드 레벨 구현, 실제 예제로 잘게 나누어 다룹니다.
AOTAutograd 수행 순서
앞 절의 architecture 그림을 좀 더 잘게 쪼개면, AOTAutograd의 전체 수행 순서는 A부터 I까지 다음과 같이 정리할 수 있습니다:
| 단계 | 과정 |
|---|---|
| A | Dynamo가 생성한 FX Graph를 input으로 받음 |
| B | Forward와 backward를 합친 joint 함수를 생성 (아직 tracing은 일어나지 않음 - “trace할 함수”를 만들어 두는 단계) |
| C | Joint 함수를 normalize (Functionalization 등을 적용하여 eager mode 복잡성을 단순화) |
| D | Joint 함수를 호출하면서 실행된 op을 C++ dispatcher 수준에서 trace |
| E | Decomposition 적용 (복잡한 op을 작은 저수준 op으로 분해) |
| F | Joint trace로부터 joint FX Graph 생성 |
| G | Joint FX Graph를 forward/backward로 분리 (단순 슬라이싱이 아니라 Min-Cut 같은 전용 알고리즘 사용) |
| H | Forward/backward를 각각 backend compiler로 컴파일 |
| I | Compiled function들을 묶어 최종 torch.autograd.Function 생성 |
B 단계: “joint 함수를 만들어놓기”: 여기서 중요한 포인트는 B 단계 자체에서는 아직 tracing이 일어나지 않는다는 것입니다. 단지 trace할 대상이 될 함수를 준비해 둘 뿐입니다. 구체적으로는 C++ 쪽의 grad 함수와 원래의 forward 함수를 back-to-back으로 호출하는 새로운 Python-level 함수를 하나 만들어 두는 과정입니다. 이렇게 만들어 둔 joint 함수를 한 번만 호출하면, 그 한 번의 호출 안에서 forward와 backward가 한꺼번에 trace되도록 설계되어 있습니다.
Joint 함수를 만드는 이유: 직관적으로는 “어차피 forward와 backward를 따로 컴파일할 건데, 왜 굳이 하나로 합친 다음 다시 쪼개는가?”라는 의문이 들 수 있습니다. 핵심 이유는 recomputation입니다. Training 시 backward는 forward의 중간 텐서 값이 필요한데, 이 텐서들이 크면 메모리를 많이 먹습니다. 모두 저장하는 대신 필요할 때 다시 계산하는 것이 유리한 경우가 있고, 반대로 저장이 더 싸게 먹히는 경우도 있어 trade-off가 존재합니다. 이 균형을 맞추려면 “forward에서 만들어진 어떤 텐서가 backward의 어떤 입력으로 연결되는가”라는 input-output 관계를 전부 알고 있어야 하는데, forward와 backward를 따로 떼어 놓으면 이 관계를 파악하기가 매우 까다로워집니다. 반면 joint 함수로 묶어 하나의 trace를 만들어 두면 이 관계가 전부 그래프에 살아 있으므로, recomputation을 포함한 최적화를 훨씬 쉽게 적용할 수 있습니다.
Joint 함수 생성 과정의 구체적 동작: Eager mode에서는 forward를 한 단계씩 실행하면서 incremental하게 각 텐서에 grad_fn을 붙여 backward graph를 만듭니다. AOTAutograd에서는 이 과정을 한 번 실행해 모든 grad_fn을 붙여 둔 뒤, 이어서 Autograd engine이 등록된 grad_fn들을 수행하는 부분(eager mode에서는 graph_task 기반으로 순회하며 각 grad_fn을 dispatch하는 그 과정)까지 같은 함수 안에 묶어 둡니다. 이 함수를 C++ dispatcher 수준에서 trace하면, forward에서 계산된 텐서와 backward에서 그것을 사용하는 지점이 모두 연결된 하나의 큰 trace가 한 번에 튀어나옵니다. 즉 목적 자체가 “순차적으로 실행해서 gradient 값을 얻는 것”이 아니라, forward 텐서가 backward input으로 이어지는 관계까지 모두 살아 있는 단일 계산 그래프를 얻는 것입니다.
Normalization(C/E 단계)이란? Eager mode에서 암묵적(implicit)으로 처리되던 복잡한 동작(aliasing, mutation, view/storage decoupling 등)을 명시적(explicit) step들로 전부 쪼개어 trace 상에 드러낸 뒤, 이를 다시 단순한 작은 Op들로 분해하는 과정입니다. 크게 보면 Functionalization(implicit한 mutation/aliasing을 명시적으로 제거)과 Decomposition(고수준 op을 저수준 op으로 분해)이 여기에 해당합니다. Normalization 덕분에 이후 partitioning과 backend compile이 더 깔끔하게 수행됩니다.
H 단계: Backend Compile의 범위: H 단계에서의 “컴파일”은 Dynamo의 tracing이 아니라, 진짜 backend compiler(예: Inductor)가 최적화된 코드를 생성하는 과정입니다. 질문이 자주 나오는 부분인데, backend-aware 최적화(per-backend 최적화)는 H 단계에서만 적용됩니다. forward/backward가 분리된 이 시점 이전에는 backend에 따른 최적화가 들어갈 여지가 없습니다.
G 단계: Partitioning 방식: Forward/backward를 어디서 쪼갤지는 Min-Cut 계열 알고리즘이 결정합니다. 이는 recomputation과도 연결되는 부분으로, “어디서 자르는 것이 메모리/연산 측면에서 가장 유리한가”를 전체 joint graph의 input-output 관계를 보고 결정하는 문제입니다. 구체적인 알고리즘 디테일은 이 자리에서는 다루지 않고, 이후 “Min-Cut Algorithm으로 Forward/Backward 분리” 절에서 간단히 짚고 넘어갑니다.
AOTAutograd 코드 레벨 동작
위에서 A~I로 정리한 단계들을 실제 코드 레벨(Python과 C++이 섞여 있지만 여기서는 Python 쪽에 초점)에서 다시 한 번 따라가 보겠습니다. 가장 top-level 함수는 aot_dispatch_autograd()이며, 여기서 일어나는 일은 크게 세 덩어리로 볼 수 있습니다:
aot_dispatch_autograd_graph()를 호출하여 joint FX Graph를 만들어내기 (A~F)- 그 joint FX Graph를 G 단계의 partitioning으로 forward/backward로 분리하고 각각 컴파일 (G~H)
- 컴파일된 forward/backward를
torch.autograd.Function으로 wrap해서 return (I)
# A: 최상위 함수
aot_dispatch_autograd(flat_fn)
# Joint FX Graph 생성
fx_g = aot_dispatch_autograd_graph(flat_fn, ...)
# B: Joint 함수 생성. forward와 backward를 붙여서
# forward만 실행해도 둘 다 계산되는 함수를 만듦
joint_fn_to_trace = create_joint(flat_fn, ...)
def inner_fn(...)
outs = fn(*primals) # Forward 실행
backward_out = torch.autograd.grad(...) # Backward 실행
return outs, backward_out
# C: Normalization 수행. eager mode의 복잡성을 제거
joint_fn_to_trace = create_functionalize_fn(joint_fn_to_trace, ...)
joint_fn_to_trace = aot_dispatch_subclass(joint_fn_to_trace, ...)
# D, E, F: 실제 tracing 수행 + Decomposition + FxGraph 생성
# D: joint_fn_to_trace에 대한 실제 tracing이 일어남
# E: Decomposition (Torch IR → ATen IR → Core ATen IR → Prims IR)
# F: 최종 Joint FX Graph 생성
fx_g = _create_graph(joint_fn_to_trace, ...)
# G: Partitioning. Joint FX Graph를 forward/backward로 분리
fw_module, bw_module = partition_fn(fx_g, ...)
# H: Compile 수행. 각각 backend compiler로 컴파일
compiled_fw_func = fw_compiler(fw_module, ...)
compiled_bw_func = bw_compiler(bw_module, ...)
# I: 최종 결과물. torch.autograd.Function으로 wrap하여 반환
compiled_fn = AOTDispatchAutograd.post_compile(compiled_fw_func, ...)이 중 가장 복잡한 부분은 joint FX Graph를 만들어내는 과정(BF)이고, 그 외 GI는 상대적으로 기계적인 단계에 가깝습니다.
- B 단계 -
create_joint(flat_fn, ...): Forward 부분과 backward 부분에 해당하는 함수를 하나로 붙여서, “forward 쪽만 호출해도 내부적으로 forward와 backward가 같이 계산되는 함수”를 만들어 둡니다. 위 코드의inner_fn이 그 함수이고,fn(*primals)로 forward를 실행한 뒤 곧바로torch.autograd.grad(...)로 backward까지 실행하도록 묶어 놓은 형태입니다. - C 단계 - Normalization: B에서 만든 joint 함수를 그대로 trace하면 eager mode의 복잡성(aliasing, mutation 등)이 그대로 따라 들어오기 때문에,
create_functionalize_fn,aot_dispatch_subclass등을 통해 먼저 함수 자체를 정규화된 형태로 바꿔 둡니다. - D~F 단계 -
_create_graph(joint_fn_to_trace, ...): 여기가 실제로 tracing이 일어나는 지점입니다. 정규화된 joint 함수를 C++ dispatcher 수준에서 trace하여 decomposition까지 적용한 뒤, 최종 joint FX Graph를 만들어냅니다.
여기서 C 단계의 normalization과 E 단계의 decomposition은 서로 다른 목적의 정규화라는 점을 구분해 두는 것이 좋습니다. Normalization은 eager mode가 가지고 있던 복잡한 동작(aliasing, mutation 등)을 명시적으로 풀어내는 과정인 반면, decomposition은 수많은 Torch Op을 정해진 소수의 저수준 Op들로 표현하기 위한 IR 변환 과정(Torch IR → ATen IR → Core ATen IR → Prims IR)입니다. 두 과정을 거쳐 만들어진 joint FX Graph가 G 단계의 partitioning으로 forward/backward로 다시 쪼개지고, H 단계에서 각각 backend compile된 뒤, I 단계에서 torch.autograd.Function으로 wrap되어 return됩니다.
AOTAutograd 실행 예제
이후 단계별 설명에서 사용할 실행 예제 코드입니다:
@torch.compile()
def func(a, b):
return torch.clamp_min(a, b) * 3
p = torch.tensor([0.4, -0.2], requires_grad=True, device='cuda')
loss = func(p, 0).sum()
loss.backward()
print(p.grad)Joint Graph 생성
앞 절 “AOTAutograd 수행 순서”에서 언급한 B 단계(joint 함수 생성) → D 단계(실제 tracing) → G 단계(partitioning)가 실제로 어떤 모습인지 슬라이드의 코드로 확인해 봅니다. Joint graph를 만들기 전에는 Python 수준에서 먼저 “joint 함수”를 명시적으로 만들어 두는 작업이 필요합니다.
출처: How does torch.compile work with autograd? - PyTorch Dev Discussions
[B-1] Dynamo가 만들어낸 FX Graph (forward만 있음)
def f(*inputs):
return outputsDynamo가 만들어낸 이 FX Graph는 joint graph의 forward 부분에 해당합니다. 이 자체로는 backward가 없기 때문에, training을 위해서는 여기에 backward를 붙여야 합니다.
[B-2] Forward + Backward를 합친 joint 함수
# In order to get the backwards pass, we trace something like:
def joint_fw_bw(fw_inputs, grad_outs):
fw_out = f(*fw_inputs)
grad_inps = torch.autograd.grad(
fw_out, leaves=fw_inputs, gradOuts=grad_outs)
return fw_out, grad_inpsf()를 수행한 뒤 곧바로 torch.autograd.grad()를 호출하여 backward까지 같이 수행하는 하나의 함수로 묶어 둡니다. (위 코드는 원문 슬라이드의 pseudocode를 그대로 옮긴 것으로, 실제 torch.autograd.grad의 인자 이름은 inputs=, grad_outputs=입니다.) 겉보기에는 forward를 한 번 부른 것처럼 보이지만, 그 안에서 backward가 forward의 연장선처럼 자연스럽게 이어져 실행됩니다.
[D] joint 함수를 trace하여 Joint Graph 생성
joint_fw_bw를 (내부의 torch.autograd.grad 호출이 동작하는 상태 그대로) C++ dispatcher 수준에서 trace하면, autograd가 만들어내는 backward 계산 경로까지 함께 기록되어 forward와 backward가 모두 포함된 joint graph가 한 번에 만들어집니다.
Joint Function의 Input 구성
joint_fw_bw의 입력은 두 종류로 구성됩니다:
- Forward Input (
fw_inputs): 원래 모델이 받는 입력값 그대로. - Backward Input (
grad_outs): Loss로부터 전달되는 최종 gradient 값.
왜 grad_outs가 필요할까요? Backward를 계산하려면 일반적으로 ① loss 쪽에서 내려오는 최종 gradient와 ② forward 중간 단계에서 계산된 tensor들이 필요합니다. 이 중 중간 tensor들은 joint graph 안에 forward 부분으로 이미 포함되어 있으므로 별도 input으로 넘길 필요가 없습니다. 반면 loss function은 이 FX Graph 바깥에 있어 캡처되지 않으므로, loss에서 내려오는 grad_outs만큼은 반드시 joint 함수의 input으로 넣어 줘야 최종 gradient를 끝까지 계산할 수 있습니다.
[G] Joint Graph → Forward/Backward 분리
Then, we simply partition this graph into two
to give us the forwards pass and the backwards pass.이렇게 얻어진 joint graph를 적절한 기준(이후 절에서 다룰 Min-Cut 알고리즘)으로 partition하면 forward pass와 backward pass로 다시 분리할 수 있습니다.
[참고] 원문(PyTorch Dev Discussions) 기준 보충 사항
위 설명은 강연 transcript에 기반한 풀이이며, 원문 How does torch.compile work with autograd?과 대조하면 다음 몇 가지를 추가로 알아두면 좋습니다:
grad_outs가 필요한 이유 (원문): “backward computation depends on incoming gradients”, 즉 backward 계산이 본질적으로 외부에서 들어오는 gradient 신호에 의존하기 때문이라는 일반적 서술이며, “loss function이 FX Graph 바깥이라서”라는 구체화는 강연자의 해석입니다.- Partitioning의 성격: 원문은 forward/backward partition이 “not strictly disjoint”라고 명시합니다. 메모리 효율을 위해 backward pass가 forward graph의 일부를 재계산(recomputation)할 수 있으며, 어느 부분을 저장하고 어느 부분을 재계산할지는 partitioning 단계의 최적화 결정입니다. (이 주제는 뒤의 “Activation Checkpointing” 절에서 다시 다룹니다.)
[D 단계] Joint Graph Example
앞 절의 joint_fw_bw를 C++ dispatcher 수준에서 trace하면, forward와 backward가 모두 하나의 graph 안에 들어간 joint FX Graph가 만들어집니다. 이것이 수행 순서표의 D 단계 결과물입니다.

위 그래프에서 볼 수 있듯, forward 연산과 backward 연산이 동일한 계산 그래프 안에 공존하며, forward에서 만들어진 중간 텐서가 backward 노드의 입력으로 연결되는 관계까지 전부 살아 있습니다. 이 구조 덕분에 이어지는 G 단계의 partitioning에서 “어떤 텐서는 저장하고 어떤 텐서는 재계산할지”를 판단할 수 있게 됩니다.
[E 단계] Decomposition (+ Functionalization)
D 단계에서 만들어진 joint graph는 아직 Torch IR 수준의 고수준 op들을 포함하고 있습니다. E 단계(Decomposition)에서는 이 op들을 더 낮은 수준의 작은 op들로 분해하여, backend compiler가 다루기 쉬운 형태로 내려 줍니다. 참고로 C 단계의 Functionalization(aliasing/mutation 제거)도 이 흐름 상에서 같이 이해해 두면 normalization 전체 그림이 잡힙니다.

IR 계층은 다음과 같이 단계적으로 내려갑니다:
Torch IR → ATen IR → Core ATen IR → Prims IR
- Functionalization (C 단계 일부): Eager mode가 암묵적으로 허용하던 in-place mutation, aliasing 등을 명시적으로 풀어내 pure function 형태로 변환.
- Decomposition (E 단계): 수천 개에 달하는 Torch op을 정해진 소수의 Prims IR op으로 분해 - eager mode 복잡성 제거와는 별개의 목적(op set 축소)으로, backend 최적화가 쉬워집니다.
[G 단계] Min-Cut Algorithm으로 Forward/Backward 분리
E 단계까지 거쳐 정규화된 joint FX Graph를 이제 G 단계에서 forward와 backward로 다시 쪼갭니다. 앞서 말한 Min-Cut 계열 알고리즘이 사용되며, 이 단계의 결정이 곧 “어느 중간 텐서를 저장(save)하고 어느 것을 재계산(recompute)할지”와 직결됩니다.
입력은 [D 단계] Joint Graph Example에서 본 그래프, 즉 forward와 backward 노드가 한 그래프 안에 얽혀 있는 상태입니다. 여기에 Min-Cut을 적용하면 forward와 backward가 각각 독립된 FX Graph로 깔끔하게 분리됩니다.


이 partitioning 과정에서 한 가지 흥미로운 점은 계산을 어느 쪽에 둘지까지 최적화한다는 것입니다. 앞쪽 “What Happens When Training with torch.compile()?” 절에서 본 compiled forward/backward 코드를 다시 떠올려 보면, backward에서 쓰일 비교 결과(ge_scalar)가 forward 쪽에서 미리 계산되어 반환되고 있습니다. 이것이 슬라이드의 “Partitioner moved backward compute to forwards!” 주석이 가리키는 부분이며, partitioner가 메모리/연산 trade-off를 고려해 계산 위치를 옮긴 결과입니다.
Partitioning이 끝나면 forward graph와 backward graph 각각이 독립된 FX Graph로 떨어져 나오고, 이후 H 단계에서 backend compiler(예: Inductor)가 forward/backward를 각각 별도로 컴파일하여 최적화된 실행 코드를 생성합니다.
Activation Checkpointing
앞서 joint graph가 필요한 이유를 설명할 때 잠깐 언급했던 recomputation(재계산)은, training 분야에서는 보통 “activation checkpointing” 이라는 이름으로 더 많이 불립니다. (강연자 역시 training 전문가는 아니어서 이 용어가 다소 낯설 수 있다고 언급했습니다.)
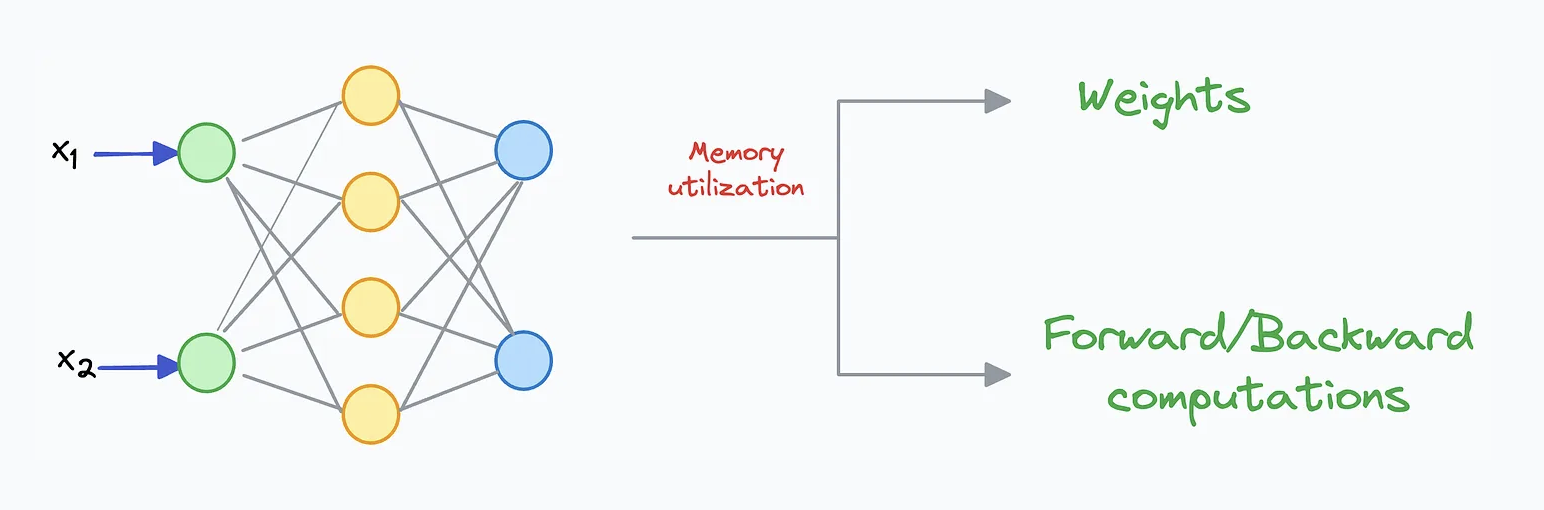
Batch size가 커질수록 forward 과정의 중간 activation도 함께 커지며, 이 값들을 전부 저장해 두면 GPU 메모리를 상당히 많이 차지합니다.

Segment별로 입력 activation만 저장해 두고, backward를 수행할 때 segment 단위로 forward를 다시 돌려 필요한 중간값을 그때그때 재계산합니다.
Recomputation이란? 모델 학습 과정에서 일부 중간 계산(특히 중간 activation)을 곧바로 저장하지 않고, 나중에 필요할 때 다시 계산함으로써 GPU 메모리를 절약하는 기법입니다. Forward 과정에서 모든 중간 값을 전부 저장해 두면 메모리를 많이 차지하지만, 일정 부분만 저장해 두고 backward 과정에서 필요한 시점에 다시 계산(재계산)하게 되면 메모리 사용량을 크게 줄일 수 있습니다. 다만 필요한 시점에 다시 계산하는 추가 연산이 발생하므로, 메모리를 아끼는 대신 연산량(시간)은 조금 늘어나는 trade-off가 있습니다. 이 방식은 흔히 “activation checkpointing”이라고 부르며, 여러 딥러닝 프레임워크에서 관련 기능을 지원합니다.
AOTAutograd 관점에서 중요한 것은, 앞서 강조한 joint graph 덕분에 “forward에서 만들어진 어떤 텐서가 backward의 어떤 입력으로 연결되는가”라는 input-output 관계가 전부 살아 있다는 점입니다. 이 관계를 알고 있으면 Min-Cut partitioner가 “어느 텐서는 저장(save)하고 어느 텐서는 재계산(recompute)하는 것이 더 유리한가”를 전체 그래프 관점에서 판단할 수 있어, activation checkpointing을 보다 자동화되고 효율적으로 적용할 수 있습니다.
[I 단계] Compiled Model = torch.autograd.Function
이제 AOTAutograd 수행 순서의 마지막 단계입니다. G 단계에서 forward/backward로 분리하고 H 단계에서 각각 backend compile한 결과물을 하나로 묶어 torch.autograd.Function 객체로 wrap해서 돌려주는 것이 바로 I 단계입니다. 최종 결과물은 compiled forward()와 compiled backward()가 한 객체 안에 나란히 들어 있는 형태가 됩니다. 아래는 그 형태를 이해하기 위한 공식 문서의 hand-written 예제입니다 (AOTAutograd의 실제 출력물은 앞서 본 “AOTAutograd가 생성한 torch.autograd.Function” 예시를 참고하세요):
class MyCube(torch.autograd.Function):
@staticmethod
def forward(x):
result = x ** 3
# In regular PyTorch, if we had just run y = x ** 3, then the backward
# pass computes dx = 3 * x ** 2. In this autograd.Function, we've done
# that computation here in the forward pass instead.
dx = 3 * x ** 2
return result, dx
@staticmethod
def setup_context(ctx, inputs, output):
x, = inputs
result, dx = output
ctx.save_for_backward(x, dx)
@staticmethod
def backward(ctx, grad_output, grad_dx):
x, dx = ctx.saved_tensors
# In order for the autograd.Function to work with higher-order
# gradients, we must add the gradient contribution of `dx`.
result = grad_output * dx + grad_dx * 6 * x
return resulttorch.autograd.Function은 PyTorch 2.0에서 새로 만들어진 개념이 아닙니다. 앞서 “PyTorch 1.0: Autograd” 절의 세 번째 특징으로 다뤘던 custom differentiable function 기능이 바로 이것으로, 사용자가 직접 만든 custom op에 대해 자신만의 미분 규칙을 기술해 붙일 수 있도록 PyTorch 1.0부터 존재해 온 장치입니다. AOTAutograd는 이 기존 메커니즘을 그대로 재활용합니다.
Dynamo가 FX Graph로 캡처한 덩어리를 eager mode 관점에서 바라보면 하나의 거대한 custom Op으로 생각할 수 있습니다. 그렇다면 이 custom Op에는 custom 미분 함수가 필요한데, 사람이 수많은 op을 포함하는 FX Graph에 대한 미분 함수를 손으로 작성하기는 사실상 불가능합니다. AOTAutograd가 바로 그 미분 함수를 자동으로 만들어 주는 역할을 하고, 생성된 compiled forward/backward를 torch.autograd.Function으로 포장하여 “미분 가능한 하나의 custom Op”으로 돌려주는 것입니다. 지금까지 여러 각도에서 설명한 AOTAutograd 내부의 복잡한 과정들이 모두 이 custom 미분 함수를 자동 생성하기 위한 작업이었다고 볼 수 있습니다.
torch.autograd.Function이 통합하는 두 가지 개념 (PyTorch 공식 문서):
PyTorch combines the following two concepts into
torch.autograd.Function:
- You wish to call code that does not contain PyTorch operations and have it work with function transforms. That is, the
torch.autograd.Function’sforward/backward/etc calls into functions from other systems like C++, CUDA, numpy.- You wish to specify custom gradient rules, like JAX’s
custom_vjp/custom_jvp.
AOTAutograd의 출력은 이 두 가지 중 두 번째(custom gradient rules)를 적극적으로 활용합니다. FX Graph로 캡처된 Python 코드 덩어리에 대해, AOTAutograd가 생성한 compiled backward를 custom gradient rule로 등록하여 Autograd engine이 마치 기본 제공 op처럼 자연스럽게 이 덩어리를 미분할 수 있게 만듭니다.
결과적으로
AOTAutograd가 만들어낸 torch.autograd.Function이 실제 학습 루프에서 어떻게 호출되는지를 세 단계로 정리하면 다음과 같습니다.
[1] Compile된 forward() 호출
사용자가 compiled model을 호출하면 torch.autograd.Function의 forward() 부분이 실제로 실행됩니다. 이 forward 코드는 등록된 backend가 이미 컴파일해 둔 상태이므로 가속된 형태로 동작합니다.
→ 등록된 backend가 forward를 미리 컴파일
[2] Compile된 backward()가 output tensor의 grad function으로 등록
Forward가 실행되는 동안, 함께 묶여 있던 compiled backward()는 곧바로 실행되지는 않고 output tensor의 grad_fn으로 등록됩니다. 즉 나중에 loss.backward()가 호출될 때 타고 들어갈 수 있도록 “대기 상태”로 걸어 두는 단계입니다.
[3] loss.backward() 수행 과정에서 compiled backward() 실행
이후 loss 쪽에서 backward()가 호출되면 Autograd engine이 등록된 grad_fn을 따라 내려오다가 [2]에서 걸어 둔 compiled backward에 도달하고, 이때 한 스텝으로 backward 함수가 실행됩니다. 이 backward 코드 역시 등록된 backend가 별도로 컴파일해 둔 형태이므로 가속된 실행이 이루어집니다.
→ 등록된 backend가 backward를 미리 컴파일
결과적으로 forward와 backward 둘 다 backend compiler로 미리 최적화되어 있고, 사용자가 작성한 학습 루프는 거의 그대로 둔 채 내부적으로만 가속된 실행 경로를 타게 됩니다.
Q&A
강연 말미에 오간 Q&A를 정리했습니다. 본문에서 다루지 못한 세부 의도나 한계가 담겨 있습니다.
Q1. [B 단계] inner_fn의 outs와 backward_out은 각각 무엇인가요?
A. outs는 forward를 수행했을 때 나오는 output, 일반적으로 input이 들어왔을 때 나가는 그 output입니다. 반면 backward_out은 backward의 결과물, 즉 weight들의 gradient에 해당합니다.
Q2. 앞 설명에서 B 단계는 joint graph를 만드는 부분이라고 했는데, 코드를 보면 forward와 backward가 분리돼 있는 것처럼 보입니다.
A. 여기서 B 단계는 joint graph 자체를 만드는 것이 아니라, “trace의 입력이 될 함수”를 먼저 준비해 두는 단계입니다. forward와 backward를 붙인 inner_fn이 그 함수이고, 이 함수의 input은 원래 모델의 input + loss로부터 흘러 들어오는 gradient(grad_outs)이며, output은 forward 결과 + weight들의 gradient입니다. 이 함수를 D 단계에서 한 번 trace하면 forward/backward가 모두 연결된 joint graph가 만들어집니다.
Q3. Joint Graph 생성 슬라이드에서, forward를 수행하면서 backward가 되는데 outputs가 또 하나의 input으로 다시 들어가는 건가요?
A. 혼동이 생길 수 있는데, training loop 다이어그램을 떠올리면 이해가 쉽습니다. 실제 forward 흐름(training data input → 모델 → output → loss function → gradient)에서, loss function은 joint graph 바깥에 남아 있고, 그 loss로부터 내려오는 gradient가 backward의 시작점이 됩니다. 따라서 joint graph의 관점에서:
- Input: ① 원래 모델의 input (forward를 시작시키는 값), ② loss function으로부터 흘러 들어오는 backward-trigger gradient (
grad_outs) - Output: ① 원래 모델의 forward output (바깥에서 loss를 계산하는 데 필요), ② 다음 iteration에서 optimizer가 보정해야 할 weight들의 gradient
슬라이드의 joint_fw_bw에서 fw_inputs가 ①의 input, grad_outs가 ②의 input에 해당하고, fw_out과 grad_inps가 각각의 output에 해당합니다.
Q4. 모델뿐 아니라 loss 계산과 optimizer까지 포함해서 한꺼번에 trace하고 최적화하는 방법도 가능할까요?
A. 좋은 질문입니다. 개념적으로는 “What Happens When Training with torch.compile()?” 절에서 봤던 전체 학습 루프(왼쪽 코드)를 통째로 하나의 함수로 정의한 뒤 compile하면 되겠지만, 현실적으로는 난점이 있습니다. Loss 계산이나 optimizer 쪽 코드에서 graph break가 발생할 가능성이 커서 하나의 trace로 깔끔하게 묶기 어렵기 때문입니다. 이를 해결하기 위해 PyTorch 팀에서는 Compiled Autograd 같은 새로운 시도를 진행 중입니다. 다만 loss 계산 자체가 전체 training 시간에서 차지하는 비중이 크지 않기 때문에, “다 합쳐 하나로 trace하면 얼마나 더 빨라질지”는 해봐야 알 수 있는 부분이라고 생각합니다.
Q5. torch.compile 과정에서 Dynamo가 fake tensor로 FX graph만 만들어내는 것인지, 아니면 실제 하드웨어에서 돌아갈 코드까지 생성하는 것인지 헷갈립니다.
A. Dynamo가 하는 일은 FX graph 캡처까지이고, 하드웨어 코드 생성은 그 뒤에 붙는 backend compiler가 맡습니다. Dynamo에 어떤 backend(예: Inductor, TensorRT 등)를 붙이느냐에 따라 결과가 달라지며, backend가 연결되어 있으면 캡처된 FX graph가 그 backend의 input으로 전달되어 실제 하드웨어에서 실행 가능한 코드까지 생성됩니다. 최종적으로는 이 결과물이 nn.Module 형태로 감싸져 사용자에게 돌아오고, 모듈을 실행하면 내부에서 적절한 하드웨어로 dispatch되어 실제 연산이 수행됩니다.
Appendix: Grad Function Codegen 재현 방법
본문 “[참고] Grad Functions” 섹션에 등장한 AddBackward0, MulBackward0 등의 C++ 코드는 PyTorch 소스 트리에 커밋되어 있지 않고, 빌드 과정에서 tools/autograd/의 codegen 스크립트가 derivatives.yaml을 읽어 생성합니다. 본 강의 자료는 PyTorch v1.13.1을 기준으로 codegen만 별도로 재현해서 결과물을 인용했으며, 재현 방법은 다음과 같습니다.
1. 환경 준비
PyTorch 1.13.1은 Python 3.7 ~ 3.10까지만 지원하므로 Python 3.10 가상환경을 사용합니다. 전체 PyTorch 빌드는 필요 없고 codegen만 돌리면 되므로 의존성도 pyyaml, typing_extensions 두 개면 충분합니다.
mkdir -p /tmp/pytorch-codegen-113
cd /tmp/pytorch-codegen-113
# v1.13.1 태그만 shallow clone (전체 히스토리 불필요)
git clone --branch v1.13.1 --depth 1 https://github.com/pytorch/pytorch.git
# uv로 Python 3.10 venv 생성 후 최소 의존성만 설치
uv venv --python 3.10 .venv
source .venv/bin/activate
uv pip install pyyaml typing_extensions2. Codegen 실행
tools/autograd/gen_autograd.py는 다음 네 가지 인자를 받습니다:
native_functions.yaml경로 - 네이티브 op 목록tags.yaml경로 - op에 붙는 태그 목록- 출력 디렉토리
- autograd 디렉토리(
derivatives.yaml, 템플릿 위치)
cd /tmp/pytorch-codegen-113/pytorch
mkdir -p /tmp/pytorch-codegen-113/generated
python -m tools.autograd.gen_autograd \
aten/src/ATen/native/native_functions.yaml \
aten/src/ATen/native/tags.yaml \
/tmp/pytorch-codegen-113/generated \
tools/autograd정상 종료되면 /tmp/pytorch-codegen-113/generated/ 아래에 다음 파일들이 생성됩니다:
ADInplaceOrViewType_{0,1}.cpp # inplace/view op dispatch
Functions.h # AddBackward0, MulBackward0, ... struct 선언
Functions.cpp # 각 backward의 apply() 구현
TraceType_{0..4}.cpp # JIT tracer용 kernel
VariableType.h
VariableType_{0..4}.cpp # Autograd dispatch key kernel (forward hook)
variable_factories.h본 강의에서 인용한 코드는 이 중 Functions.h와 Functions.cpp입니다.
3. 관심 있는 backward 클래스 찾기
전체 파일이 수천 라인이므로 class/함수명으로 찾는 것이 편합니다.
# 헤더에서 struct 선언 위치
grep -n "^struct TORCH_API AddBackward0" \
/tmp/pytorch-codegen-113/generated/Functions.h
# 구현부에서 apply() 위치
grep -n "^variable_list AddBackward0::apply" \
/tmp/pytorch-codegen-113/generated/Functions.cpp4. YAML ↔ 생성 코드 대응관계 확인
derivatives.yaml의 원본 항목과 codegen 결과를 같이 읽으면 어떤 식이 어디로 박히는지 확인할 수 있습니다.
# derivatives.yaml 원본
grep -n -A 3 "^- name: add\.Tensor" \
/tmp/pytorch-codegen-113/pytorch/tools/autograd/derivatives.yaml
# 생성된 apply() 본문
sed -n '47,65p' /tmp/pytorch-codegen-113/generated/Functions.cppself: / other: 항목에 적힌 표현식(handle_r_to_c(...), mul_tensor_backward(...) 등)이 apply() 내부의 grad_result = any_grad_defined ? (...) : Tensor(); 위치에 그대로 치환되는 것을 눈으로 확인할 수 있습니다.
5. 다른 PyTorch 버전으로 재현하고 싶을 때
동일한 절차를 최신 버전(예: v2.3.0)으로 바꿔 실행하면 됩니다. 단, 주의점은 다음과 같습니다.
- PyTorch 2.x는 Python 3.8+만 지원, 최신 버전일수록 Python 3.11/3.12를 권장합니다.
gen_autograd.py의 인자 구성이 바뀌기도 하니 해당 버전의 파일 상단 docstring을 먼저 읽는 편이 안전합니다.- codegen은 Autograd 쪽 뿐 아니라
torchgen/gen.py(ATen 전체)도 있으며, 이쪽 결과물(예:RegisterCPU.cpp,TypeDefault.cpp)을 보면 dispatch 테이블이 어떻게 구성되는지 확인할 수 있습니다.