Week 3: PyTorch Graph Mode
PyTorch + NPU 온라인 모임 #3 | 2024-12-18
PyTorch의 역사와 2.0의 변화
PyTorch 2.0에서 가장 크게 변한 부분은 그래프 모드(graph mode)의 도입입니다. 그래프 모드가 왜 필요해졌는지 알려면 먼저 PyTorch가 걸어온 길을 간략히 짚어볼 필요가 있습니다.
Lua Torch 시대
PyTorch의 기원은 Torch에서 시작됩니다. Torch는 원래 C/C++로 작성된 라이브러리였으며, 이를 더 편하게 사용하기 위해 스크립트 언어를 올렸는데, 처음 선택된 것이 Lua였습니다. 이것이 Lua Torch입니다.
PyTorch의 탄생
Lua보다 Python이 훨씬 더 인기 있는 언어였기 때문에, Meta(당시 Facebook)에서 Python 기반의 PyTorch 프로젝트를 시작했습니다. 당시에는 TensorFlow가 대세였고, PyTorch는 지금처럼 큰 프로젝트가 될 것이라 기대하지 않았습니다. 연구자들이 TensorFlow의 복잡한 사용성에 어려움을 겪고 있었기 때문에, 그 문제를 해결하고자 eager mode 철학을 중심으로 개발을 시작했습니다.
이 접근 방식은 특히 리서치 커뮤니티에서 큰 호응을 얻으며 PyTorch가 빠르게 성장하는 계기가 되었습니다. 다만 이 시기의 PyTorch는 주로 연구자들이 사용하는 도구였으며, production 환경에서 사용할 수준은 아니었습니다.
PyTorch 1.0: Production 지원
PyTorch의 인기가 높아지면서, production 환경에서도 사용할 수 있는 형태로 발전할 필요가 생겼습니다. PyTorch 1.0에서는 TorchScript (jit.trace, jit.script) 기능이 추가되어 그래프 캡처 기능이 도입되었습니다.
PyTorch 2.0: 그래프 모드의 본격 도입
PyTorch 2.0에서는 1.0 대비 가장 크게 변한 부분이 그래프 모드입니다. 전체적인 구조는 프론트엔드 → 백엔드 → 코드 생성 백엔드의 형태로, 일반적인 컴파일러 아키텍처와 유사합니다. 다만 몇 가지 차이점이 있습니다:
- Dynamo: 그래프를 캡처하는 새로운 모듈이 프론트엔드에 추가
- Autograd 통합: 머신러닝을 위한 컴파일러이므로 자동 미분 기능이 백엔드 과정에 포함
- Inductor 및 다양한 백엔드 지원: 여러 백엔드 중 대표적으로 Inductor가 있으며, 그 하위에 Triton 등의 코드 생성 백엔드가 연결
이 시기에 PyTorch가 Linux Foundation에 기부되며 PyTorch Foundation이 설립되었습니다.
PyTorch 2.0 이후로 eager mode의 유연성과 graph mode의 컴파일러 최적화를 결합한 형태로 발전하면서, 연구뿐만 아니라 production에서도 널리 쓰이게 되었습니다.
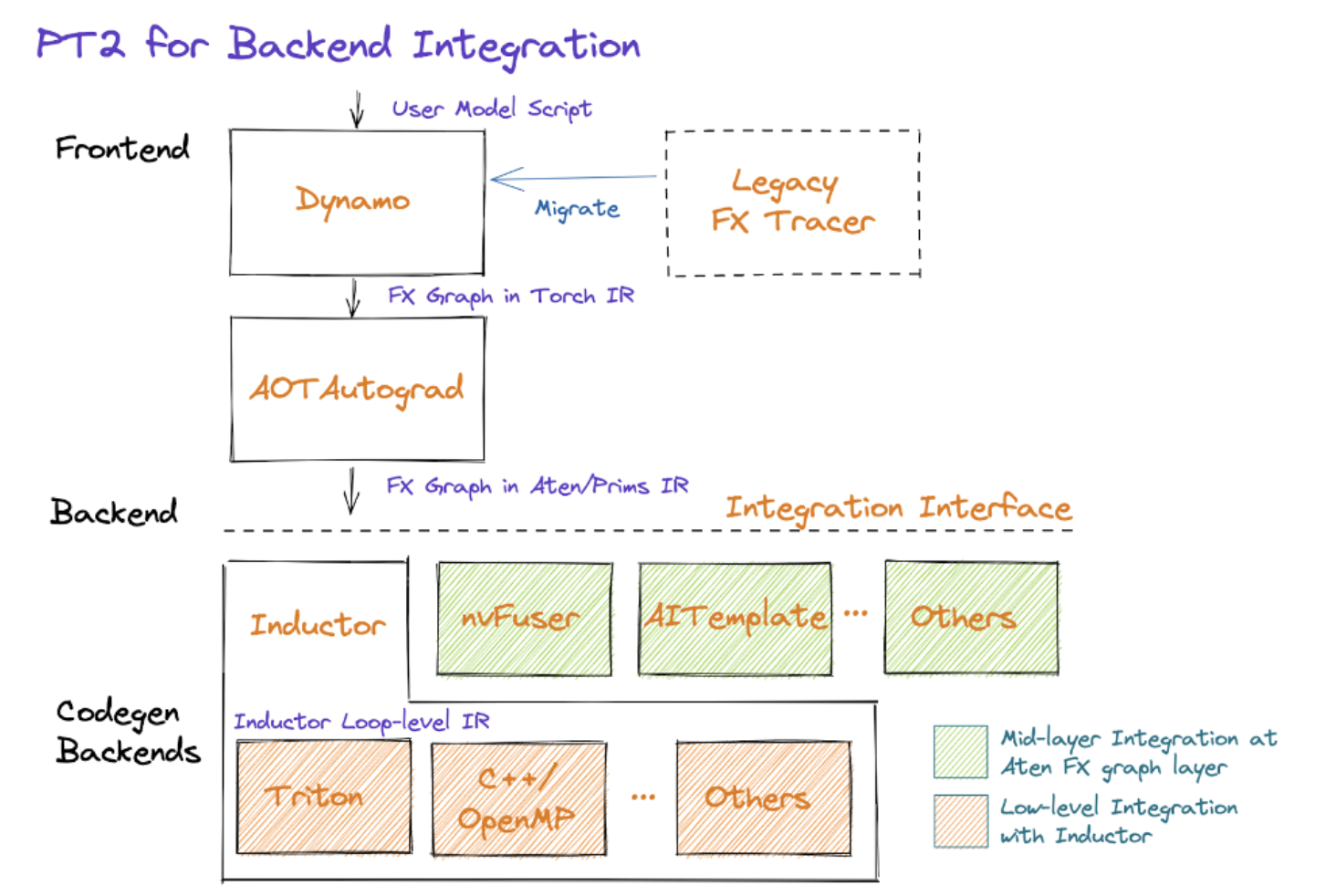
https://pytorch.org/get-started/pytorch-2.0/
이번 강의의 범위
위 그림에서 보이는 PyTorch 2.0의 전체 아키텍처 중, 다음 내용은 이번 강의에서 다루지 않습니다:
- Legacy FX Tracer - 레거시 기능이므로 생략
- AOTAutograd - 다음 주(Week #4)에서 다루는 것이 더 적절
- Codegen backends - NVIDIA GPU 관련 이야기를 할 때 함께 다루는 것이 더 적절
따라서 이번 강의에서는 나머지 부분을 중심으로 다음 내용을 다룹니다:
- Tracing 개념 - Graph mode의 근간이 되는 tracing의 기본 개념을 먼저 정리
- Dynamo - 오늘의 핵심 주제. 대부분의 시간을 Dynamo의 동작 원리를 설명하는 데 할애
- IR과 Lowering - PyTorch 2.0에서 컴파일러 구조에 가까워지면서 Intermediate Representation(IR) 개념이 정립되고, 여러 단계로 IR이 분할되는 lowering 과정이 추가됨
- Device Backend 통합 -
torch.compile을 통해 다양한 디바이스 백엔드를 어떻게 연결하는지 간략히 소개
Graph Capturing
Tracing이란?
Tracing은 프로그램의 실행 경로를 기록하는 기법입니다. 그 바탕이 되는 Control Flow Graph(CFG)와 Trace의 개념부터 정리하겠습니다.
소스 코드 (Pseudo Code)
일반적인 C 프로그램과 비슷한 형태의 pseudo code입니다. 변수의 조건에 따라 특정 부분이 실행되거나 실행되지 않을 수 있는 구조입니다.
L1: input(a, b, c);
L2: d ← b * b - 4 * a * c;
L3: if (d > 0) then
L4: r ← 2
L5: else_if (d = 0) then
L6: r ← 1
L7: else_if (d < 0) then
L8: r ← 0;
L9: output(r);Control Flow Graph (CFG)
위 소스 코드를 그래프 형태로 표현한 것이 컨트롤 플로우 그래프(CFG) 입니다.
- 노드(Node): 분기점이 없는 연속적인 코드 블록(시퀀스)입니다. 한 노드 내의 코드는 순차적으로 실행됨이 보장됩니다. 이 예제에서는 코드 한 줄이 하나의 노드에 해당하지만, 실제 컴파일러에서는 여러 instruction의 시퀀스가 하나의 노드를 이룹니다.
- 에지(Edge): 노드 간의 연결로, 프로그램의 실행 흐름(branch, jump)을 나타냅니다. 한 블록에서 다른 블록으로 이동 가능한 모든 경로가 화살표로 표시됩니다.
Trace
프로그램을 실제로 실행했을 때, CFG 상에서 어떤 노드들을 거쳤는지를 순서대로 기록한 것이 Trace입니다. Trace는 결과적으로 linear list 형태가 됩니다. 반복문이 있으면 동일한 노드가 여러 번 나타날 수 있지만, 여전히 linear list로 기록됩니다.
예를 들어 d = 0일 때의 Trace는 다음과 같습니다:
이 때 프로그램을 실행하면서 trace만 만들어내는 가상의 실행 엔진을 생각할 수 있습니다. 프로그램과 입력이 주어지면, 종료될 때까지 실행하면서 trace를 생성하는 것입니다.
Tracing의 특징과 한계


이론적으로 프로그램 전체를 trace로 만들 수 있지만, 두 가지 한계가 있습니다:
- 전체 Trace 생성은 비효율적: 1GHz CPU라면 1초에 10억 개의 Op이 수행되므로, 일반적인 프로그램에서는 엄청나게 긴 trace가 생성됩니다. (머신러닝 코드는 예외일 수 있습니다.)
- Trace는 입력 의존적: 같은 프로그램이라도 입력이 다르면 trace가 달라지므로, 하나의 trace만으로 모든 실행을 일반화할 수 없습니다.
Trace 기반 최적화
이러한 한계에도 불구하고, trace를 잘 추출할 수 있다면 다양한 최적화를 수행할 수 있습니다. 기본적인 아이디어는 다음과 같습니다:
- 반복 수행되는 구간을 찾아 trace로 추출하고, 최적화를 적용
- 프로그램 실행 중 해당 trace에 진입했다고 판단되면, 실제 코드 대신 미리 최적화된 trace를 불러와 실행
- 만약 trace misprediction이 발생하면 trace에서 빠져나와 상황을 복구
Out-of-Order Execution: Trace 최적화의 대표 사례
Super-scalar 아키텍처의 Out-of-Order Execution은 대표적인 trace 기반 최적화입니다. Out-of-Order engine의 목표는 instruction을 재배열하여 Instruction-Level Parallelism(ILP) 을 극대화하는 것인데, 이를 위해서는 스케줄링 scope이 클수록 유리합니다. 독립적인 instruction을 찾아야 하므로 pool이 클수록 좋기 때문입니다.
문제는 일반적인 프로그램에서 매 56개 instruction마다 branch가 발생한다는 것입니다. Branch가 나타나면 실제로 어느 방향으로 뛸지 모르므로, 그 이후의 instruction을 미리 스케줄링하기 어렵습니다. 결국 branch 사이의 56개 instruction만 보고 ILP를 찾아야 하니 효율이 낮아집니다.
이를 해결하기 위해 Branch Prediction을 out-of-order engine에 결합합니다:
- 확률이 높은 방향으로 trace를 생성하되, branch prediction을 여러 번 반복하여 긴 trace를 구성
- 이 긴 trace를 대상으로 out-of-order execution을 수행하면 성능이 크게 향상
- 만약 prediction이 틀리면(misprediction), Reorder Buffer(ROB)를 통해 rollback. 실제 결과를 commit하기 전에 in-order로 저장해두고, branch 결과가 확정되면 그때 publish
이 구조가 결국 PyTorch 2.0의 Dynamo가 하는 일과 매우 유사합니다. Dynamo도 실행 가능한 trace를 미리 추출하여 최적화하고, 동일한 패턴이 반복되면 이를 활용합니다.
이후 다룰 사례들
이 외에도 trace 기반 최적화의 대표적인 사례로 다음을 다룹니다:
- Trace cache: 반복되는 hot trace를 연속적인 cached blob으로 변환
- Partial evaluation: 사전에 실행 가능한 계산을 미리 처리하여 연산을 제거. PyTorch 2.0의 Dynamo가 수행하는 최적화의 바탕이 되는 개념
- ML compiler의 graph mode: Trace를 통해 실행할 연산자를 식별하고, trace에 대한 partial evaluation으로 Python 코드를 효과적으로 제거
Trace Cache (Pentium 4에 적용된 사례)
Trace Cache는 Instruction Cache + Branch Prediction을 더 최적화한 형태입니다. Branch Prediction이 없으면 분기가 결정되기 전까지 instruction을 미리 fetch할 수 없기 때문에 예측을 수행하는데, 그럼에도 Instruction Cache는 점프가 많아지면 fetch 효율이 떨어지는 문제가 있습니다. Bank conflict가 발생하거나 cache miss로 원하는 데이터가 캐시에 없을 가능성이 높아지기 때문입니다.
Trace Cache는 이를 해결하기 위해 메모리의 비연속적인 구간을 하나의 연속적인 블록으로 묶어 fetch를 최적화합니다. Pentium 4 프로세서에서 최초로 적용되었습니다.


Trace Cache의 동작 방식은 다음과 같습니다:
- 반복되는 구간을 trace로 식별하고, 비연속적인 코드 블록들을 연속적인 메모리 블록으로 변환하여 저장
- Trace의 시작점이 수행될 때 저장된 trace를 한꺼번에 fetch
- Trace miss가 발생하면 trace에서 빠져나와 instruction cache에서 하나씩 fetch
이를 위해 세 가지 하드웨어 장치가 필요합니다:
- Trace Cache: 최적화된 Trace를 저장하는 저장소
- Trace Predictor: Branch predictor와 유사하게, 어떤 Trace가 실행될지 예측하여 선택
- Trace Buffer (outstanding trace buffers): 모든 trace를 곧바로 cache에 넣지 않고, 성능 향상 효과가 클 것 같은 후보를 먼저 모아두고 선별하는 버퍼
아래 그림은 (a) 기존 Instruction Cache와 (b) Trace Cache의 구조적 차이를 비교하여 보여줍니다:
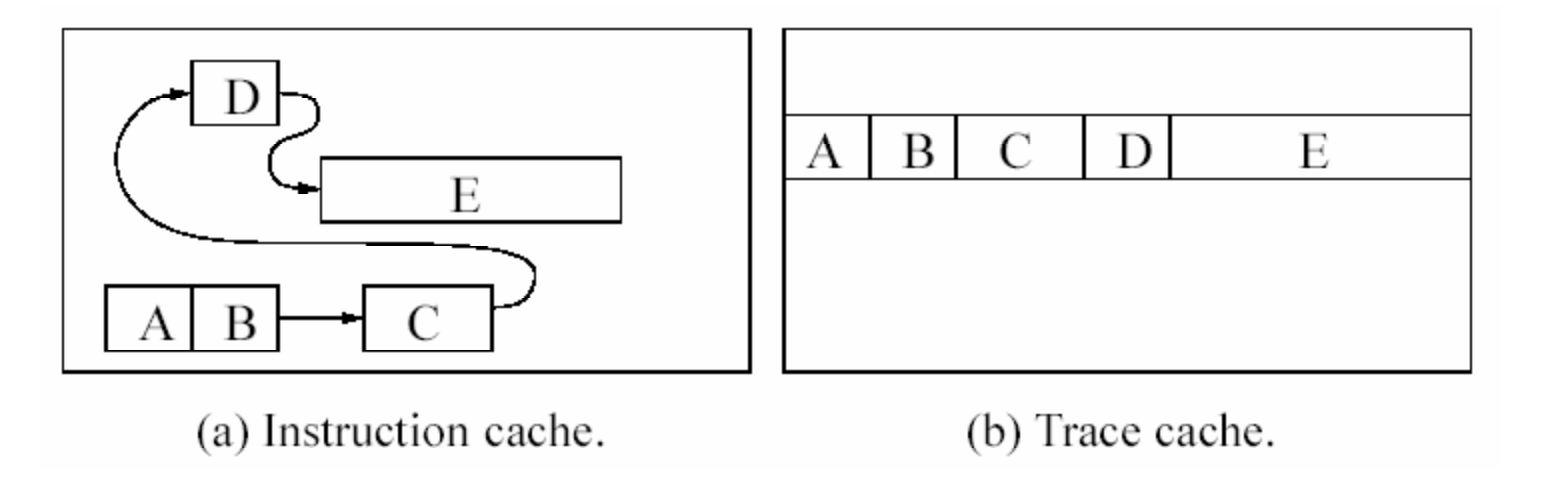
- (a) Instruction Cache: 블록 A, B → C → D → E가 메모리 상에 비연속적으로 배치되어 있어, 점프할 때마다 다른 위치에서 fetch해야 합니다. Cache miss가 발생할 가능성이 높고 fetch 효율이 저하됩니다.
- (b) Trace Cache: 동일한 블록들을 A, B, C, D, E 순서로 하나의 연속적인 trace로 묶어 저장합니다. 한 번에 fetch가 가능하여 성능이 향상됩니다.
이 세 장치가 연결되어 동작하는 흐름은 다음과 같습니다:
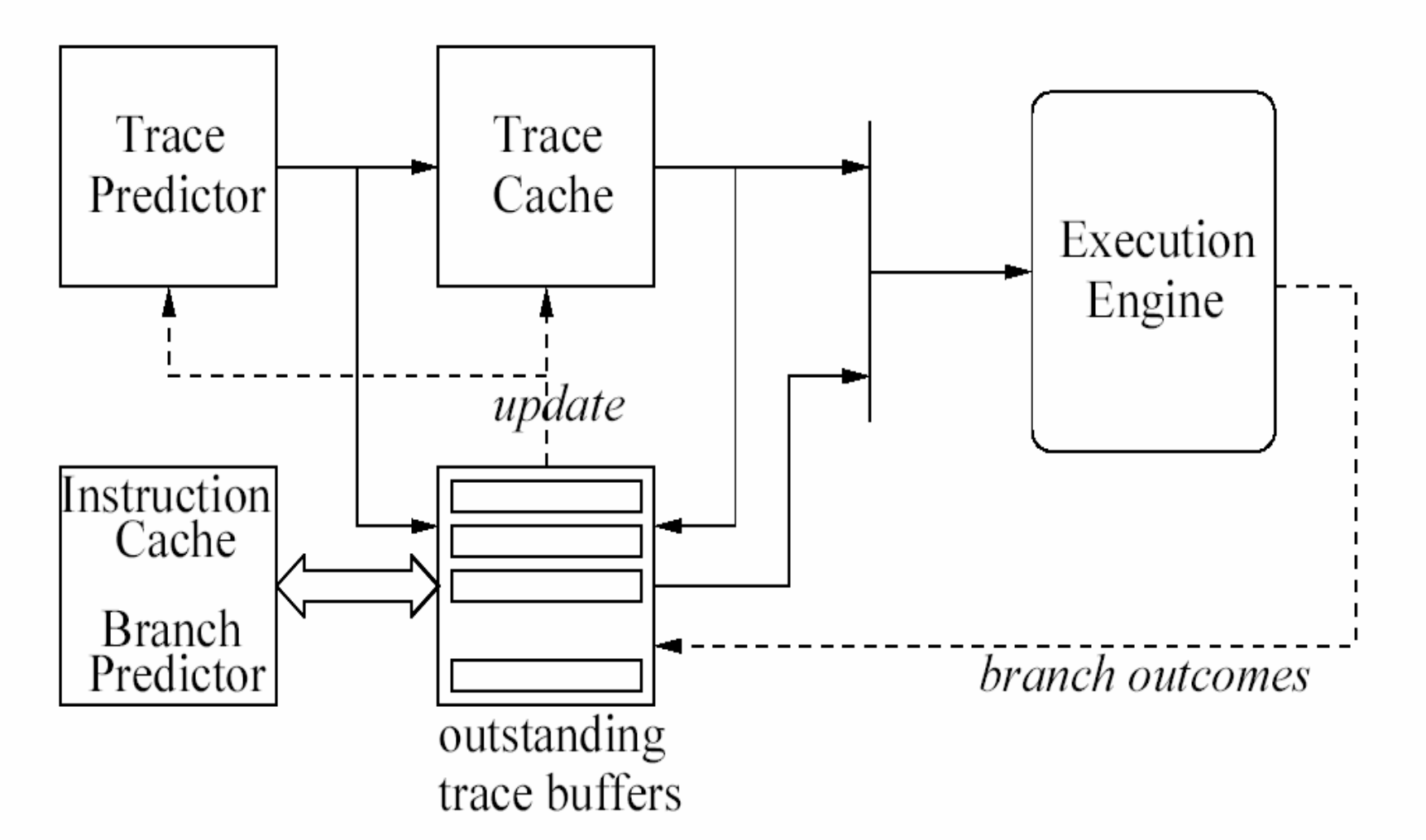
- Trace Predictor가 다음에 실행될 trace를 예측하여 Trace Cache에서 해당 trace를 fetch → Execution Engine에 전달
- Trace Cache에 원하는 trace가 없으면(trace miss), Instruction Cache + Branch Predictor를 통해 instruction을 하나씩 fetch하면서 새로운 trace 후보를 outstanding trace buffers에 수집
- 충분한 trace가 모이면 trace buffer에서 선별하여 Trace Cache를 update
- Execution Engine에서 실제 branch 결과(branch outcomes)가 나오면, 이를 Trace Predictor와 Branch Predictor에 피드백하여 예측 정확도를 개선
결과적으로 Trace Cache는 분기 명령으로 인해 발생하는 명령어 fetch의 불연속성을 완화함으로써 fetch 효율을 높이고, 연속적인 명령어 공급을 가능하게 하여 전체 실행 성능 향상에 기여합니다.
Rotenberg, Eric, Steve Bennett, and James E. Smith. “A trace cache microarchitecture and evaluation.” IEEE Transactions on Computers 48.2 (1999): 111-120. https://ieeexplore.ieee.org/abstract/document/752652
Partial Evaluation
Partial evaluation은 프로그램을 최적화하는 기법으로, 입력을 두 종류로 구분합니다:
- Static Input: 변하지 않는 상수처럼 취급될 입력 (자주 사용되는 고정 값)
- Dynamic Input: 실행 시마다 변할 수 있는 입력
프로그램 p에 고정된 입력 in1(static input)을 주어 부분 평가(partial-evaluate)한 뒤, 동적 입력 in2(dynamic input)에 의해 영향을 받는 나머지 계산만 수행하는 특화된 프로그램(specialized program) 을 생성합니다. 이렇게 생성된 특화 프로그램은 원래 프로그램 p보다 더 빠르게 실행됩니다.
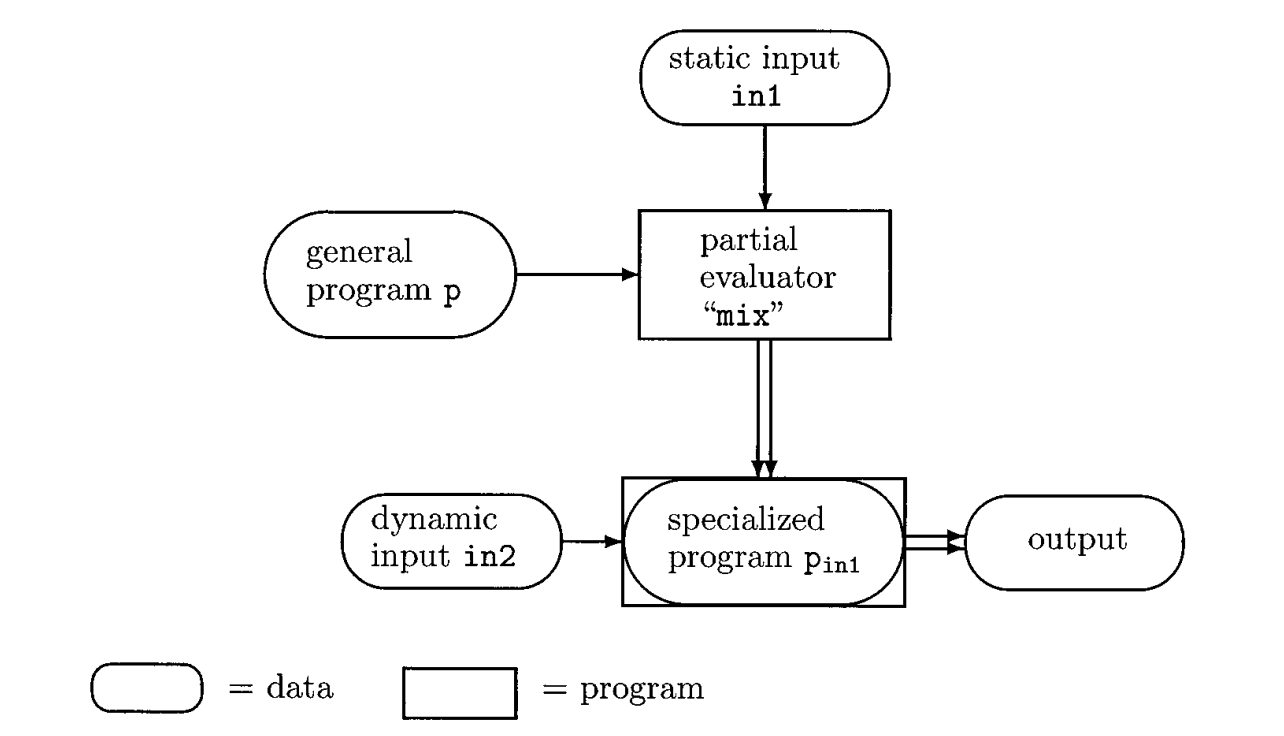
Jones, Neil D. “An introduction to partial evaluation.” ACM Computing Surveys (CSUR) 28.3 (1996): 480-503. https://dl.acm.org/doi/10.1145/243439.243447
예를 들어 x가 항상 고정된 static input이라면:
def compute(x, y):
return (x + 10) * y
# x = 5가 항상 고정이라면, 미리 계산하여 최적화된 함수 생성
def optimized_compute(y):
return 15 * y이처럼 반복적으로 수행되는 복잡한 연산을 미리 계산하여 실행 성능을 높일 수 있습니다.


위 다이어그램은 Partial Evaluation의 핵심 아이디어를 보여줍니다. Partial Evaluation은 static input에만 의존하는 연산을 미리 계산하고, dynamic input에 영향을 받는 부분만 실행합니다. 이를 극단적으로 생각하면, static input이 포함된 연산을 모두 제거하고 dynamic input만 남긴 형태로 최적화할 수 있습니다.
예를 들어 원래 Trace가 [A, A, B, C, D, D, E, E, E]이고 static input과 dynamic input이 모두 필요한 상태에서, static input에만 영향받는 부분을 한 번 계산해두면, 최적화된 Trace에서는 dynamic input만 필요하게 됩니다:
- Static input은 더 이상 필요 없음 - 영향이 이미 반영되었기 때문
- Static input에만 영향을 받는 코드는 다시 계산할 필요가 없음 - 결과가 이미 특화 프로그램에 포함됨
모든 입력 집합이 {i1, i2, ..., in}이라면, 이를 static input과 dynamic input으로 나누는 과정이 필요합니다. 단, 임의로 나눌 수는 없고 실제 실행 중 바뀌지 않는 값만 static input으로 설정해야 효과적입니다. Static input이 바뀌면 최적화된 Trace도 달라져야 하므로 새로운 partial evaluation이 필요하고, 잘못된 static input을 적용하면 예상과 다른 결과가 나올 수 있습니다.
PyTorch 2.0과의 연관성: Dynamo는 Partial Evaluation과 유사한 방식으로 동작합니다. 변하지 않는 연산(Python 코드, tensor shape 등)을 미리 계산하여 최적화된 Graph를 생성하고, 변하는 부분(실제 tensor 데이터)만 실행 시 처리합니다.
ML 모델에서의 Tracing
Python으로 작성된 ML 모델에 tracing을 적용하면 여러 이점이 있습니다.
Device 실행 분리: Python으로 작성된 복잡한 일반 코드는 GPU/NPU에서 직접 가속이 거의 불가능합니다. 따라서 device에서 효과적으로 실행 가능한 부분을 분리하는 것이 중요한데, tracing이 이를 위한 실용적인 방법입니다. 정적 분석 등을 생각해 볼 수 있으나 너무 복잡하고 실용적이지 않습니다. 이는 앞서 다룬 partial evaluation과 같은 맥락으로, 불필요한 부분(Python 코드)을 제거하여 실행 효율을 높이는 것입니다.
Tensor shape 판별: 단순히 trace를 추출하는 것을 넘어, tracing 과정에서 수행에 필요한 tensor의 shape들을 판별할 수 있습니다. 이는 다음과 같은 이유로 중요합니다:
- NPU/GPU의 메모리 레이아웃 최적화에 필수적
- 계산 크기에 따른 스케줄링 결정에 중요
- 컴파일 시 메모리 사용량과 실제 계산 수행 방식을 예측 가능
Graph 최적화: 전체 계산 흐름을 파악할 수 있으므로, Python 레벨에서는 어려운 종합적인 최적화를 trace 레벨에서 구현할 수 있습니다. 대표적인 최적화 기법으로는 Op Fusion, Constant propagation, Common subexpression elimination 등이 있습니다.
Python 기초: CPython 동작 방식
Python 코드가 실행되면 CPython이 소스 코드를 bytecode로 변환하고, 이 bytecode를 VM의 evaluation loop에서 실행합니다. 이때 interpreter가 실행하는 bytecode instruction 하나하나를 기록하면 그것이 곧 trace입니다. 즉, Python 프로그램의 trace를 뽑아내는 것 자체는 개념적으로 그렇게 어려운 일이 아닙니다. 하지만 모든 bytecode 실행을 기록하면 과도하게 긴 trace가 생성되고 오버헤드가 크기 때문에, 최적화 없이 이 방식을 그대로 사용하는 것은 비효율적입니다.
CPython의 동작 방식을 조금 더 자세히 들여다보겠습니다.
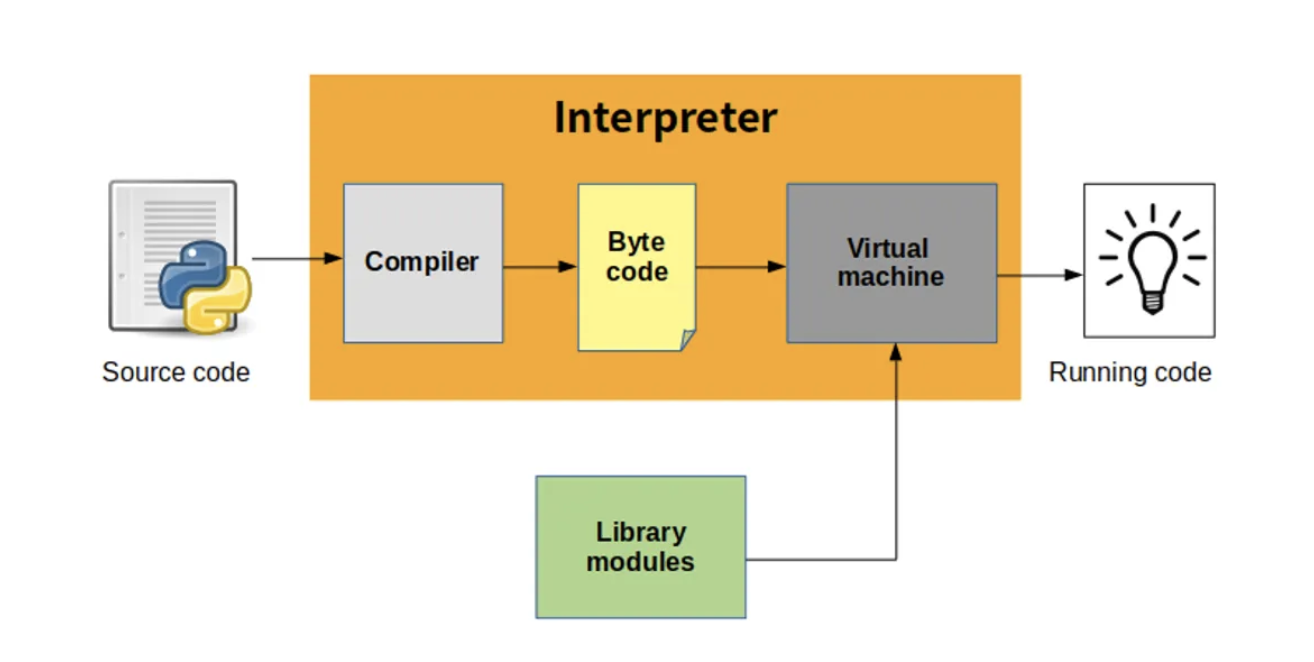
CPython의 기본 동작은 다음과 같습니다:
- CPython을 초기화
- 소스 코드를 code object로 컴파일 (compiler)
- Code object 내의 bytecode를 실행 (virtual machine)
즉, Python 소스 코드가 입력되면 이를 bytecode로 변환하고, VM의 evaluation loop에서 bytecode instruction을 하나씩 실행합니다. 이때 실행되는 instruction을 순서대로 기록하면 그것이 곧 trace가 됩니다.
Python VM 구조
Dynamo 자체가 CPython에 직접 integration 되어 있기 때문에, Python VM의 구조를 이해하는 것이 중요합니다. Python VM은 다음과 같은 계층 구조로 이루어져 있습니다 (아래에서 위로):
- Evaluation loop - code object에 들어 있는 bytecode를 스트리밍 방식으로 하나씩 읽어 실행하는 루프
- Frame - 함수 단위로 관리되는 데이터 구조(per-function data structure). 각 함수 호출 시 새로운 frame이 생성되며, frame 내부에 code object와 evaluation loop이 존재
- Call Stack - 여러 개의 frame이 쌓여 함수 호출 관계를 관리. 함수 호출 시 새로운 frame이 추가되고, 종료 시 제거됨
- Thread - 각 thread는 독립적인 call stack을 가짐. Python은 멀티스레딩을 지원하므로 여러 thread가 존재 가능
- Interpreter - 여러 thread가 모여 하나의 Python interpreter를 구성. 공유 데이터(예: imported modules)를 관리
- Runtime - VM의 global state
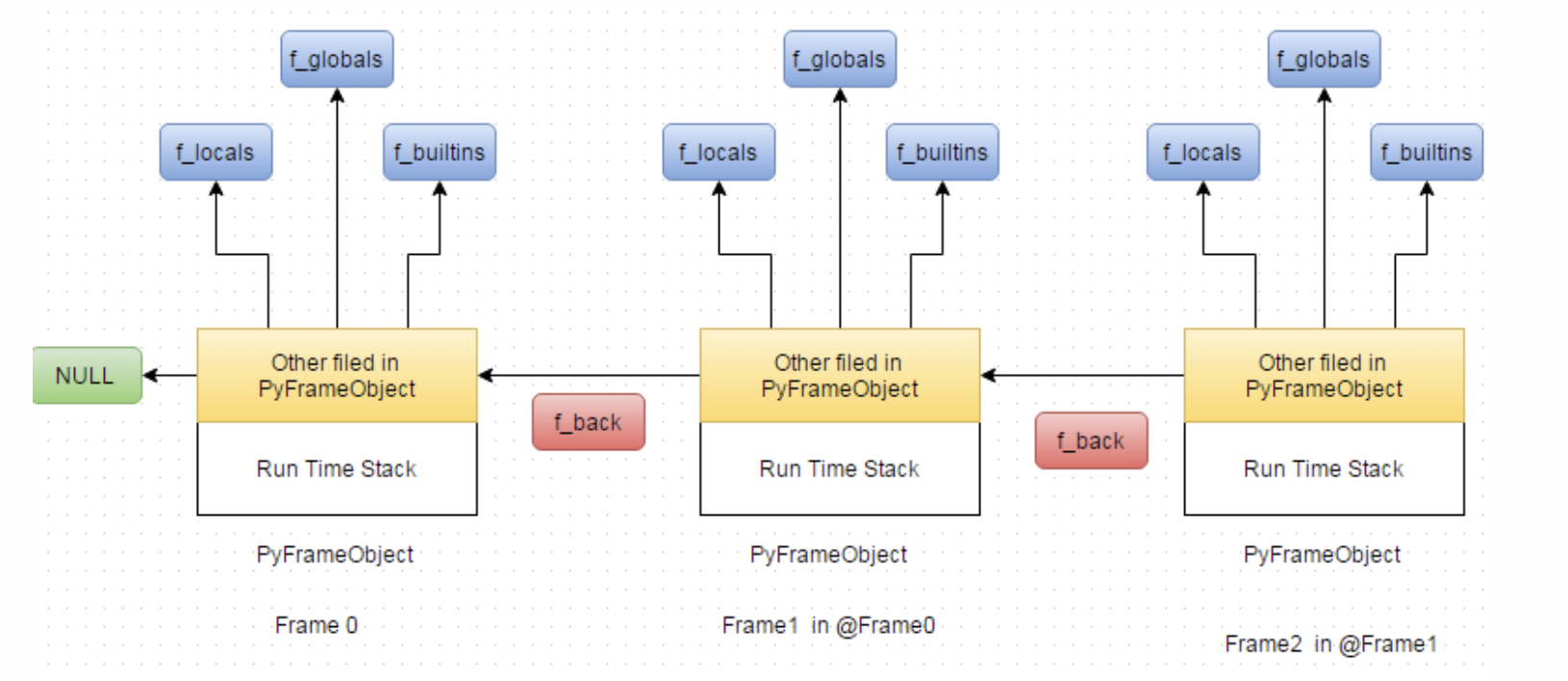
참고: https://jasonleaster.github.io/2016/02/21/architecture-of-python-virtual-machine/
위 그림처럼 call stack은 frame object의 linked list로 표현됩니다. 이론적으로는 evaluation loop에서 실행되는 bytecode를 모두 기록하면 end-to-end trace를 생성할 수 있습니다.
PyTorch의 Tracing 방식 발전
앞서 살펴본 것처럼, bytecode stream을 그대로 기록하는 방식은 비효율적입니다. PyTorch는 이보다 더 효율적인 tracing 방식을 여러 차례 시도해 왔으며, 1.0과 2.0의 주요 기술을 차례로 따라가 보겠습니다.
| 버전 | 방식 | 핵심 접근 | 장점 | 단점 |
|---|---|---|---|---|
| 1.0 | jit.trace | Dispatcher에 trace collect kernel 부착 | 구현이 간단, 실무에서 널리 사용 | 특정 입력에 의존, dynamic branch 미지원 |
| 1.0 | jit.script | Python subset 전용 interpreter | 제어 흐름 분석 가능 | subset 외 코드 처리 불가, 포기하는 경우 빈번 |
| 2.0 | Dynamo | CPython에 직접 통합, bytecode 수준 tracing | 전체 Python 지원, guard로 입력 의존성 검증, 자동 분할 | graph break/재컴파일 및 guard 검사 오버헤드 |
PyTorch 1.0: jit.trace와 jit.script
jit.trace: Dispatcher를 활용한 간단한 Tracing
Eager Mode에서 배운 Dispatcher를 활용한 방식입니다. Dispatcher의 dispatch key에 따라 다른 kernel을 실행할 수 있다는 점을 이용하여, 실제 Op을 수행하는 대신 trace만 collect하는 kernel을 붙여놓은 것이 jit.trace입니다.
- 프로그램이 실행되면 Python 세계에서 일어난 모든 일은 무시
- Device에서 실행될 Op들만 모아서 trace를 생성
- Partial Evaluation 관점에서, tensor 연산은 dynamic input이고 Python 코드의 제어 흐름은 static input이라고 가정
jit.script: Python subset 전용 Interpreter
jit.trace의 한계를 보완하기 위해 도입된 기술입니다. Partial evaluator와 유사하게 동작하되, Python 전체가 아닌 subset만 처리할 수 있는 별도의 interpreter를 사용합니다. 하지만 “popular할 것 같은 subset”을 넘어가는 프로그램이 실제로는 매우 많아, 처리하지 못하고 포기하는 경우가 빈번했습니다.
실무에서는 오히려 jit.trace가 더 널리 사용되었습니다. 프로그래머가 코드를 작성할 때 static/dynamic input을 잘 구분하여 설계하면, jit.trace로도 안전하게 tracing할 수 있기 때문입니다.
jit.trace의 한계
jit.trace의 핵심 전제는 “tensor 연산은 dynamic input, Python 제어 흐름은 static input”이라는 가정입니다. 하지만 이는 검증 없는 가정일 뿐입니다.
아래 코드에서 dynamic input인 x의 평균값에 따라 if문의 분기가 달라집니다. 특정 입력으로 trace를 생성하면, 다른 입력에서는 잘못된 경로를 실행하게 됩니다.
def function(inputs):
x = inputs["x"]
y = inputs["y"]
x = x.cos().cos()
if x.mean() > 0.5:
x = x / 1.1
return x * y- Trace 안전성 없음: dynamic input(
x)의 값에 따라 조건문의 실행 경로가 달라지므로, 한 입력에서 생성한 trace를 다른 입력에 재사용할 수 없음 - 근본 원인:
jit.trace는 input이 static한지 dynamic한지를 분석하지 않고, 단순히 가정만 함. 연산 자체는 문제가 없으며, input이 static했는지 아닌지에 따라 trace의 안전성이 결정됨 - 이 문제는 앞서 다룬 “입력에 따라 trace가 달라지는” 문제와 정확히 동일
Q:
jit.trace나jit.script로 직접 최적화할 부분을 지정해서 커널 퓨전을 했는데, PyTorch 버전 업그레이드로 Dynamo를 지원하면서 학습 throughput이 크게 올랐습니다. Dynamo는 알아서 최적화를 해주는 느낌인데, 이렇게 이해해도 될까요?A:
jit.trace나jit.script자체는 최적화를 해주지 않습니다. Trace를 뽑아주는 역할만 하고, 최적화는 별도입니다. Dynamo의 경우 자동화된 최적화 백엔드와 결합하여 동작합니다. Throughput 향상은 Dynamo가 tracing할 수 있는 범위가 더 넓어서 추가 최적화가 가능했거나, trace에 적용되는 최적화 수준 자체가 더 높았기 때문일 수 있습니다.
Q: Dynamo가 CPython과 통합됐다는 것이 CPython의 플러그인 형태로 동작하는 건가요?
A: 비슷하게 생각할 수 있습니다. CPython의 원래 기능을 오버라이드하고 확장하여 구현한 것으로, CPython의 VM 실행 컨텍스트 자체에 붙어서 추가 작업을 수행하는 방식입니다. 이에 대해서는 뒤에서 더 자세히 다룹니다.
PyTorch 2.0: Dynamo
jit.trace와 jit.script 모두 근본적인 한계가 있었기 때문에, PyTorch 2.0에서는 이를 한 번에 해결하기 위해 Dynamo를 도입했습니다.
Dynamo의 핵심 차별점은 별도의 interpreter를 만든 것이 아니라, CPython에 직접 통합하여 bytecode 수준에서 end-to-end trace를 생성한다는 점입니다. 이를 통해:
- Python 전체 언어를 지원 (
jit.script의 subset 문제 해결) - Guard로 입력 의존성을 검증하고, 조건이 달라지면 재컴파일하는 안전한 tracing (
jit.trace의 검증 없는 입력 의존 문제 해결) - Trace 불가능한 구간을 자동으로 식별하고 분할하여 안전성 확보
Dynamo의 동작 원리
Concept
프로그램의 실행을 끝까지 따라가면 하나의 linear한 trace가 생성됩니다. 하지만 이 긴 trace 중 일부 구간은 dynamic input에 따라 다른 동작을 할 수 있어, static한 behavior가 보장되지 않습니다. Dynamo는 이러한 trace 불가능한 구간(graph break 지점)을 식별하여, 그 부분을 제외한 나머지를 여러 개의 안전한 trace로 분할합니다.


위 다이어그램에서 색칠된 부분이 trace 불가능한 graph break 지점이고, 나머지 구간이 각각 하나의 trace가 됩니다. 분할된 trace들은 다음과 같은 방식으로 실행됩니다:
- Trace 진입 전, 현재 상태가 해당 trace를 수행할 수 있는 조건을 만족하는지 Guard로 검사
- 조건이 만족되면, 해당 trace에 대해 최적화된 compiled function을 호출
- Trace가 끝나면 (graph break 지점까지만 실행), tracing 불가능한 구간을 원래 방식으로 실행
- 이후 다음 trace 진입 시, 다시 Guard로 조건을 확인하고 최적화된 trace를 활용
이 trace를 찾아가는 과정 자체가 recursive합니다. Graph break 지점까지 trace를 수행하고, 최적화된 코드를 생성한 뒤, 다시 시작할 수 있는 지점을 찾아 새로운 trace 탐색을 시작합니다.
CPython과의 통합
앞서 언급했듯 Dynamo는 CPython 자체에 integration되어 동작합니다. 아래 그림의 왼쪽이 Python의 기본 동작, 오른쪽이 Dynamo가 이를 확장한 모습입니다:
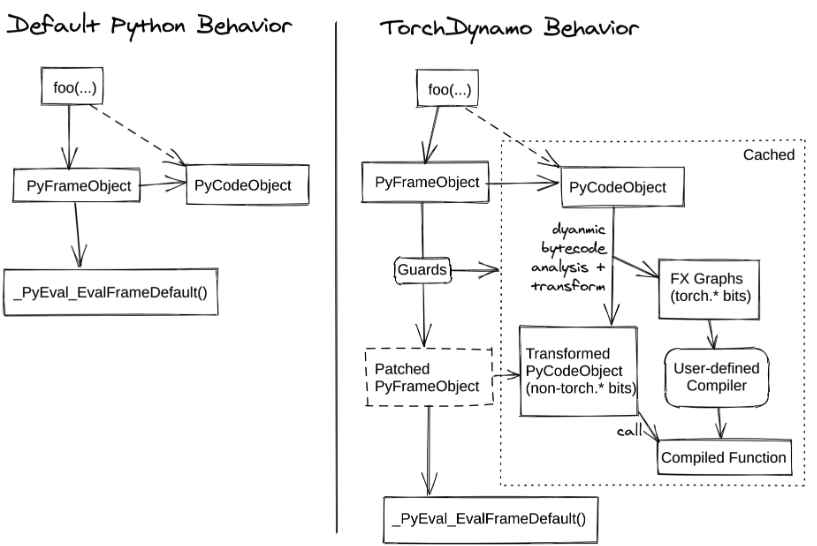
참고 1: https://docs.pytorch.org/docs/stable/user_guide/torch_compiler/torch.compiler_dynamo_overview.html
Python의 기본 동작 (왼쪽):
- 함수가 호출되면 새로운 frame object가 생성
- Frame 내부의 code object는 이미 컴파일되어 있으므로 바로 실행 가능
- Evaluation loop이 code object의 bytecode를 해석하며 함수 실행
Dynamo의 동작 (오른쪽):
- 함수
foo를 만나면 frame object를 만드는 것까지는 동일 - 해당 함수가 이전에 tracing된 적이 없으면, frame에 붙어 있는 code object의 bytecode를 분석하여 tracing을 시도
- Function call과 return을 따라가면서 graph break가 나올 때까지 추적한 뒤, 최적화된 코드를 생성
Dynamo는 CPython 소스를 수정하는 대신, CPython이 제공하는 frame evaluation API(PEP 523) 를 이용해 C 확장에서 frame 실행 함수를 교체하는 방식으로 구현되어 있습니다. 덕분에 CPython 내부 코드를 수정할 필요 없이 frame 단위로 개입하여 bytecode를 분석하고 변환할 수 있습니다.
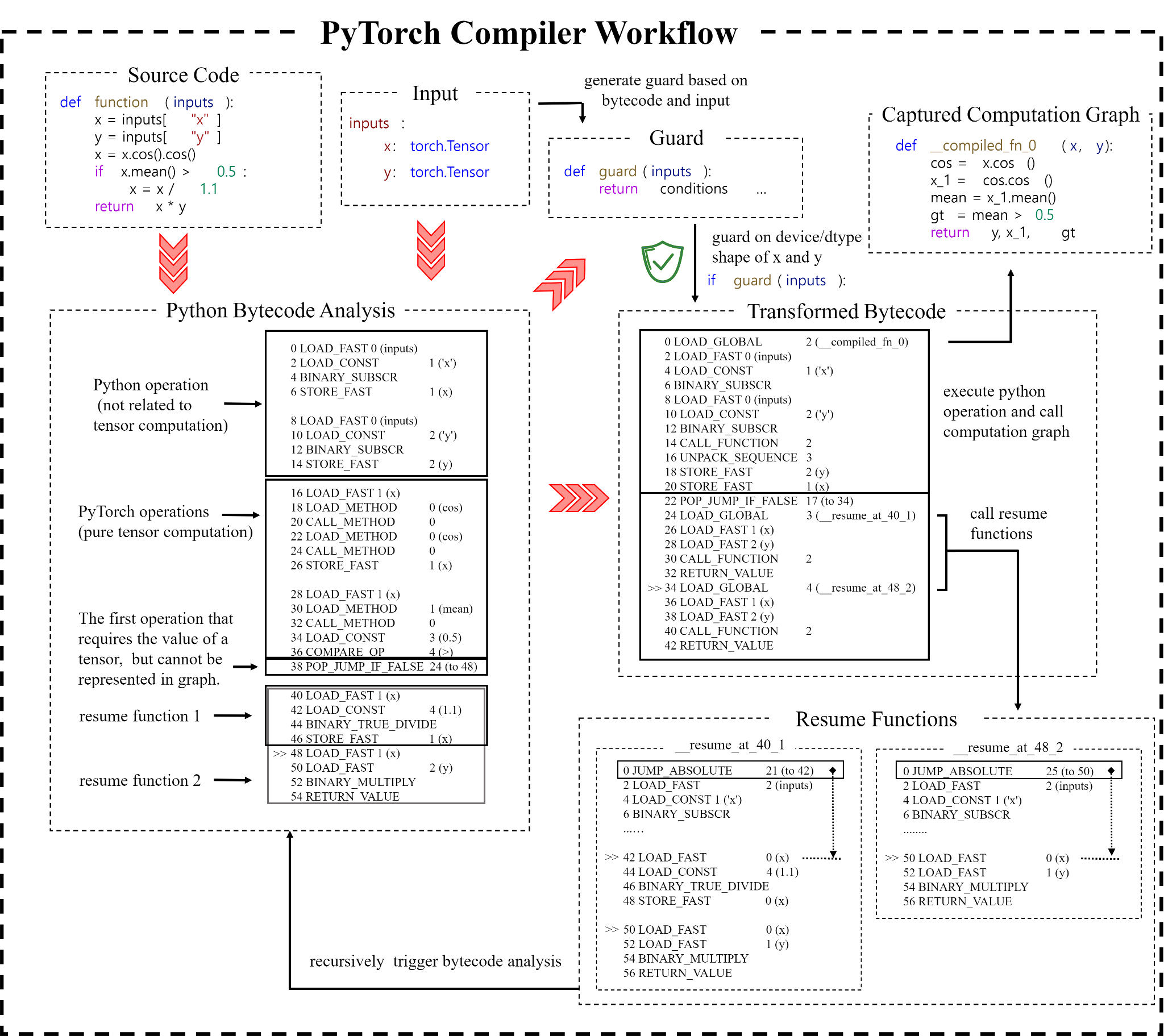
참고: https://depyf.readthedocs.io/en/latest/walk_through.html
위 다이어그램이 Dynamo의 내부 흐름입니다. Bytecode analysis → bytecode transformation → FxGraph construction → user-defined compilation → guard insertion의 과정을 거칩니다.
Trace 생성 과정
지금까지의 내용을 Trace Generation 관점에서 정리합니다.
입력: 실행할 bytecode와 처리할 input. Tensor는 dynamic input, 그 외는 static input으로 가정합니다.
생성: bytecode와 input을 가지고 graph break가 발생할 때까지 실행을 추적하여 trace를 생성하고, bytecode transformation을 수행하여 최적화된 코드를 caching합니다.
Caching된 최적화 코드의 구성 요소:
- Guard (static input 검증 로직) - 이전에 기록된 trace를 재사용할 수 있는지 확인
- Captured FX Graph - 실행할 최적화된 연산 그래프
- Transformed bytecode - FX Graph를 호출하는 bytecode와, 다음 코드로 넘어가기 위한 부분 포함
- Resumed functions - graph break 이후 실행을 재개할 함수. Branch에서 break가 발생한 경우, 분기에 따라 여러 개의 continuation이 존재할 수 있음
Graph break 이후, resumed function의 bytecode를 가지고 위의 과정을 recursive하게 반복합니다.
Trace Generation의 결과물
특정 function의 frame 안에서 trace가 수행되며, 그 결과물은 다음과 같은 구조입니다:


- Guard 검사 - 조건을 만족하면 cache된 결과물을 사용, 만족하지 않으면 fallback
- Python bytecode 실행 - captured FX Graph에 대한 계산 수행이 핵심
- Graph break 이후 처리 - trace되지 못한 부분을 실행
- Resume function 호출 - 실행을 재개할 함수가 선택되고, 해당 함수에 대해 새로운 frame이 만들어지면서 동일한 과정을 반복
Trace Replay
동일한 함수가 다시 호출되면, Dynamo는 Guard를 통해 이전 trace를 재사용할 수 있는지 확인합니다.
- Guard 통과 (static input 불변) → cache된 transformed bytecode를 재활용하여 최적화된 코드 실행
- Guard 실패 (static input 변경) → recompilation이 trigger되어 새로운 trace를 생성
IR Lowering
PyTorch 2.0에서 크게 개선된 부분 중 하나가 IR들이 lowering되는 과정을 체계적으로 설계한 것입니다. Dynamo에서 생성된 FxGraph는 여러 단계의 IR lowering을 거쳐 최종적으로 백엔드에서 실행됩니다:
1. Dynamo → FxGraph (Torch IR)
Dynamo가 생성하는 FX Graph는 Torch IR로 표현되며, 비교적 상위 레벨의 추상화로 되어 있습니다. Lowering이 많이 이루어지지 않은 상태입니다.
2. AOT Autograd → FxGraph (Aten/Prims IR)
Gradient 계산이 필요할 경우 이 단계에서 처리합니다. 필요하지 않다면 이 과정을 생략할 수도 있습니다. 통과하면 동일하게 FX Graph가 출력되지만, Torch IR이 보다 구체화된 Aten IR 또는 Prims IR 형태로 lowering됩니다.
3. Inductor → Loop-Level IR
Lowering된 IR을 받아 Inductor의 Loop-level IR로 변환합니다. 이 과정에서 fusion 같은 최적화 작업이 이루어지며, 최종적으로 선택한 백엔드에 전달됩니다.
4. Triton (Backend)
백엔드는 전달받은 low-level IR을 백엔드 특화된 device representation으로 변환하여 실행합니다.
Torch IR, Aten, Core Aten, and Prims IR
PyTorch의 IR 체계는 상위에서 하위로 단계적으로 lowering되는 여러 계층으로 나뉩니다:
- Torch IR - Python 코드 수준에서 보이는 모든 연산자(operators)가 포함된 가장 상위 레벨의 IR. PyTorch이 지원하는 2,000개가 넘는 연산자에 해당
- Aten IR - Torch IR을 약 750개의 canonical한 연산자로 정리한 IR. 기존에 이미 PyTorch를 지원하고 있는 backend가 사용 (Intel CPU, NVIDIA GPU 등)
- Core Aten IR - Aten에서 더 작고 표현이 간결한 subset으로 정리한 약 250여개의 operations. 반드시 저수준의 ops를 의미하는 것은 아니며, avgpool2d, convolution 등의 high-level ops도 포함
- Prims IR - Core Aten과 비슷하지만, 타입 정보와 broadcasting을 명시적으로 표현하여 백엔드로 직접 전달할 수 있도록 변환된 형태. 약 250여개의 primitives
아래 코드는 이 lowering에 사용되는 decomposition table을 구성하는 예시입니다:
decomp_table = torch._decomp.get_decompositions([
torch.ops.aten.hardtanh,
torch.ops.aten.clamp,
torch.ops.aten.isnan,
torch.ops.aten.ge,
torch.ops.aten.bitwise_or,
torch.ops.aten.scalar_tensor,
torch.ops.aten.where,
torch.ops.aten.le,
])이 lowering 과정은 AOT Autograd가 수행하며, decomposition table을 활용하여 연산을 변환합니다. Decomposition table에는 target 연산들의 구성으로 변환 규칙이 정의되어 있으며, 기본 변환(default)을 사용할 수도 있고 필요에 따라 직접 구성할 수도 있습니다.
Device Backend 통합
사용자 관점
모델을 생성한 뒤 torch.compile(model)을 호출하면 컴파일된 모델이 반환됩니다. 단, 이 시점에서 실제 컴파일이 수행되는 것은 아닙니다. 컴파일 의도가 반영된 모델이 생성되며, 실제 컴파일은 모델 실행 시 수행됩니다.
import torch
class MyModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(100, 10)
def forward(self, x):
return torch.nn.functional.relu(self.linear(x))
my_model = MyModule()
# 이 줄만 추가하면 graph mode로 동작
# -> additive feature라 eager mode 동작에 영향을 주지 않음
my_model = torch.compile(my_model)
my_input = torch.randn(10, 100)
# 실제 컴파일은 첫 번째 실행에서 이루어진다
forward_output = my_model(my_input)모델을 실행하면 Dynamo가 동작하여 trace를 생성하고, 등록된 backend가 호출되면서 컴파일이 수행됩니다. 첫 번째 실행 시에는 tracing과 compilation이 동시에 진행되어 오버헤드가 있을 수 있지만, 두 번째 실행부터는 cache된 컴파일 결과를 재활용하여 compilation overhead 없이 최적화된 코드가 실행됩니다.
Custom Backend 추가
Custom backend를 등록하려면 Backend Object를 생성하고 function을 구현하여 등록합니다. FX Graph가 생성되면 해당 backend가 호출되어 컴파일을 수행하고, 결과를 runtime에서 실행하도록 설정합니다.
# graph_module: torch.fx.GraphModule
# example_inputs: List[torch.Tensor]
def my_backend(graph_module, example_inputs):
# graph_module은 FX graph
my_compiled_model = my_compiler(graph_module)
my_runtime_callable = MyRuntime()
my_runtime_callable.set_model(my_compiled_model)
return my_runtime_callable
model = torch.compile(my_model, backend=my_backend)
# 런타임에 실제 컴파일 수행
forward_output = model(input)위 예제에서는 Inductor가 아닌 사용자 정의 backend를 Dynamo의 backend로 등록한 것입니다. Inductor를 backend로 선택하는 것도 가능하며, 별도의 backend를 붙여서 수행하는 것도 가능합니다.
Q&A
IR Lowering 관련
Q: 상위와 하위 IR을 구분하는 이유는 무엇인가요?
A: 컴파일러에서 일반적으로 사용하는 접근 방식입니다. 상위 레벨에서 다양한 기능을 제공하는 Op들을 제한된 Op들의 조합으로 표현하는 것이 lowering입니다. 예를 들어 Torch IR의 수천 개 Op이 Prims까지 내려가면 약 250개로 추려집니다. Op의 총 개수는 많을 수 있지만 구성하는 set 자체는 줄어들고, 개별 Op도 구체적이고 단순해집니다. 결과적으로 backend compiler는 제한된 수의 단순한 Op만 구현하면 됩니다.
Q: ATen IR과 Core ATen IR의 관계는?
A: 둘 다 device-independent한 공통 IR입니다. ATen IR 자체가 750개 이상으로 수가 많기 때문에, 그 아래로 더 내려가기 위해 Core ATen이라는 추가 lowering 단계를 거칩니다.
Q: IR들은 모두 device-dependent한가요?
A: 아닙니다. Prims 단계까지는 device-independent합니다. 이후 특정 디바이스(NPU, CUDA 등)에 맞춰 변환됩니다.
Q: Op을 줄이는 과정이 CISC → RISC 과정과 유사한가요?
A: Intel이 CISC를 구현할 때 내부적으로 RISC에 해당하는 micro-ops로 명시적으로 쪼갠 뒤 수행했던 방식과 상당히 유사합니다.
Dynamo 및 실행 관련
Q: 모델 실행 시 최적화는 어떻게 이루어지나요?
A: 첫 번째 실행 시에는 tracing과 compilation이 동시에 진행되어 오버헤드가 있을 수 있습니다. 이후 cache가 저장되면, recompilation이 없는 한 compilation overhead 없이 최적화된 코드가 실행됩니다.
Q: MyRuntime은 어떤 용도인가요?
A: CUDA, NPU 등 특정 디바이스에서 코드를 실행하기 위한 환경을 셋업하고 제공하는 런타임입니다.
Q: Bytecode static analysis와 tracing의 구분은?
A: Tracing은 전체 과정을 추상적으로 표현한 것이고, bytecode static analysis는 tracing의 일부 과정에 해당합니다.
Q: TorchDynamo는 Python에서만 사용되나요?
A: TorchDynamo의 상당히 많은 부분이 Python으로 작성되어 있습니다.
Q: 예제의 backend는 Inductor의 backend인가요?
A: 아닙니다. 이 예제에서는 Inductor를 사용하지 않고, 직접 구현한 function이 Dynamo의 backend 역할을 합니다. Inductor를 backend로 선택하거나, 별도의 backend를 붙이는 것도 가능합니다.